
Willkommen zu einem der vielleicht bedeutendsten Wendepunkte in der rasanten Evolution der Künstlichen Intelligenz. In einer Phase, in der etablierte Giganten wie OpenAI überraschende strategische Kehrtwenden vollziehen und Open-Source-Modelle beispiellose Leistungsrekorde brechen, stehen wir an der Schwelle zu einer neuen Ära. Eine Ära, in der KI nicht länger nur assistiert oder statische Texte generiert, sondern interaktive Welten in Echtzeit simuliert, tiefgreifendes physikalisches Verständnis aufbaut und sogar in der Lage ist, menschliche Gehirnaktivitäten zu prädizieren. Von leistungsstarken Agenten, die unseren Computer bedienen, bis hin zu hyperrealistischen Robotern und revolutionären Komprimierungsverfahren – die technologischen Durchbrüche dieser Woche verschieben die Grenzen des Machbaren. Tauchen wir tief ein in die Innovationen, die das Fundament unserer digitalen und physischen Zukunft neu gießen.
Der Paukenschlag bei OpenAI: Warum die Sora-App das Feld räumt
Es war eine Nachricht, die wie ein Beben durch die KI-Community ging: OpenAI stellt die verbraucherorientierte Sora-App ein. Kaum ein halbes Jahr nach der spektakulären Präsentation, die die Welt mit fotorealistischen, physikalisch kohärenten Videogenerierungen in Staunen versetzte, zieht das Unternehmen bei der Standalone-Applikation den Stecker. Um dies klarzustellen: Das Sora-2-Modell an sich ist keineswegs tot. Es wird weiterhin existieren und in das ChatGPT-Ökosystem für zahlende Nutzer integriert. Doch die Vision einer eigenständigen, TikTok-ähnlichen Plattform für KI-generierte Videos wurde abrupt beendet.
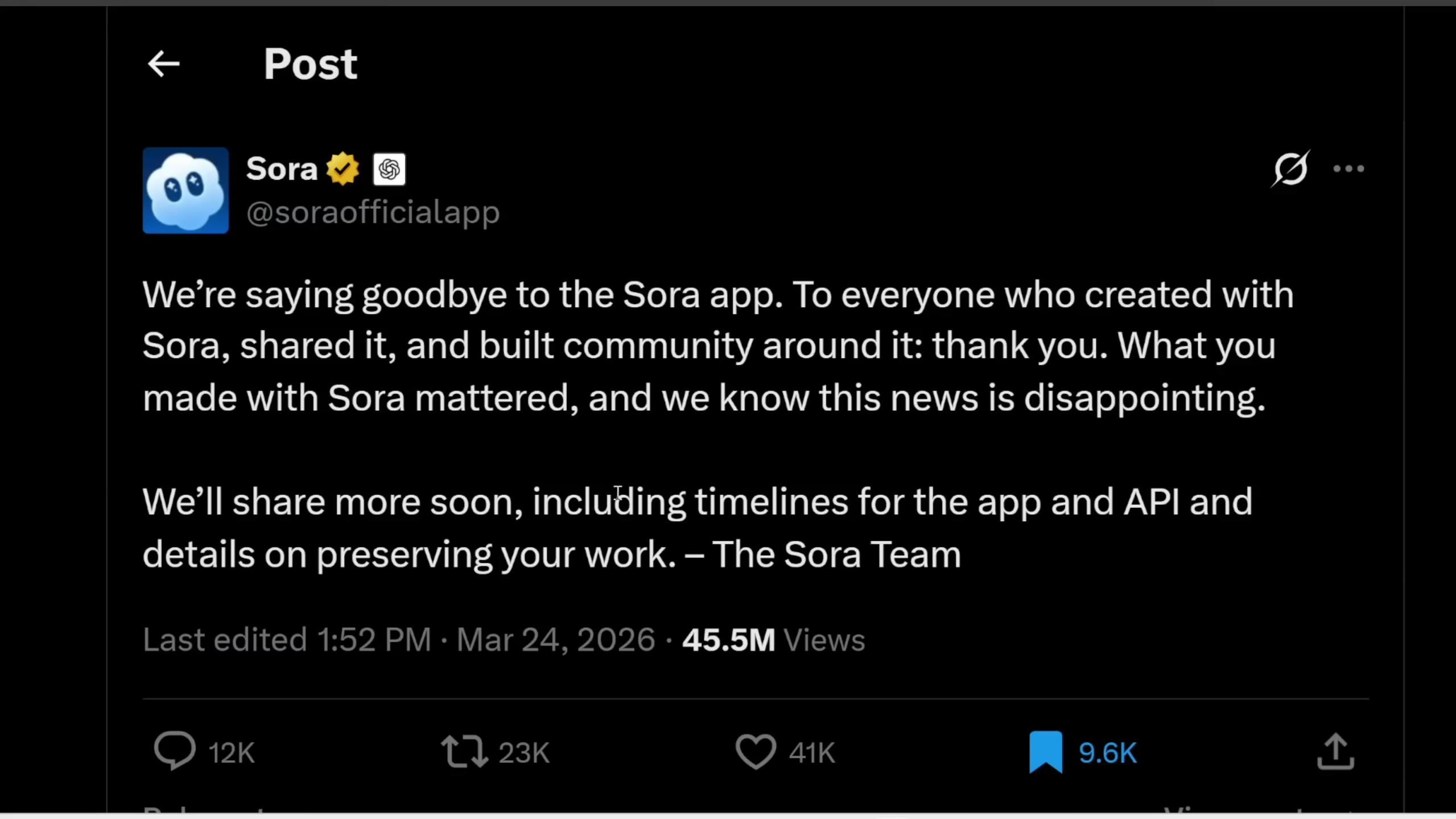
