
Die KI-Entwicklung schläft nicht – und der Januar 2026 beweist das eindrucksvoll. Während wir uns bisher oft zwischen Geschwindigkeit und Qualität entscheiden mussten, brechen die neuesten Forschungsarbeiten diese Barrieren nieder. Von Echtzeit-Avataren, die auf normalen GPUs laufen, über Agenten, die 2D-Bilder in physikalisch korrekte 3D-Blender-Szenen verwandeln, bis hin zu kompakten 1-Milliarden-Parameter-Modellen, die gigantische OCR-Systeme schlagen: Wir erleben eine Ära der extremen Effizienz und präzisen Kontrollierbarkeit.
In diesem Deep Dive analysieren wir die bahnbrechendsten Papers und Projekte der Woche. Wir werfen einen technischen Blick unter die Haube von FlowAct-R1, VIGA, OmniTransfer und weiteren Innovationen, die die Grenzen dessen verschieben, was mit generativer KI möglich ist.
FlowAct-R1: Der Heilige Gral der Echtzeit-Interaktion
Bisherige Videogenerierungsmodelle litten oft unter einem fundamentalen Trade-off: Entweder war die Qualität hoch, aber die Generierung dauerte Minuten (nicht echtzeitfähig), oder sie waren schnell, aber die Bewegungen wirkten roboterhaft und repetitiv. FlowAct-R1 ändert dieses Paradigma grundlegend. Es handelt sich um ein Framework für interaktive humanoide Videogenerierung, das flüssige 25 FPS bei 480p-Auflösung mit einer Latenz von nur ca. 1,5 Sekunden erreicht.
Die Architektur: MMDiT und Chunkwise Diffusion
Das Herzstück von FlowAct-R1 ist eine MMDiT-Architektur (Multimodal Diffusion Transformer). Anders als reine Text-zu-Video-Modelle muss FlowAct-R1 kontinuierlich auf Audio-Eingaben (z.B. Sprache) und visuelle Referenzen reagieren.
