
Der Dezember 2025 wird als einer der bemerkenswertesten Monate in die Geschichte der Künstlichen Intelligenz eingehen. In einer einzigen Woche haben wir Durchbrüche erlebt, die wir erst für das nächste Jahr erwartet hatten: Von Echtzeit-3D-Welten, die sich während des Spielens generieren, über Videomodelle, die auf einer einzigen GPU in Sekunden rendern, bis hin zu neuen Open-Source-Giganten, die etablierte Marktführer in den Schatten stellen. Die Geschwindigkeit der Innovation hat sich nicht nur verdoppelt – sie ist explodiert.
Einleitung: Wenn Wochen zu Jahren werden
Wer dachte, das Tempo von 2024 sei kaum zu halten, wird dieser Tage eines Besseren belehrt. Wir sehen derzeit eine Konvergenz verschiedener Technologien – effizientere Architekturen, neue Kompressionsverfahren und spezialisierte Hardware-Optimierungen –, die plötzlich Dinge ermöglichen, die gestern noch als "Rechenintensiv" oder "Unmöglich für Consumer-Hardware" galten.
In diesem ausführlichen Deep-Dive analysieren wir die wichtigsten Releases dieser Woche, basierend auf den neuesten Benchmarks und technischen Papern. Wir werfen einen Blick auf TurboDiffusion, das die lokale Videogenerierung revolutioniert, Xiaomis überraschenden Angriff auf die Spitzenklasse mit MiMo V2, Googles aggressiven Preiskampf mit Gemini 3 Flash und den endgültigen Durchbruch der generativen 3D-Welten durch Tencent und Microsoft.
TurboDiffusion: Der Turbolader für lokale KI-Videos
Beginnen wir mit einer der vielleicht praktischsten Neuerungen für Entwickler und Kreative, die lokale Hardware nutzen: TurboDiffusion. Wer bisher versucht hat, hochwertige KI-Videos lokal zu rendern – etwa mit Modellen wie Wan 2.1 oder 2.2 –, kannte das Problem: Wartezeiten. Ein 5-sekündiges Video konnte auf einer Consumer-Karte gut und gerne mehrere Minuten bis hin zu Stunden in Anspruch nehmen.
TurboDiffusion ändert diese Gleichung fundamental. Durch die Implementierung einer Reihe neuartiger Beschleunigungstechniken verspricht dieses Tool eine Geschwindigkeitssteigerung um den Faktor 100 bis 200.

Die Technik unter der Haube
Wie ist ein solcher Sprung möglich? TurboDiffusion nutzt keine "Magie", sondern eine clevere Kombination aus drei spezifischen Optimierungen:
- Sage Attention: Eine optimierte Form des Attention-Mechanismus, die den Rechenaufwand für die Gewichtung der Zusammenhänge im neuronalen Netz drastisch reduziert.
- Sparse Linear Attention (SLA): Anstatt jeden Token mit jedem anderen zu vergleichen (was quadratisch skaliert), nutzt SLA eine verdünnte Matrix, die den Speicherbedarf und die Rechenoperationen linearisiert.
- RCM (Rapid Computation Module): Ein Verfahren, das es dem Modell erlaubt, bestimmte redundante Schritte im Diffusionsprozess zu überspringen, ohne die visuelle Qualität signifikant zu beeinträchtigen.
Das Ergebnis ist verblüffend: Ein 5-Sekunden-Video, das zuvor über 4000 Sekunden Rechenzeit benötigte, wird nun in knapp 35 Sekunden generiert. Für den Endanwender bedeutet dies, dass iterative kreative Prozesse – das "Trial and Error" beim Prompting – nun endlich in fast-Echtzeit möglich sind, selbst auf lokaler Hardware.
Xiaomi MiMo V2 Flash: Der neue Open-Source-König?