Die Gründe für diesen drastischen Schritt sind vielschichtig und offenbaren die harten wirtschaftlichen und strategischen Realitäten der modernen KI-Entwicklung. An vorderster Front steht das Thema Compute-Kosten. Die Generierung von hochauflösenden Videos ist extrem rechenintensiv. Eine kostenlose oder auch nur günstige App für Millionen von Nutzern zu betreiben, verbrennt Unmengen an Serverkapazitäten – Ressourcen, die OpenAI dringend an anderer Stelle benötigt. Das Unternehmen hat klargemacht, dass der Fokus nun massiv auf "Real-World Physical Tasks" und Robotik verlagert wird. Man möchte Systeme bauen, die nicht nur Pixel auf einem Bildschirm arrangieren, sondern die physische Welt tiefgreifend verstehen und in ihr interagieren können.
Darüber hinaus spielt die Konkurrenz im Enterprise-Sektor eine gewaltige Rolle. Unternehmen wie Anthropic setzen mit ihren Modellen starke Akzente im Bereich der autonomen Programmierung und geschäftlichen Automatisierung. OpenAI muss seine wertvollen Rechenressourcen bündeln, um in diesem hochprofitablen B2B-Markt seine Dominanz zu sichern. Nicht zuletzt darf der Aspekt der Sicherheit nicht ignoriert werden: Eine frei zugängliche Plattform zur Generierung hyperrealistischer Videos bringt massive Herausforderungen in Bezug auf Deepfakes, Desinformation und Urheberrechtsverletzungen mit sich. Die Integration in das geschlossenere ChatGPT-Ökosystem erlaubt eine wesentlich striktere Kontrolle.
daVinci-MagiHuman: Die nächste Generation der Open-Source-Videogenerierung
Während OpenAI den Zugang zu seinen Videomodellen restriktiver gestaltet, explodiert die Open-Source-Community förmlich. Das beeindruckendste Beispiel dieser Woche ist daVinci-MagiHuman. Es handelt sich hierbei um ein massives, 15 Milliarden Parameter starkes Modell, das eine fundamentale Hürde bisheriger Systeme überwindet: die native Integration von Audio. Anstatt Video und Audio in separaten Schritten zu generieren und mühsam durch Dritt-Tools zu synchronisieren, erzeugt MagiHuman beides gleichzeitig in einem einheitlichen Prozess.
