![AI News Deep Dive: Flux.2 [klein], ShowUI & die neue Ära der Open-Source-Effizienz](/uploads/featured_20260310_095527_69afdc7fb482e.png)
Die Geschwindigkeit, mit der sich die künstliche Intelligenz weiterentwickelt, hat längst den Punkt überschritten, an dem man von bloßen "Trends" sprechen kann. Wir befinden uns in einer Phase der massiven Konsolidierung und Spezialisierung. Während das Jahr 2025 noch von der schieren Größe der Modelle dominiert wurde, sehen wir nun im Jahr 2026 eine Ära der Effizienz, der präzisen Steuerung und der echten Multimodalität. Diese Woche markiert einen Wendepunkt für Open-Source-Modelle, die nicht nur zu proprietären Giganten aufschließen, sondern diese in spezifischen Nischen wie UI-Navigation, 3D-Rekonstruktion und Musikgenerierung sogar übertreffen.
In diesem Deep Dive analysieren wir fünf bahnbrechende Frameworks, die in den letzten Tagen die Forschungsgemeinschaft erschüttert haben. Von der Demokratisierung der Bildgenerierung durch Destillation bis hin zu Agenten, die grafische Benutzeroberflächen wie Menschen verstehen – wir zerlegen die Architekturen und Implikationen von Flux.2 [klein], ShowUI, VerseCrafter, HeartMuLa und UniSH.
Flux.2 [klein]: Die Demokratisierung der High-End-Synthese
Die Veröffentlichung von Flux.2 [klein] ist mehr als nur ein weiteres Update in der unendlichen Flut von Bildgeneratoren. Es ist ein Beweis dafür, dass Knowledge Distillation (Wissensdestillation) der Schlüssel ist, um generative KI aus den Rechenzentren auf lokale Consumer-Hardware zu bringen, ohne dabei signifikante Qualitätskompromisse einzugehen.
Architektur und Effizienz
Das Kernstück der [klein]-Serie ist der aggressive Fokus auf Inferenzgeschwindigkeit bei gleichzeitiger Beibehaltung der visuellen Treue des ursprünglichen Flux-Modells. Wie in der technischen Übersicht zu sehen ist, bietet das Team verschiedene Varianten an, die spezifisch auf unterschiedliche Hardware-Budgets zugeschnitten sind.
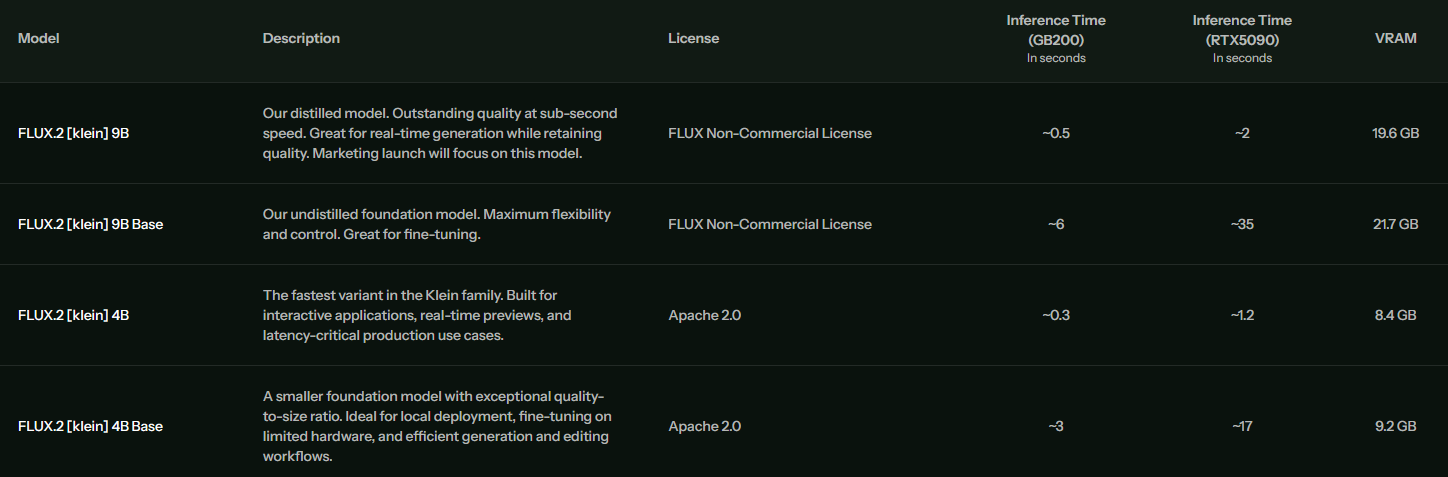
Besonders bemerkenswert ist das Flux.2 [klein] 4B Modell. Mit nur 4 Milliarden Parametern durchbricht es die Schallmauer für interaktive Anwendungen. Auf einer NVIDIA RTX 5090 erreicht dieses Modell eine Inferenzzeit von ca. 1,2 Sekunden. Das ermöglicht workflows, die fast in Echtzeit ablaufen, was für kreative Iterationsprozesse essenziell ist. Selbst das größere 9B-Modell bleibt mit ca. 2 Sekunden auf High-End-Consumer-Karten in einem sehr komfortablen Bereich.