Wenn wir an führende KI-Labore denken, fallen meist Namen wie OpenAI, Google oder Anthropic. Doch diese Woche hat Xiaomi mit dem Release von MiMo V2 Flash die Karten neu gemischt. Dieses Modell zielt darauf ab, die perfekte Balance zwischen Geschwindigkeit, Effizienz und roher Intelligenz zu finden – und die Benchmarks deuten darauf hin, dass dies gelungen ist.
Benchmarks, die aufhorchen lassen
MiMo V2 Flash positioniert sich nicht als "noch ein weiteres LLM", sondern als spezialisiertes Werkzeug für Reasoning (logisches Denken) und Coding-Aufgaben. In standardisierten Tests wie dem SWE-bench Verified (einem Benchmark für reale Software-Engineering-Aufgaben) schlägt es nicht nur etablierte Open-Source-Konkurrenten wie DeepSeek V3 oder Kimi k2, sondern konkurriert sogar auf Augenhöhe mit proprietären Giganten.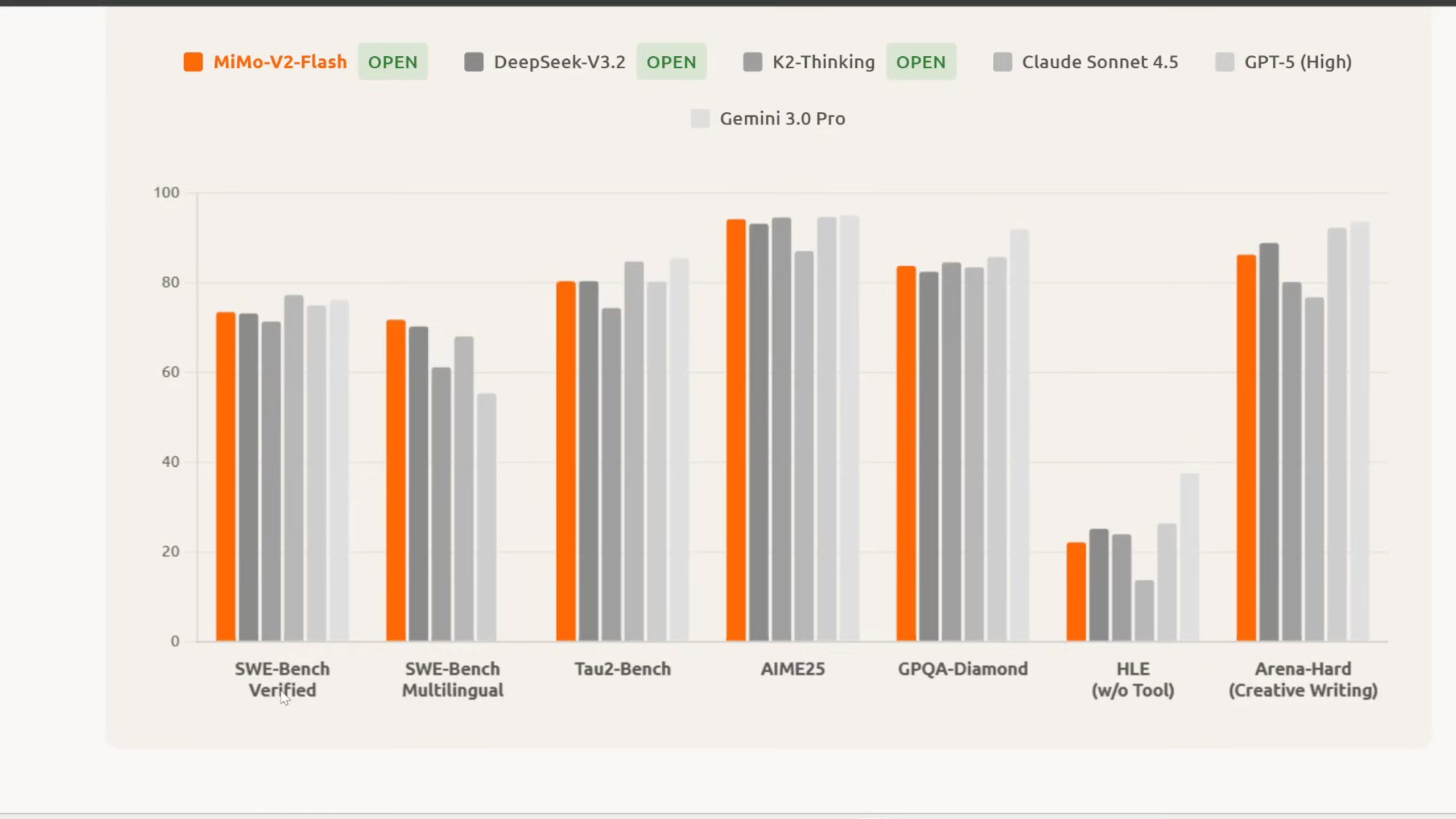