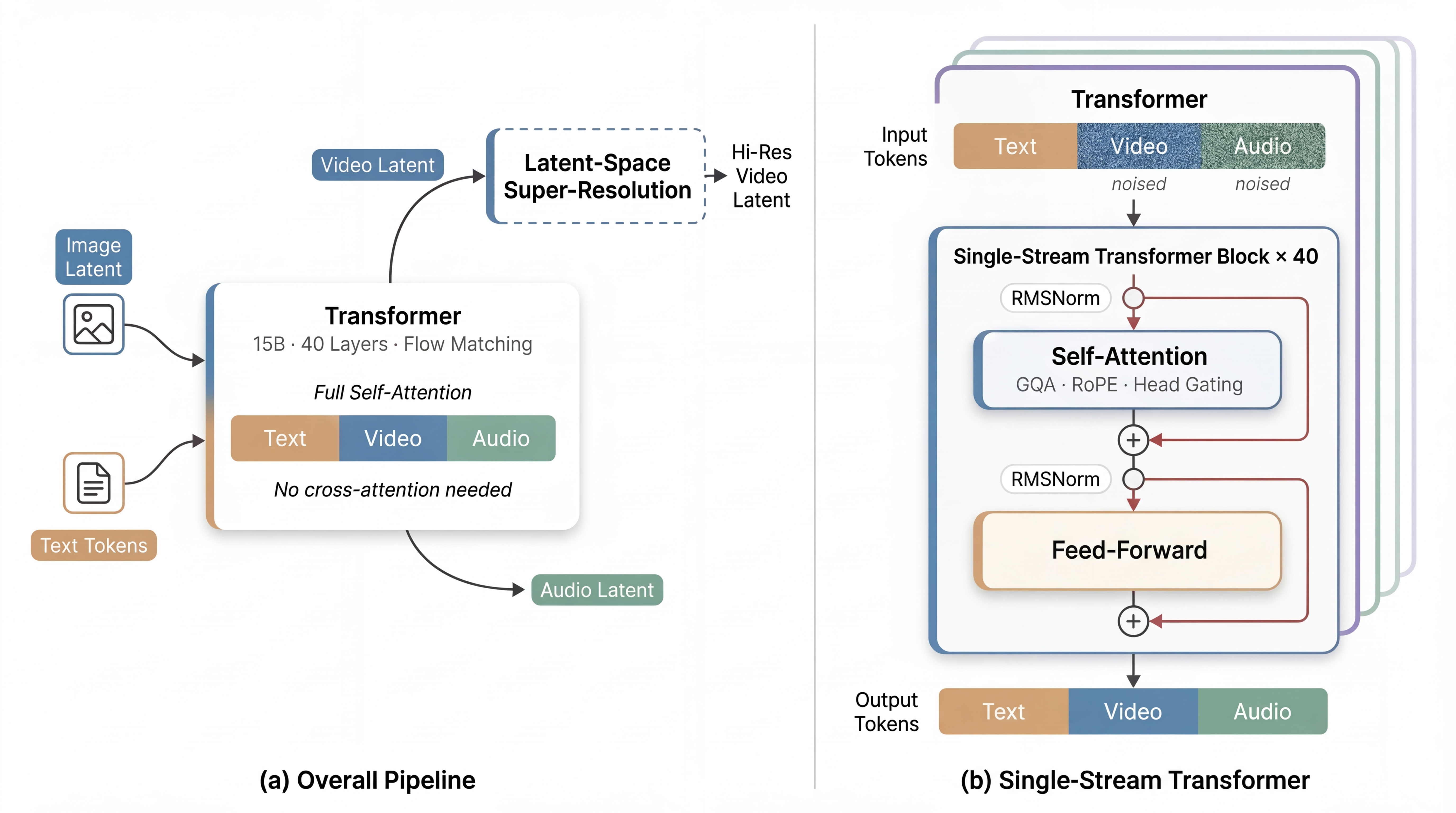
Die zugrundeliegende Architektur ist ein Meisterwerk der Ingenieurskunst. Sie basiert auf einem 40-lagigen Single-Stream Transformer, der das sogenannte "Flow Matching" anwendet – eine Weiterentwicklung der klassischen Diffusionsmodelle, die effizienter und präziser arbeitet. In diesem System existieren Text, Video und Audio gemeinsam in einem hochdimensionalen latenten Raum. Das bedeutet: Wenn eine generierte Person im Video spricht, sind die Lippenbewegungen absolut synchron zur Audiospur, und die mikrofeine Mimik passt perfekt zur emotionalen Tonalität der Stimme. Das System unterstützt out-of-the-box mehrere Sprachen und präsentiert sich als unzensiertes Foundation-Modell.