Visuelle Qualität und Anwendungsbereiche
Trotz der Reduktion der Parametergröße zeigt die visuelle Ausgabe eine erstaunliche Kohärenz. Die Modelle beherrschen komplexe Beleuchtungsszenarien, fotorealistische Texturen und stilisierte Illustrationen gleichermaßen.

Ein interessanter Aspekt ist die VRAM-Effizienz. Das 4B-Modell benötigt lediglich 8.4 GB VRAM, was es auf einer breiten Palette von GPUs lauffähig macht, die bisher für State-of-the-Art-Modelle unzugänglich waren. Dies öffnet die Tür für lokale Deployment-Szenarien in Agenturen oder bei Indie-Entwicklern, die keine Cloud-Abhängigkeiten wünschen.
ShowUI (Aloha): Wenn Agenten sehen lernen
Während LLMs (Large Language Models) Text verstehen, scheiterten sie bisher oft an der komplexen, visuell gesteuerten Welt moderner Benutzeroberflächen. ShowUI mit seinem "Aloha"-Modul stellt hier einen Paradigmenwechsel dar. Es handelt sich um einen Vision-Language-Action-Agenten, der nicht nur Code interpretiert, sondern die grafische Oberfläche (GUI) "sieht" und mit ihr interagiert wie ein Mensch.
Vom "Stuck State" zur präzisen Aktion
Das größte Problem bisheriger UI-Agenten war der Kontextverlust. Ein herkömmlicher "OpenAI Operator" mag zwar den Befehl verstehen, scheitert aber oft an der präzisen Verortung des Elements auf dem Bildschirm oder verliert den Faden bei mehrstufigen Prozessen (GitHub Updates, Tabellenkalkulation). ShowUI adressiert dies durch ein visuelles Grounding.

Benchmark-Dominanz
Die Leistung von ShowUI ist nicht nur theoretisch. In Benchmark-Vergleichen, insbesondere bei komplexen Aufgaben wie der Navigation auf Webseiten oder der Transformation von Spreadsheets, übertrifft Aloha etablierte Modelle deutlich. Mit einer Erfolgsrate von 60.1% setzt es sich an die Spitze, weit vor Claude-4 (43.9%) oder GPT-4o basierten Ansätzen (31.3%).
Das Modell nutzt eine Architektur, die visuelle Tokens direkt mit Aktionen verknüpft. Das bedeutet:
- Human Demonstration: Der Agent lernt durch "Zuschauen". Ein Mensch führt eine Aufgabe einmal aus.