Besonders beeindruckend ist die Architektur: Es handelt sich um ein Mixture-of-Experts (MoE) Modell mit insgesamt 309 Milliarden Parametern. Der Clou ist jedoch, dass pro Token nur etwa 15 Milliarden Parameter aktiv genutzt werden. Dies macht das Modell im Betrieb extrem flink ("Flash"), während es gleichzeitig auf ein riesiges Reservoir an Wissen zugreifen kann.
Coding-Power in der Praxis
Die Stärke im Coding zeigt sich nicht nur in Tabellen, sondern in der Anwendung. Nutzer berichten, dass MiMo V2 in der Lage ist, komplexe interaktive HTML5-Anwendungen aus einem einzigen Prompt zu generieren. Ein Beispiel, das die Runde macht, ist ein vollständig interaktiver "Solar System Explorer", der Planetenbahnen, Informationen und Animationen in reinem Code darstellt – fehlerfrei beim ersten Versuch.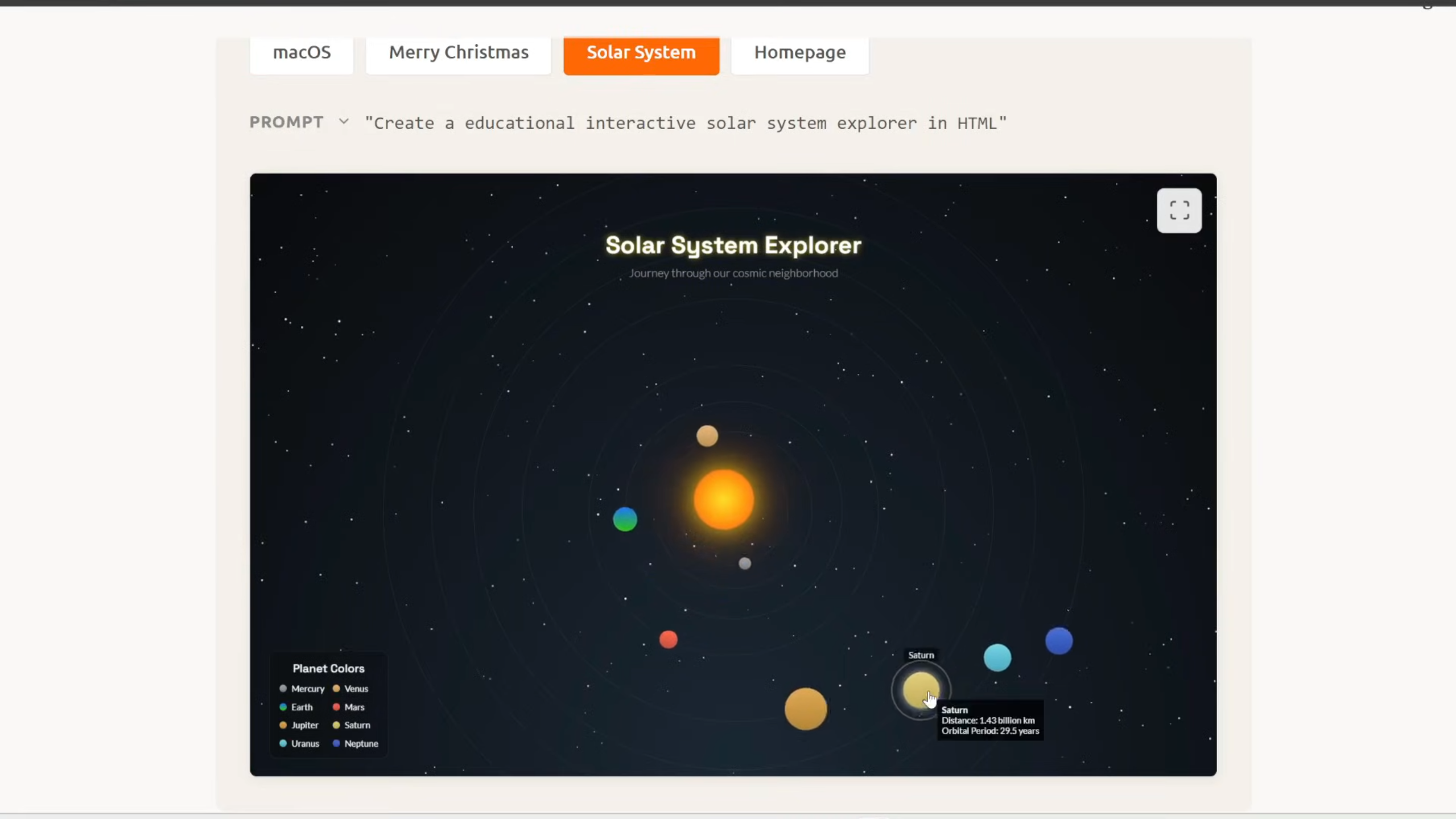