In direkten Blindtests (Human Evaluations) schlägt daVinci-MagiHuman den bisherigen Spitzenreiter LTX 2.3 in 60 % der Fälle – eine signifikante Marge in diesem hochkompetitiven Feld. Die visuelle Detailtreue, die exakte Ausführung von Text-Prompts und vor allem die niedrige Fehlerrate bei komplexen physikalischen Bewegungen setzen völlig neue Standards. Der einzige Haken? Die massiven Hardware-Anforderungen. Selbst die destillierte Version des Modells verschlingt gewaltige 61 Gigabyte VRAM. Für den durchschnittlichen Heimanwender mit einer Standard-Grafikkarte ist das Ausführen dieses Modells derzeit außer Reichweite. Dennoch beweist dieser Release eindrucksvoll, dass die Open-Source-Community nicht nur zu den großen Tech-Konzernen aufschließt, sondern deren Monopolstellung in der generativen Forschung zunehmend aufbricht.
RealRestorer: Alte Erinnerungen und fehlerhafte Bilder in neuem Glanz
Ein weiteres Highlight aus dem Open-Source-Sektor ist RealRestorer. Wer schon einmal versucht hat, ein stark verrauschtes, verschwommenes oder verwittertes Foto digital aufzuarbeiten, kennt die Frustration limitierter klassischer Filter. RealRestorer ist ein hochspezialisiertes KI-Modell, das explizit darauf trainiert wurde, reale, schwer beschädigte Bilder zu reparieren. Es geht radikal über einfache Schärfefilter hinaus: Es versteht den semantischen Kontext einer Szene und rekonstruiert verlorene physikalische Informationen von Grund auf.

Die Fähigkeiten dieses Modells sind grenzenlos. Es kann exzessives ISO-Rauschen entfernen, komplexe Bewegungsunschärfe korrigieren, stark fragmentierte JPEG-Artefakte tilgen und sogar Wettereffekte wie dichten Regen oder Schnee aus einer Szenerie herausrechnen. Darüber hinaus brilliert es bei der Entfernung unerwünschter Lichtreflexionen, die entstehen, wenn man durch eine Glasscheibe fotografiert, und kann historische Schwarz-Weiß-Aufnahmen nicht nur detailgetreu restaurieren, sondern organisch kolorieren.
In strengen Benchmark-Tests operiert RealRestorer auf Augenhöhe mit den besten kommerziellen, proprietären Modellen und deklassiert aktuelle Open-Source-Konkurrenten wie Qwen ImageEdit deutlich. Für professionelle Fotografen, Kreativagenturen und Archivare ist dieses Werkzeug ein epochaler Gewinn. Die lokale Ausführung benötigt zwar rund 42 Gigabyte Speicherplatz, belohnt den Nutzer jedoch mit einer unvergleichlichen, kompromisslosen Qualität bei der Bildrekonstruktion – völlig kostenfrei und datenschutzkonform lokal ausgeführt.
Meta Tribe V2: Wenn Künstliche Intelligenz unsere Gehirnströme simuliert
Wir verlassen die Welt der Bildgenerierung und betreten das faszinierende, fast schon beängstigende Terrain der Neurowissenschaften. Meta hat mit Tribe V2 ein Modell veröffentlicht, das weder Texte noch konventionelle Medien generiert. Stattdessen prädiziert es die rohen Reaktionen des menschlichen Gehirns. Präziser gesagt: Tribe V2 nimmt einen beliebigen sensorischen Reiz auf – sei es ein Video oder eine Audiodatei – und simuliert ein fMRI (funktionelle Magnetresonanztomographie)-Signal, das exakt visualisiert, wie ein echtes menschliches Gehirn auf diesen Reiz reagieren würde.