- Grounded Procedure: Diese Demonstration wird in eine generalisierbare Prozedur übersetzt.
- Execution: Aloha wendet das Gelernte auch auf leicht abgewandelte Aufgabenvarianten an (z.B. andere Daten in einer Excel-Tabelle), ohne stecken zu bleiben.
VerseCrafter: Die Fusion von 3D und Video
Video-Generierung war lange Zeit ein reines 2D-Problem – Pixel, die sich verändern. VerseCrafter bricht mit dieser Tradition, indem es die Videogenerierung fundamental im dreidimensionalen Raum verankert. Es ist nicht bloß ein "Text-to-Video"-Modell, sondern ein Framework für kontrollierbare Kamerafahrten und Objektphysik.
Der technische Workflow: Von MoGe zu Wan-DiT
Die Architektur von VerseCrafter ist ein Meisterwerk der modularen KI-Entwicklung. Anstatt alles in ein einziges "Black Box"-Netzwerk zu werfen, nutzt es spezialisierte Komponenten für jeden Schritt der Pipeline.
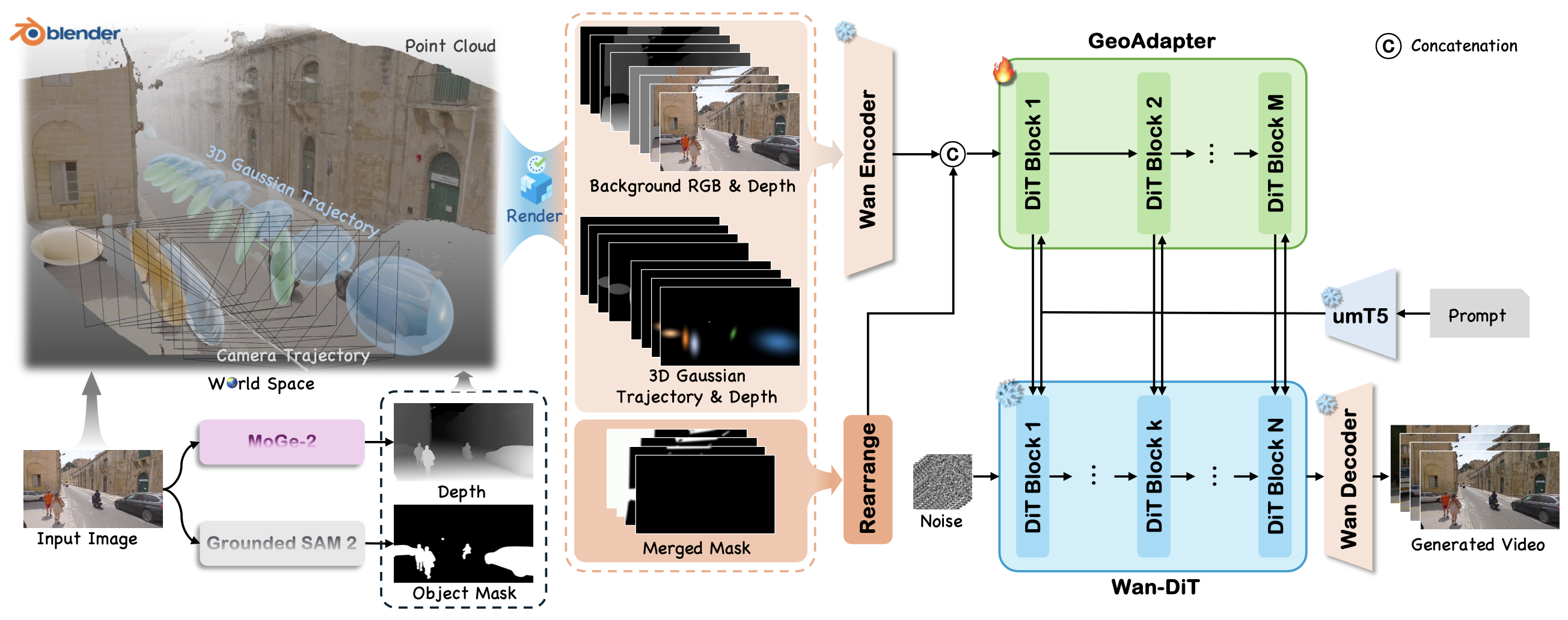
- Input & Analyse: Ein einzelnes Bild dient als Startpunkt. MoGe-2 extrahiert die Tiefeninformationen (Depth), während Grounded SAM 2 (Segment Anything Model) die Objekte maskiert und identifiziert.