Für Entwickler bedeutet dies: Ein mächtiger, lokal (mit entsprechender Hardware) ausführbarer Coding-Assistent, der weniger halluziniert und mehr "versteht". Allerdings ist der VRAM-Bedarf mit über 300 GB für das volle Modell noch eine Hürde für den Heimgebrauch, weshalb wir gespannt auf quantisierte Versionen warten.
Google schlägt zurück: Gemini 3 Flash
Während die Open-Source-Community feiert, schläft Google nicht. Mit Gemini 3 Flash hat der Tech-Gigant einen aggressiven Preiskampf eingeleitet, der die Ökonomie von KI-Anwendungen verändern könnte. Die Strategie ist klar: Massive Leistung zu einem Preis, der so niedrig ist, dass Konkurrenten kaum profitabel mithalten können.
Preis-Leistungs-Verhältnis neu definiert
Ein Blick auf die aktuellen Token-Kosten (USD pro 1 Million Token) zeigt die Dominanz von Gemini 3 Flash. Mit einem Preis von ca. 1,10 USD liegt es gleichauf mit sehr viel kleineren Modellen, bietet aber die Intelligenz und Multimodalität eines Flaggschiff-Modells. Zum Vergleich: Ein GPT-5-Level Modell oder Claude Opus 4.5 kosten oft das Sechs- bis Zehnfache.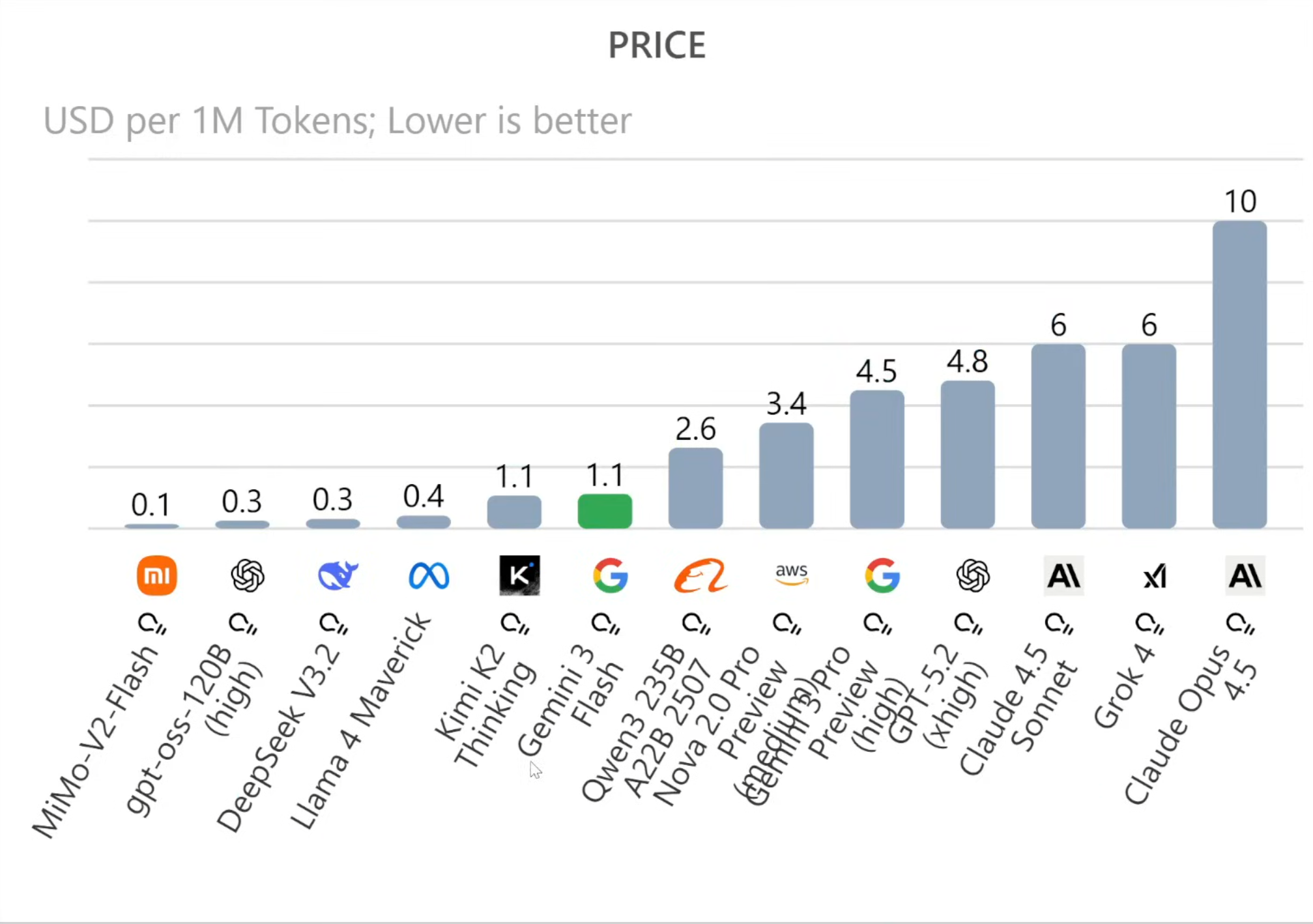
Aber es geht nicht nur um den Preis. Gemini 3 Flash ist multimodal – es kann Video, Audio und Bilder nativ verarbeiten – und verfügt über ein Kontextfenster von einer Million Token. In Benchmarks wie dem Arena-Hard (für kreatives Schreiben) und Coding-Tests zeigt es, dass "billig" hier keineswegs "schlecht" bedeutet. Es ist aktuell das Standardmodell in der Gemini App und dürfte für viele Startups und Entwickler zur ersten Wahl für API-Integrationen werden.
Die dritte Dimension: Trellis 2 und Hunyuan World
Vielleicht die visuell beeindruckendsten News dieser Woche kommen aus dem Bereich der 3D-Generierung. Wir bewegen uns weg von einfachen 2D-Bildern hin zu echten, räumlichen Assets und ganzen Welten.