Das größte Problem bei langen generierten Videos ist normalerweise das "Error Accumulation" – kleine Fehler schaukeln sich auf, bis das Gesicht entstellt wirkt. FlowAct-R1 löst dies durch eine innovative Chunkwise Autoregressive Diffusion Forcing-Strategie.
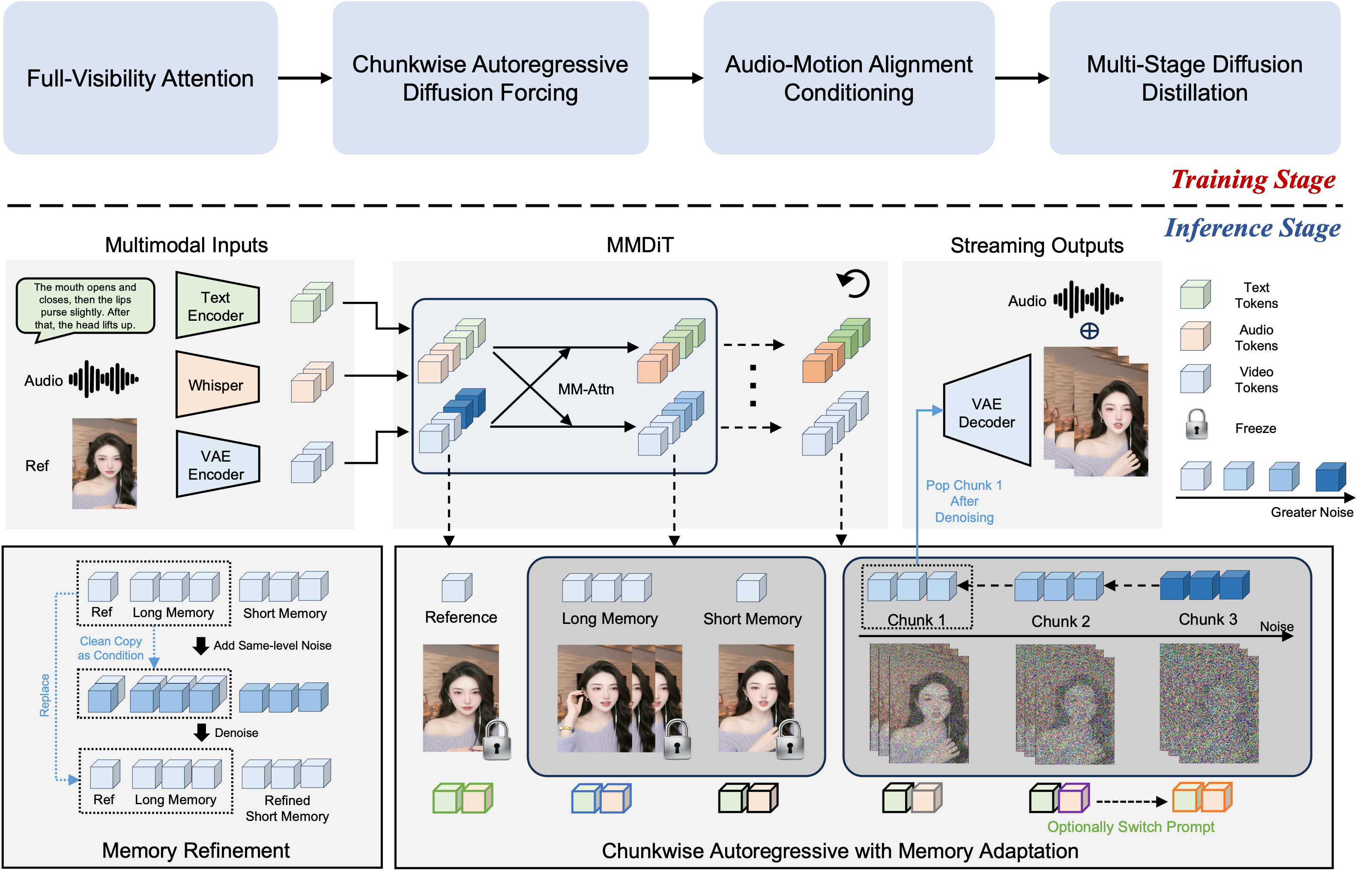
Wie in Abbildung 2 zu sehen ist, nutzt das System eine ausgeklügelte Speicherhierarchie (Long Memory & Short Memory). Anstatt jedes Frame isoliert zu betrachten, "erinnert" sich das Modell an die visuellen Merkmale der Referenzperson und den bisherigen Gesprächsverlauf. Dies ermöglicht Livestreams, die theoretisch unendlich lange laufen können, ohne dass die visuelle Qualität degradiert – ein massiver Fortschritt gegenüber Modellen wie OmniHuman oder LiveAvatar.
OmniTransfer: Copy & Paste für die Realität
Während FlowAct-R1 auf Avatare spezialisiert ist, zielt OmniTransfer auf die universelle Videobearbeitung ab. Die Prämisse ist gewagt: Man nehme ein Referenzvideo und übertrage beliebige Aspekte davon auf ein Zielvideo. Das kann der visuelle Stil, eine spezifische Kamerabewegung, ein VFX-Effekt oder sogar die Bewegung eines Charakters sein.

Technisch realisiert OmniTransfer dies durch "Reference-decoupled Causal Learning". Anstatt Referenz und Ziel in einem undurchsichtigen Latent Space zu vermischen, trennt das Modell die Informationsflüsse. Ein Task-aware Positional Bias hilft dem Modell zu verstehen, was genau übertragen werden soll (z.B. "nur die Kamerabewegung" vs. "nur der Gesichtsausdruck"). Dies macht es zu einem der mächtigsten Werkzeuge für VFX-Artists, da komplexe Effekte (wie der brennende Hand-Effekt im Beispiel) ohne manuelle Simulation übertragen werden können.