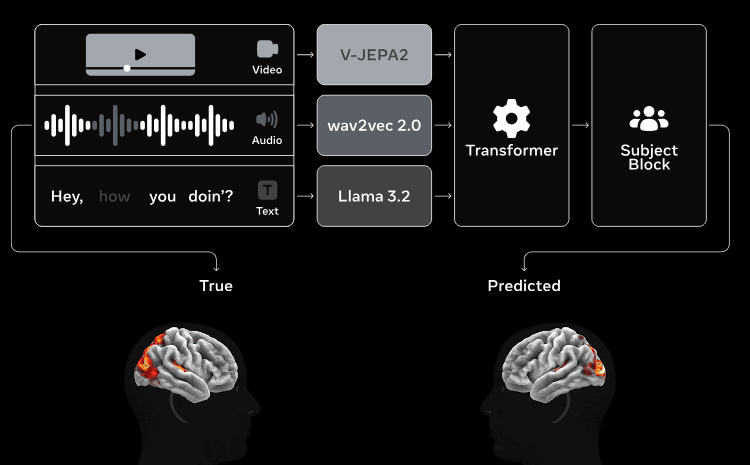
Um diese technologische Magie zu vollbringen, wurde das Modell mit Aberhunderten von Stunden an realen, medizinischen fMRI-Scans von über 700 unterschiedlichen Probanden trainiert. Die KI lernte, die extrem chaotischen, komplexen und nicht-linearen Muster zu decodieren, mit denen unser zerebraler Kortex sensorische Informationen in Millisekunden verarbeitet. Das wahrhaft Revolutionäre an Tribe V2 ist jedoch seine überlegene Fähigkeit zur Generalisierung (Zero-Shot-Learning im neurobiologischen Kontext). Es kann Gehirnreaktionen auf völlig neue YouTube-Videos vorhersagen, die es nie zuvor in seinen Trainingsdaten gesehen hat.
Die weitreichenden Implikationen dieses Durchbruchs lassen sich kaum überbetonen. Die Forscher bei Meta konnten belegen, dass die von Tribe V2 generierten Vorhersagen oft repräsentativer für eine "idealtypische" menschliche Wahrnehmungsreaktion sind als ein einzelner, realer fMRI-Scan, der durch tagesformabhängige Müdigkeit, ablenkende Gedanken oder minimales Rauschen des MRT-Geräts verfälscht sein kann. Wir sprechen hier im Grunde von einem "digitalen Zwilling" der menschlichen Kognition. Dies wird die neurowissenschaftliche Forschung, die Frühdiagnostik von Wahrnehmungsstörungen und die Entwicklung invasiver Neuroprothesen um Jahrzehnte beschleunigen. Dass Meta dieses unfassbar mächtige Werkzeug als Open Source zur Verfügung stellt, ist ein bemerkenswerter Akt für die globale Medizinforschung.
ARC-AGI-3: Der Lackmustest für echte Intelligenz
Inmitten der medialen Jubelstürme über Sprachmodelle, die perfekte juristische Aufsätze schreiben oder komplexe Mathematik-Rätsel lösen, stellt der ARC-AGI-3 Benchmark eine essenzielle, fast schon philosophische und zugleich unbequeme Frage: Haben unsere modernsten KI-Systeme wirklich gelernt, intrinsisch zu "denken", oder sind sie lediglich gigantische, stochastische Papageien, die in Trillionen von Trainingsparametern meisterhaft bekannte Muster interpolieren?