- World Space & Point Cloud: Aus diesen Daten wird eine "3D Gaussian Trajectory" erstellt. Das bedeutet, das Bild wird in eine Punktwolke verwandelt, in der die Kamera und Objekte physisch platziert sind.
- GeoAdapter & Wan-DiT: Hier geschieht die Magie. Der GeoAdapter injiziert diese geometrischen Informationen in den Wan Encoder. Das eigentliche Generierungsmodell, ein Diffusion Transformer (Wan-DiT), erzeugt dann das Video.
Das Resultat ist eine Videogenerierung, bei der der Nutzer exakt bestimmen kann: "Kamerafahrt von links nach rechts" oder "Objekt A bewegt sich nach hinten". Dies löst eines der größten Probleme aktueller Video-KI: die mangelnde Konsistenz bei Bewegungen.
HeartMuLa: Musik mit Verständnis
Im Bereich der Audio-Generierung dominieren oft geschlossene Systeme wie Suno oder Udio. HeartMuLa tritt an, um eine offene Alternative zu bieten, die insbesondere bei der Verknüpfung von Text (Lyrics) und Musikstruktur neue Maßstäbe setzt.
HeartCodec und Tokenisierung
Die Qualität von KI-Musik steht und fällt mit der Art und Weise, wie Audio "verpackt" (tokenisiert) wird. HeartMuLa nutzt einen Ansatz, der Text-Tokens, Audio-Encoder-Daten und einen spezifischen HeartCodec Tokenizer kombiniert.
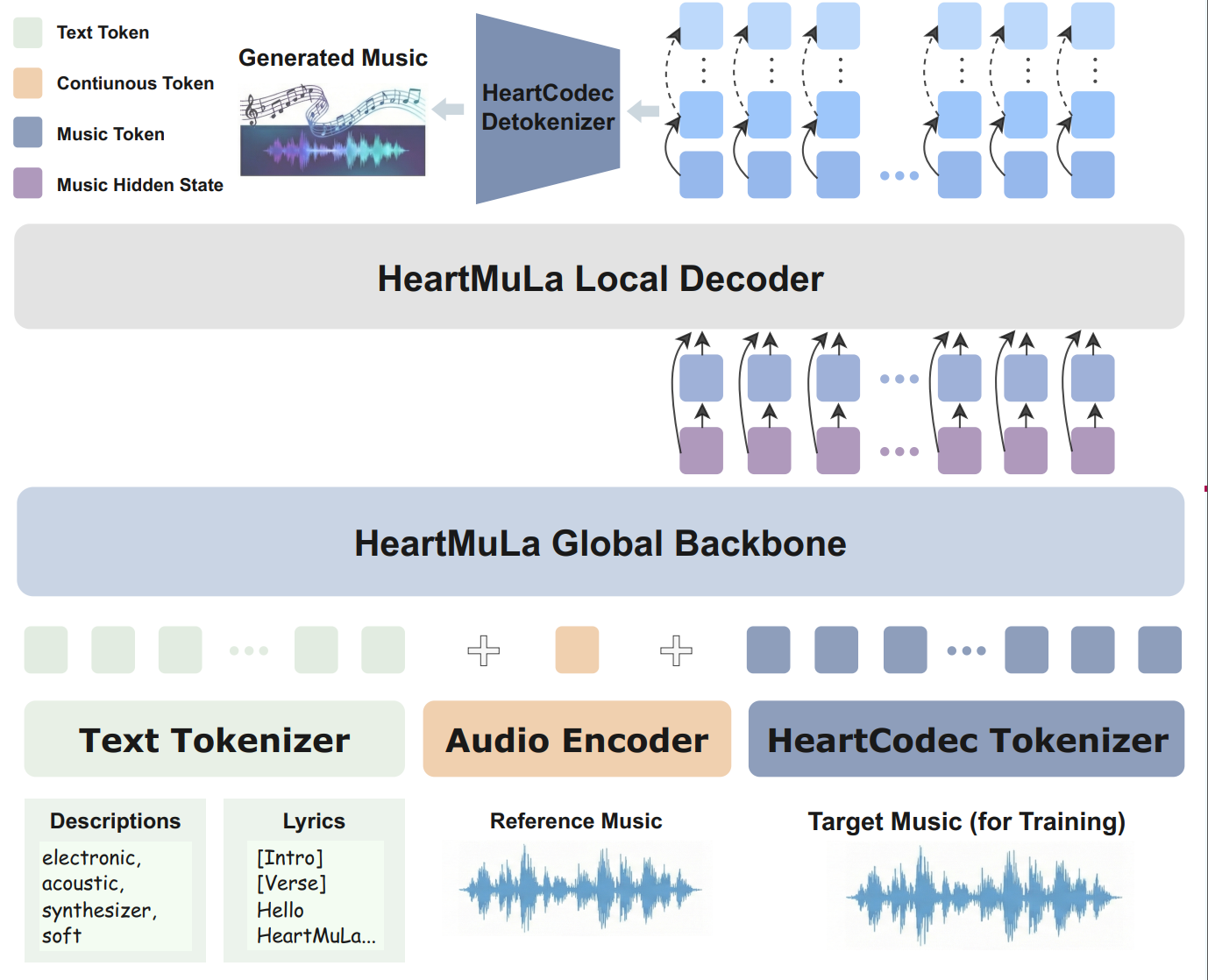
Das Modell unterscheidet zwischen verschiedenen Informationsebenen:
- Semantische Ebene: Beschreibungen wie "electronic, acoustic, soft" und die Lyrics selbst.
- Akustische Ebene: Referenzmusik für das Training und die Ziel-Wellenformen.
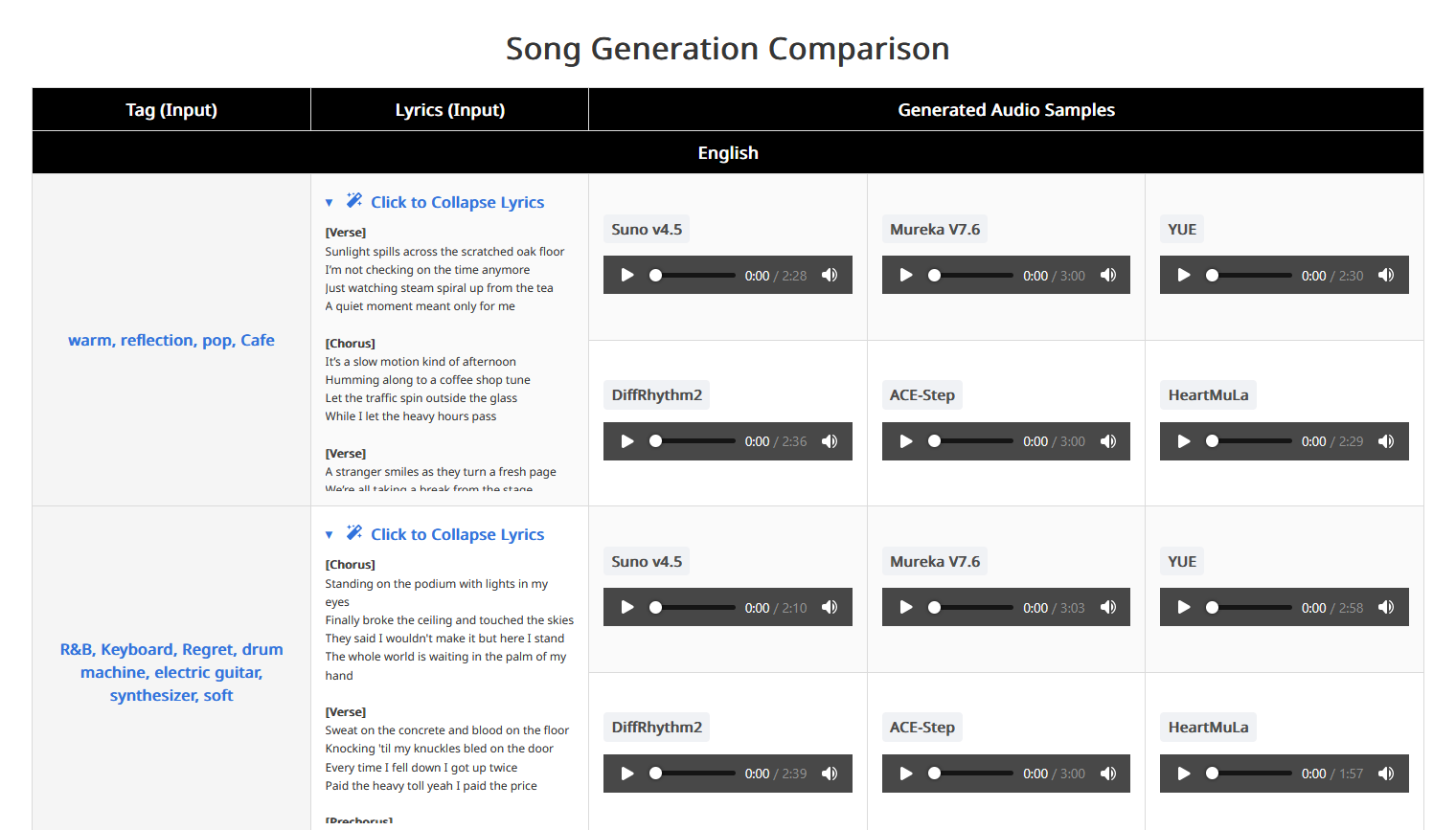
Wie im Vergleich zu sehen ist, konkurriert HeartMuLa direkt mit den großen Namen. Besonders interessant ist die Unterstützung für mehrsprachige Lyrics und die Fähigkeit, komplexe Songstrukturen (Intro, Verse, Chorus) kohärent abzubilden.
UniSH: Der digitale Zwilling aus dem Video
Abschließend werfen wir einen Blick auf UniSH (Unified Scene and Human), ein Tool, das für die Entwicklung des Metaverse und der Spieleindustrie von unschätzbarem Wert sein könnte. Die Herausforderung bestand bisher darin, aus einem flachen Video eine 3D-Szene zu rekonstruieren, in der sich Menschen bewegen, ohne dass es zu Artefakten kommt, wenn diese Menschen Objekte verdecken oder mit ihnen interagieren.
Rekonstruktion und "Inpainting" der Realität
UniSH löst das Problem der Verdeckung (Occlusion). Wenn eine Person in einem Video vor einer Wand steht und sich bewegt, weiß eine normale KI nicht, wie die Wand hinter der Person aussieht. UniSH rekonstruiert sowohl die Szene als auch den Menschen als separate, aber kohärente 3D-Meshes.