VIGA: Wenn die KI Blender lernt
Der vielleicht faszinierendste Ansatz der Woche kommt aus dem Bereich der "Inverse Graphics". VIGA (Vision-as-Inverse-Graphics Agent) ist kein reiner Pixel-Generator. Anstatt ein Bild zu "malen", schreibt dieser Agent Code.
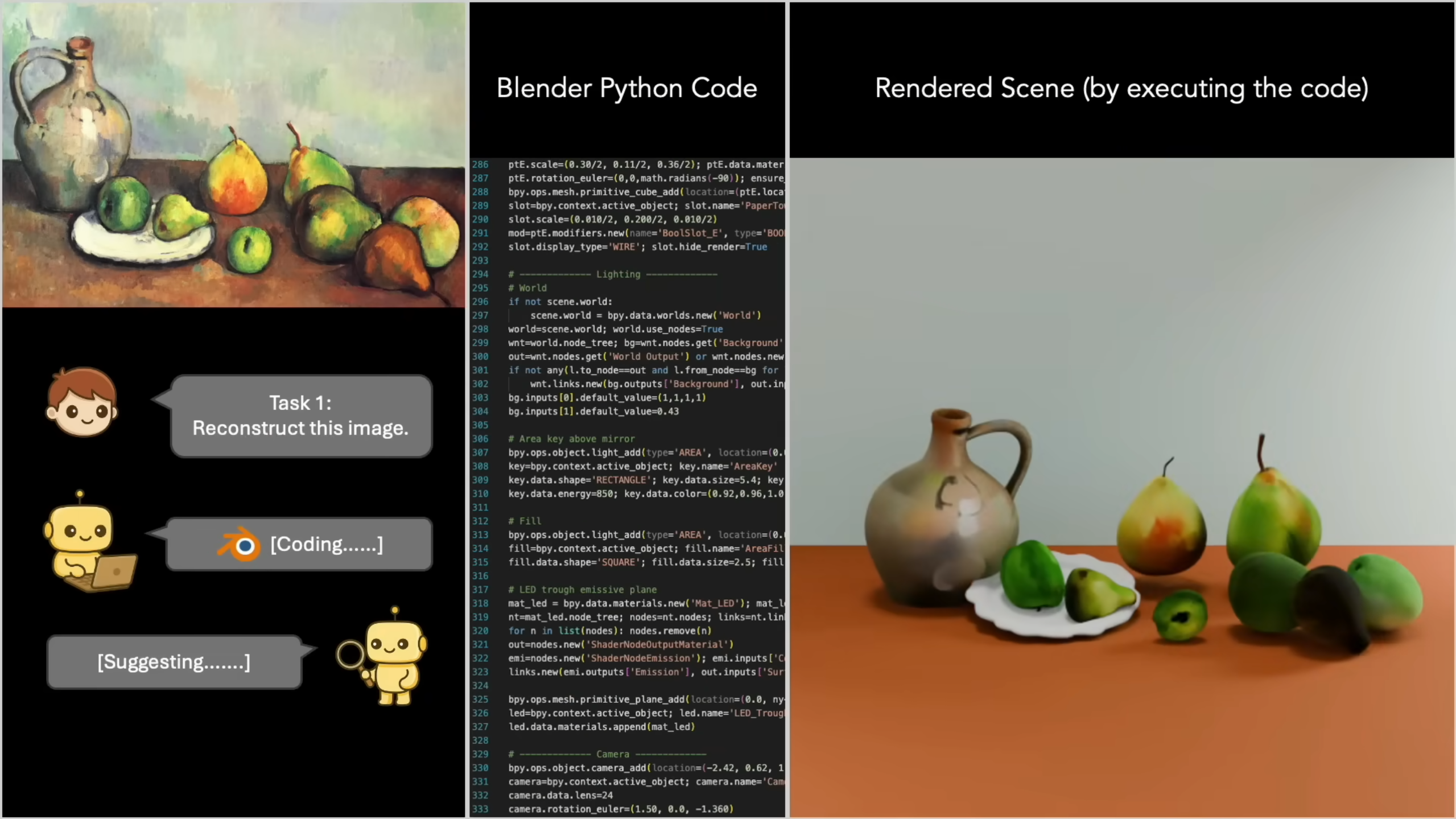
VIGA betrachtet ein Bild und "denkt" sich: "Wie würde ich das in Blender bauen?". Es erkennt Objekte, Materialien und Lichtverhältnisse und übersetzt diese in ein Python-Skript, das die Blender API nutzt.