Aktuelle Frontier-Modelle brillieren beim Programmieren, bei formalem logischem Schließen und bei der Textanalyse – all das sind Fähigkeiten, auf die sie massiv hintrainiert wurden. Wenn man sie jedoch in eine völlig neuartige Situation wirft, deren Regeln nicht explizit ausformuliert sind und die nicht in ihrem monströsen Trainingskorpus vorkommt, kollabiert ihre vermeintliche Intelligenz sofort. ARC-AGI-3 (Abstraction and Reasoning Corpus) testet exakt dieses fundamentale Defizit: die Fähigkeit zum Learning on the fly.
Dieser Benchmark operiert nicht mit statischen Textfragen. Stattdessen wird ein KI-Agent in interaktive, grafische Mini-Spiele und Rätselebenen versetzt. Er muss durch reine Exploration, visuelle Beobachtung und induktive Ableitung selbstständig herausfinden, wie die Physik und die Regeln dieser neuen Welt funktionieren. Es gibt keine Bedienungsanleitung. Während ein durchschnittlicher menschlicher Tester diese Mechaniken in wenigen Sekunden intuitiv begreift und die Aufgaben zu 100 % löst, kapitulieren die absoluten Elite-Modelle der Industrie – darunter Giganten wie Gemini 3.1 Pro, Opus 4.6 Max oder Grok 4.2. Ihre Lösungsquoten pendeln sich oft bei vernichtenden 0,5 % ein.
Die aktuellen KI-Modelle sind meisterhaft im Abrufen von gelerntem Wissen, aber völlig hilflos, wenn es darum geht, in Echtzeit und in völlig fremden Umgebungen echte, neue Erkenntnisse zu generieren. Genau deshalb ist dieser Benchmark die wichtigste Messlatte unserer Zeit.
Kernfazit aus der aktuellen ARC-AGI-3 Forschung
Z.ai GLM-5.1: Ein neuer Champion im autonomen Agentic Coding
Wenn es um das Schreiben von Softwarearchitekturen durch Künstliche Intelligenz geht, definieren sogenannte "Agentic Coding"-Modelle aktuell die absolute Speerspitze. Diese Systeme agieren nicht als reine Autocomplete-Assistenten. Sie fungieren als autonome Software-Ingenieure: Sie