Trellis 2: Perfekte 3D-Modelle aus einem Bild
Microsoft hat mit Trellis 2 einen riesigen Sprung gemacht. Die Herausforderung bei der Generierung von 3D-Modellen aus einem einzigen 2D-Foto bestand immer darin, die "Rückseite" des Objekts plausibel zu halluzinieren. Trellis 2 meistert dies mit einer fast unheimlichen Präzision.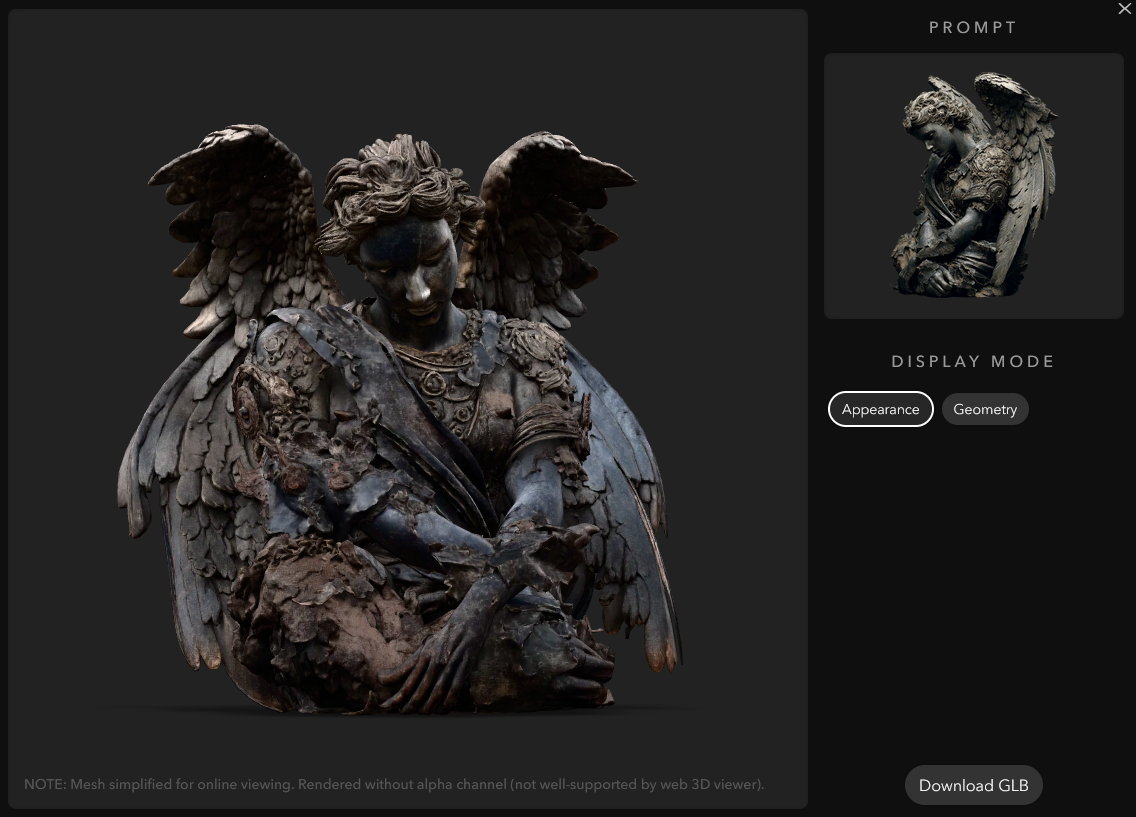
Technisch setzt Trellis 2 auf sogenannte Oxels (eine Art selektiver 3D-Pixel), die Geometrie und Materialeigenschaften (wie Reflektivität oder Transparenz) separat speichern, aber gemeinsam rendern. Kombiniert mit einer "Sparse Compression VAE", die die Datenmenge um das 16-fache komprimiert, entstehen Modelle, die hochdetailliert und dennoch speichereffizient sind. Selbst schwierige Objekte wie pelzige Tiere oder komplexe Rucksäcke mit vielen Gurten werden realistisch in 3D übertragen.