- Physik-Interaktion: Da die Ausgabe eine echte 3D-Szene ist, können Sie anschließend einen virtuellen Ball in die Szene werfen, und die Vasen werden physikalisch korrekt umfallen oder zerbrechen.
- Reflexionen: Der Agent versteht sogar komplexe Materialien wie Spiegel und setzt die Render-Einstellungen entsprechend.
Dieser Ansatz des "Analysis-by-Synthesis" überbrückt die Lücke zwischen generativer KI und klassischer 3D-Pipeline-Integration.
VideoMaMa: Perfektes Freistellen – selbst bei wilden Haaren
Jeder Video-Editor kennt den Albtraum: Haare, Rauch oder halb-transparente Objekte freistellen (Rotoscoping). VideoMaMa (Mask-Guided Video Matting via Generative Prior) löst dieses Problem mit beeindruckender Präzision.
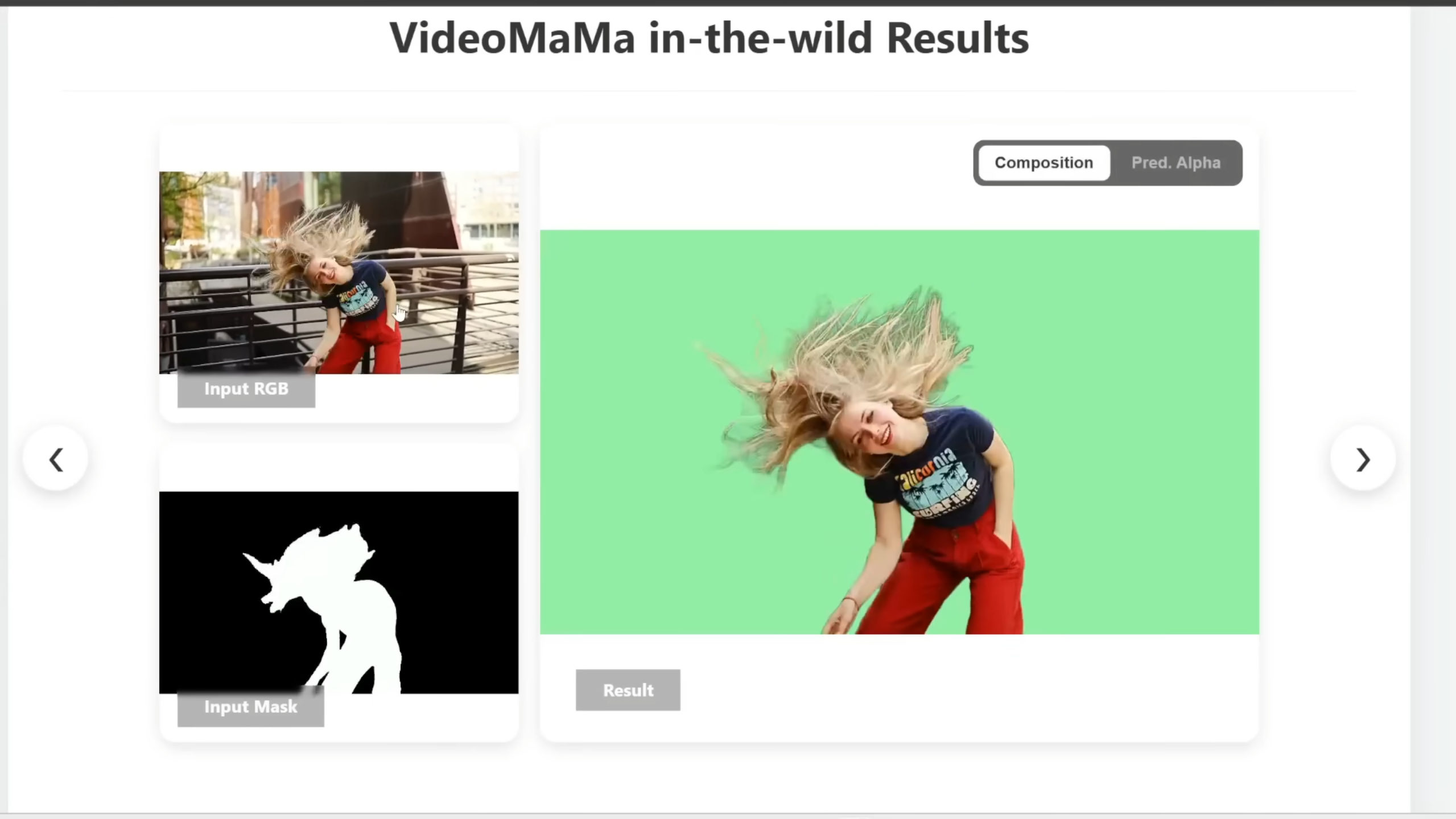
Bildquelle: VideoMaMa
Das Modell nutzt einen "Generative Prior", um vorherzusagen, wie die Alpha-Matte aussehen sollte. Anstatt nur auf Farbunterschiede zu achten (was bei Rauch oft versagt), versteht das Modell die Struktur des Objekts. Wie in Abbildung 5 zu sehen, meistert es selbst schnelle Kopfbewegungen mit wehendem Haar – ein Szenario, an dem traditionelle Tools oft scheitern.
LightOnOCR: 1 Milliarde Parameter sind genug
Im Bereich der Dokumentenverarbeitung galt lange: Größer ist besser. LightOnOCR beweist das Gegenteil. Mit nur 1 Milliarde Parametern übertrifft dieses Modell Giganten der Branche.
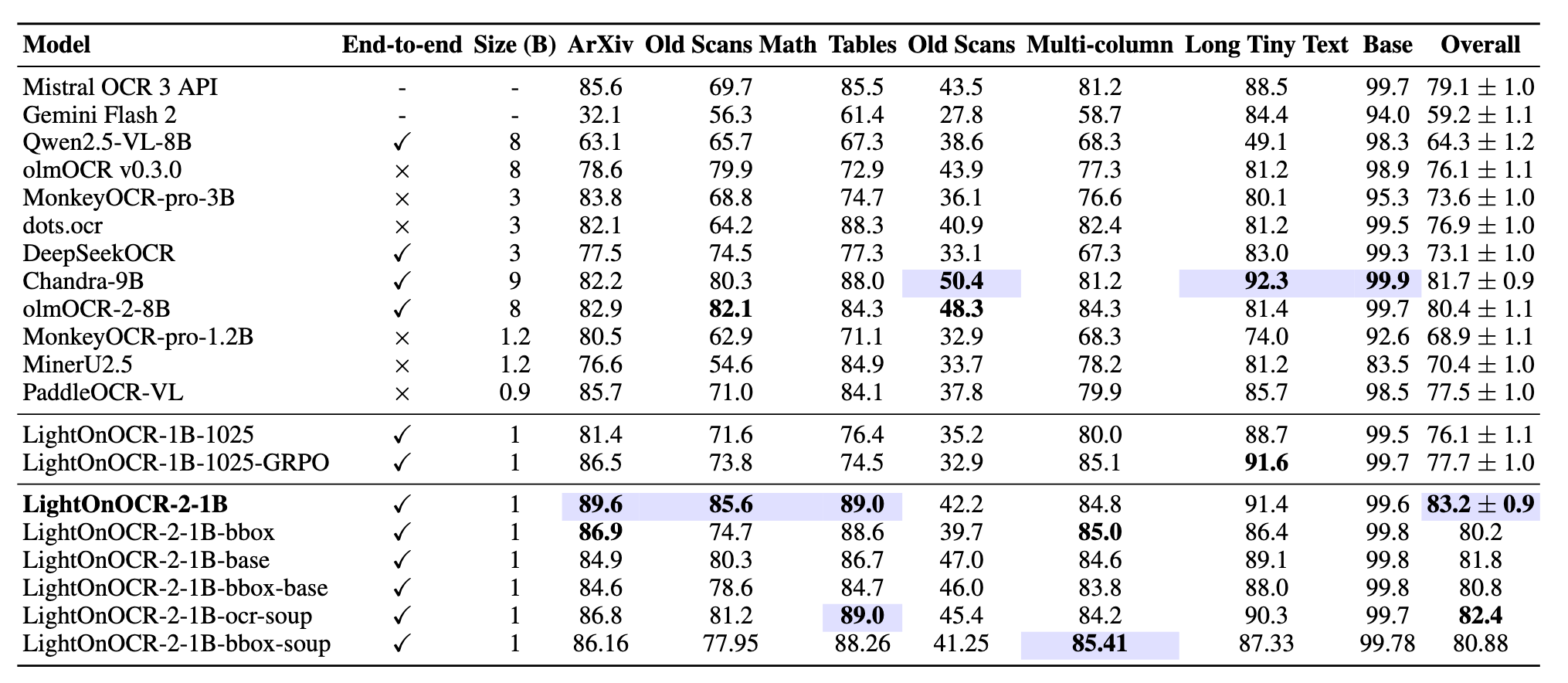
Es handelt sich um ein End-to-End Vision-Language Model. Das bedeutet, es gibt keine separate "Texterkennungs"- und "Textlesen"-Phase. Das Modell "sieht" das Dokument und generiert direkt den Markdown-Text.

Besonders beeindruckend ist die Fähigkeit, komplexe Layouts (siehe Abb. 7) zu verstehen. Es liest nicht einfach Zeile für Zeile, sondern versteht die semantische Struktur einer Tabelle oder eines wissenschaftlichen Papers. Die Effizienz (2 GB Speicherbedarf) macht es ideal für lokale Anwendungen auf Consumer-Hardware.
Step3-VL: Multimodale Intelligenz im Kompaktformat
Zum Abschluss ein Blick auf Step3-VL-10B. Während Google und OpenAI ihre Modelle immer riesiger machen, zeigt StepFun, dass 10 Milliarden Parameter ausreichen können, um SOTA-Performance (State of the Art) zu erreichen.