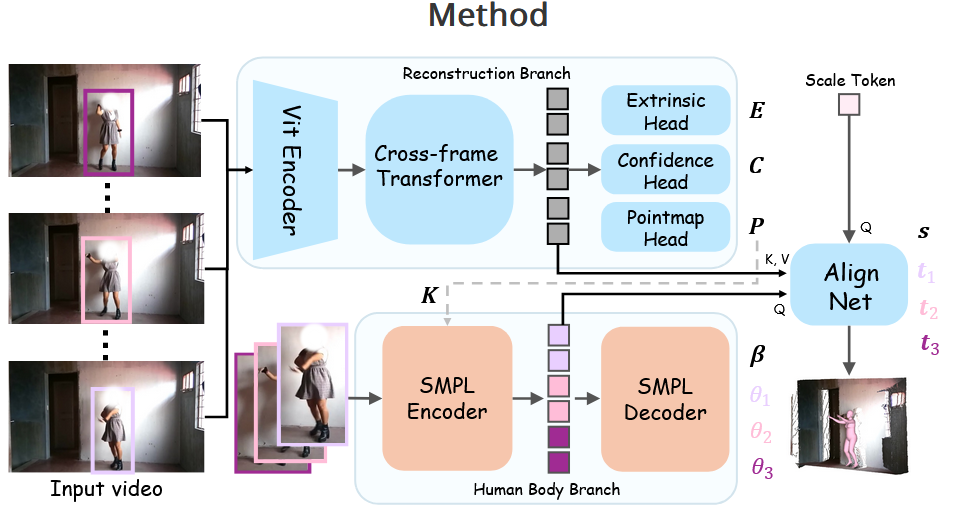
Das Framework nutzt einen SMPL Encoder für den menschlichen Körper (ein Standard in der 3D-Animation) und einen Cross-frame Transformer, um die Umgebung über mehrere Videoframes hinweg zu verstehen. Das Ergebnis ist eine Szene, in der man die Kamera frei bewegen kann – man kann sich also nachträglich im Video "umsehen".

Kurz & Kompakt: Weitere News der Woche
Neben den großen Headlinern gab es diese Woche noch weitere erwähnenswerte Entwicklungen, die zeigen, wie breit gefächert der aktuelle Innovationsschub ist:
- DeepSeek-R1 "Reasoning" Modell: Der Open-Source-Herausforderer setzt neue Maßstäbe in logischen Denkaufgaben und rückt gefährlich nahe an proprietäre Modelle heran – ein klares Signal, dass "Open Weights" die Lücke schließen.
- Google Veo Updates: Neue Funktionen zur Steuerung von Kameraperspektiven in Googles Video-Modell, die als direkte Antwort auf die wachsende Konkurrenz durch Open-Source-Lösungen wie VerseCrafter zu verstehen sind.
- Qwen2.5-VL (Vision Language): Alibaba hat sein multimodales Modell aktualisiert, das nun noch präziser Diagramme und Benutzeroberflächen analysieren kann – die technologische Basis für Agenten wie ShowUI.
- Oasis "Playable AI": Ein Experiment, das eine Minecraft-ähnliche Welt in Echtzeit generiert, zeigt eindrucksvoll, wie Generative Video als Game-Engine der Zukunft fungieren könnte.
Fazit
Die vorgestellten Technologien – Flux.2, ShowUI, VerseCrafter, HeartMuLa und UniSH – zeigen einen klaren Trend: KI wird granularer und kontrollierbarer. Wir bewegen uns weg von der bloßen "Prompt-Glücksspiel"-Mentalität hin zu Werkzeugen, die physikalische Gegebenheiten verstehen, komplexe Software bedienen und Hardware-Ressourcen effizient nutzen. Für Entwickler und Kreative bedeutet dies weniger Barrieren und mehr Macht über das Endergebnis.
Die Frage ist nicht mehr, ob Open Source aufholen kann, sondern wie schnell proprietäre Anbieter ihre Strategien anpassen müssen, um relevant zu bleiben.
Video-Analyse & Marktbeobachtung
Quellenhinweis: Diese Analyse basiert auf aktuellen Veröffentlichungen und technischen Papern zu den genannten Modellen, sowie Inhalten aus dem verlinkten Video-Material.