Hunyuan World 1.5: Die unendliche Echtzeit-Welt
Während Trellis einzelne Objekte erstellt, baut Tencent mit Hunyuan World 1.5 ganze Umgebungen – und zwar in Echtzeit. Stellen Sie sich ein Videospiel vor, bei dem die Welt nicht von Designern gebaut wurde, sondern erst in dem Moment entsteht, in dem Sie sich in sie hineinbewegen.
Nutzer können sich mit den WASD-Tasten durch diese generierten Welten bewegen. Noch faszinierender ist die Möglichkeit, die Umgebung per Sprachbefehl live zu verändern: "Lass die Burg brennen" oder "Verdunkle den Himmel" werden sofort umgesetzt. Zwar gibt es noch sichtbares Rauschen und Artefakte, doch die Tatsache, dass dies auf einer einzelnen GPU mit 14 GB VRAM läuft, ist ein technisches Wunderwerk und ein Vorbote für die Zukunft der Gaming-Industrie.
Weitere Highlights der Woche
Die Fülle an Neuheiten macht es schwer, alles abzudecken, aber diese Tools verdienen ebenfalls Beachtung:
Scale & Kling Motion Control
Die Kontrolle über KI-Videos wird präziser. Mit Scale (Open Source) und Kling Motion Control (Proprietär) können wir nun die Bewegungen einer Person aus einem Referenzvideo exakt auf eine generierte Figur übertragen. Scale glänzt dabei besonders durch die Extraktion echter 3D-Posen, was verhindert, dass Gliedmaßen bei komplexen Drehungen "verschmelzen" oder verschwinden. Selbst Kampfszenen oder Tänze lassen sich so konsistent animieren.
Wan 2.6 und die Konkurrenz
Alibaba hat mit Wan 2.6 ein Update nachgeschoben, das nun Referenz-Videos als Input akzeptiert. Auch wenn es nur ein kleines Upgrade zu Version 2.5 ist, zeigt es, wie schnell die Iterationszyklen geworden sind. Gleichzeitig drängt ByteDance mit SeaDance 1.5 Pro in den Markt und beansprucht in Sachen Audio-Synchronität und Bewegungsfluss die Führung für sich.
Ego X: Perspektivenwechsel
Ein spannendes Forschungsprojekt ist Ego X, das Videos aus der dritten Person (z.B. eine Fußballübertragung) in eine Ego-Perspektive (First-Person-View) umrechnet. Die KI muss dabei halluzinieren, was der Spieler sieht – eine extrem komplexe Aufgabe, die für VR-Anwendungen und Simulationen bahnbrechend sein könnte.
Fazit: Die Demokratisierung der High-End-KI
Was diese Woche im Dezember 2025 so besonders macht, ist nicht nur die reine Leistung der Modelle, sondern ihre Verfügbarkeit. Tools wie TurboDiffusion, Trellis 2 und MiMo V2 sind (oder werden) Open Source. Technologien, die vor Monaten noch Supercomputern vorbehalten waren, laufen nun auf gut ausgestatteten Heim-PCs (oder zumindest auf erreichbaren Cloud-Instanzen).
Für Content Creator, Entwickler und Unternehmen bedeutet dies: Die Eintrittsbarrieren fallen weiter. Die Frage ist nicht mehr "Ist das technisch möglich?", sondern nur noch "Wer hat die beste Idee, es zu nutzen?".
Relevantes Video: AI Search
Dieses Video bietet eine detaillierte Zusammenfassung und visuelle Demonstrationen der im Artikel besprochenen Durchbrüche.
Die Zukunft gehört nicht denen, die die KI bauen, sondern denen, die sie am kreativsten einsetzen.
AI News Weekly, Dezember 2025