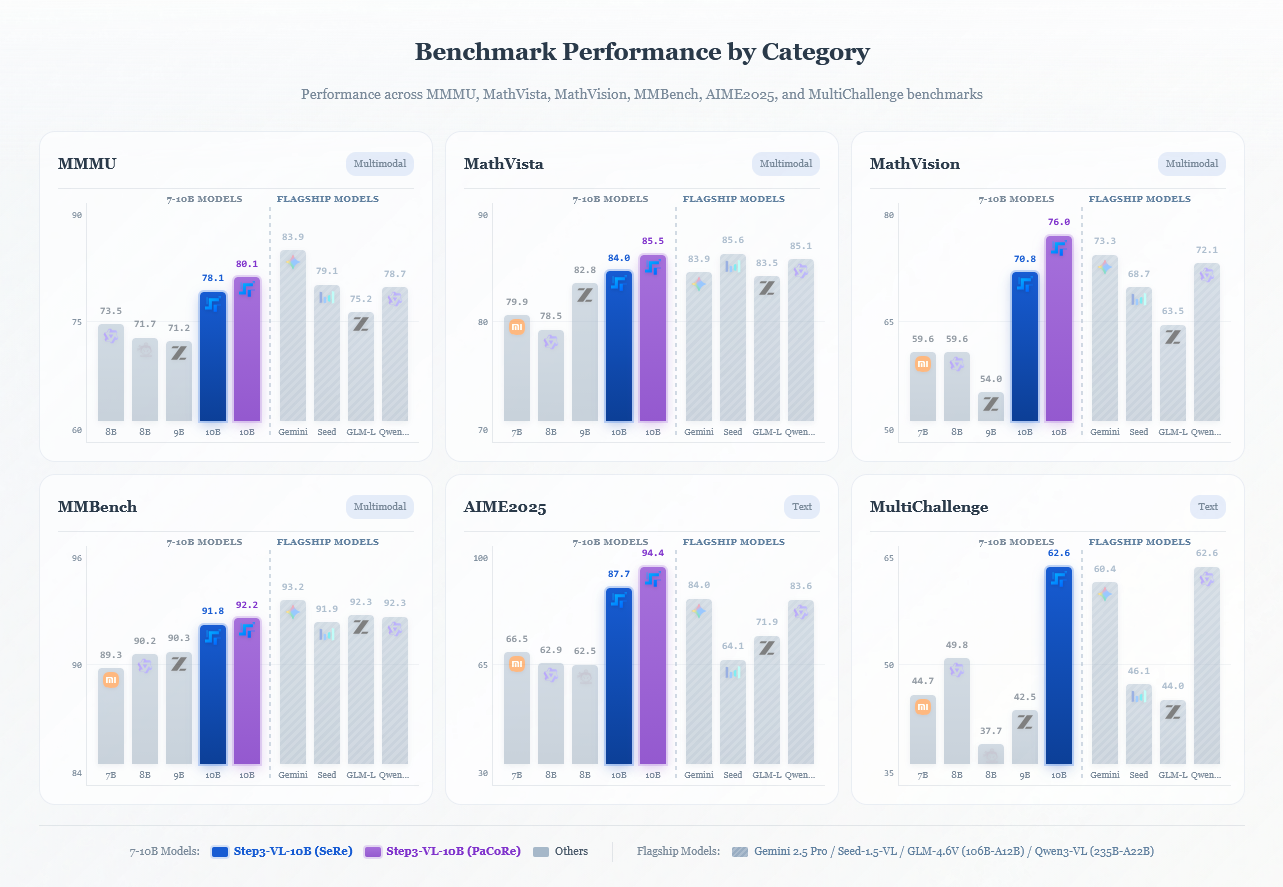
Das Geheimnis liegt im Training. Step3-VL nutzt eine "fully unfrozen pre-training strategy", bei der Vision-Encoder und Sprach-Decoder von Anfang an gemeinsam lernen. Dies führt zu einer viel tieferen Synergie zwischen visuellem Verständnis und logischem Schließen.
Modelle wie Step3-VL und LightOnOCR demokratisieren Hochleistungs-KI. Sie benötigen keine Rechenzentren, sondern laufen auf starken Workstations oder kleinen Servern, was Datenschutz und lokale Verarbeitung massiv erleichtert.
Fazit
Der Januar 2026 zeigt eine klare Richtung: Die Ära der "Brute Force" KI, die einfach nur mehr Daten und Parameter auf ein Problem wirft, weicht intelligenteren Architekturen. Ob VIGAs hybrider Ansatz aus Vision und Code, FlowActs ausgeklügeltes Speichermanagement oder OmniTransfers entkoppelte Lernmechanismen – wir sehen Systeme, die die Welt nicht nur "halluzinieren", sondern ihre Struktur verstehen und kontrollierbar machen.
Für Entwickler und Kreative bedeutet dies: Die Werkzeuge werden nicht nur mächtiger, sondern endlich auch präziser und effizienter steuerbar.
Weitere Quelle und Inspiration für diesen Artikel: AI Search YouTube Kanal.