durchdringen komplexe GitHub-Repositorys, entwerfen Makro-Architekturen, schreiben modularen Code, initiieren automatisierte Unit-Tests, lesen Error-Logs aus dem Terminal und debuggen ihre eigenen Fehltritte iterativ. In dieser Königsdisziplin hat das KI-Labor Z.ai mit GLM-5.1 einen beeindruckenden Vorstoß unternommen.
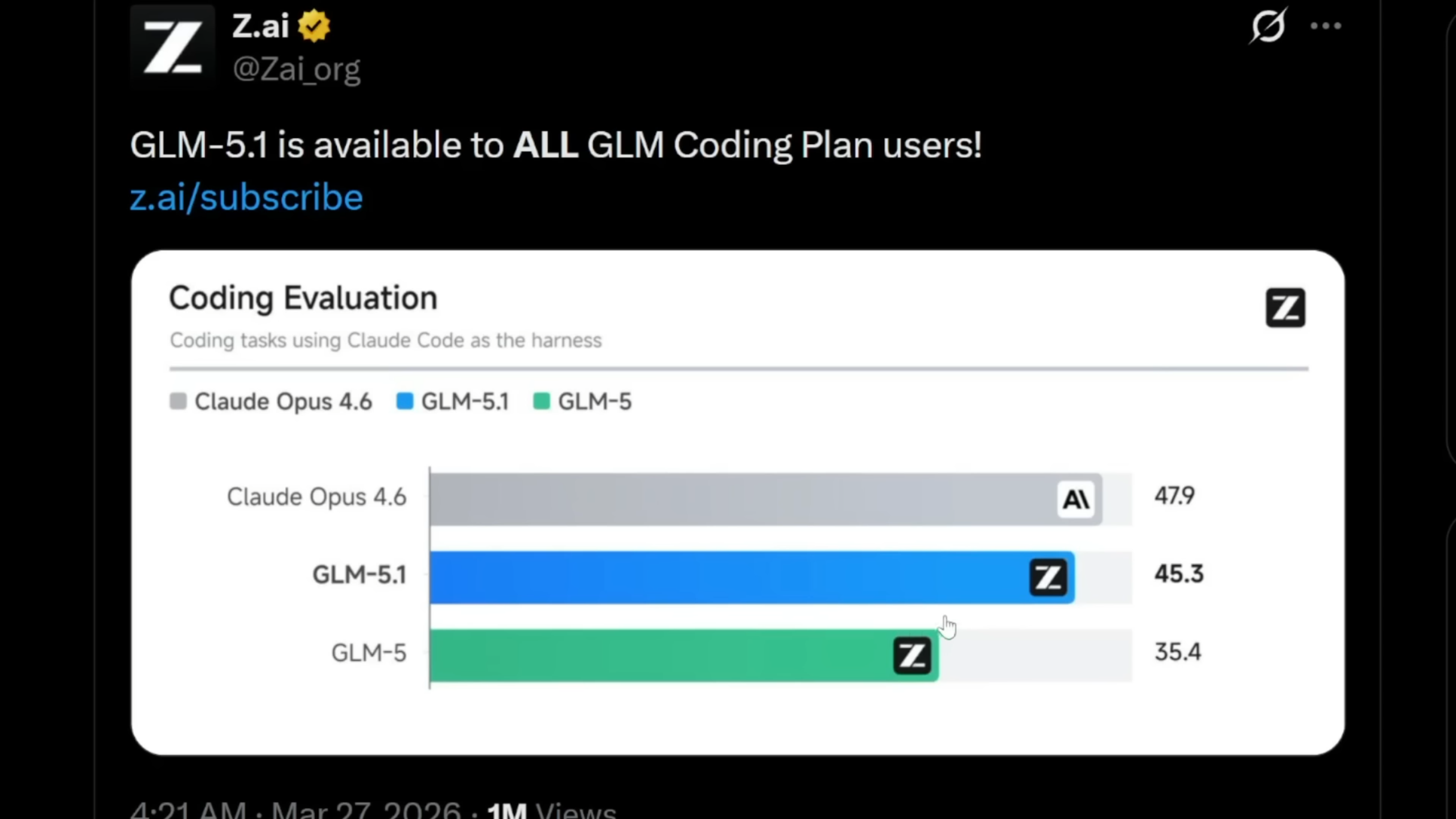
Auch wenn GLM-5.1 im ultimativen "Coding Evaluation Benchmark" noch einen Wimpernschlag hinter dem amtierenden König Claude Opus 4.6 liegt, bietet es drei immense strukturelle Vorteile, die es für Enterprise-Kunden und Indie-Entwickler gleichermaßen revolutionär machen: Es agiert signifikant schneller in der Inferenz, ist drastisch günstiger in den API-Calls und bietet deutlich großzügigere Rate-Limits. Für hochkomplexe Softwareprojekte, bei denen ein KI-Agent hunderte von iterativen Überprüfungen vornehmen muss, um einen obskuren Bug zu isolieren, definieren diese Faktoren die wirtschaftliche Machbarkeit. Die nahtlose Integration in beliebte Harness-Systeme wie "Claude Code" oder Open-Source-GUIs ist bereits live. Z.ai hat zudem angedeutet, fundamentale Teile dieser Technologie als Open Source freizugeben, was das Kräfteverhältnis auf dem Entwicklermarkt nachhaltig verschieben dürfte.
CUA Suite: Die Grundausbildung für autonome Computer-Agenten
Bleiben wir bei autonomen Agenten: Damit ein KI-System nicht nur isoliert in einem Terminal tippen kann, sondern fähig wird, ein reguläres Desktop-Betriebssystem so zu bedienen wie ein Mensch aus Fleisch und Blut, bedarf es gigantischer, extrem spezifischer Trainingsdaten. Genau diese Lücke schließt die CUA Suite (Computer Use Agents Suite). Wir sprechen hier über den ambitioniertesten, detailliertesten und größten Open-Source-Datensatz, der jemals kuratiert wurde, um Maschinen das Navigieren komplexer grafischer Benutzeroberflächen (GUIs) beizubringen.
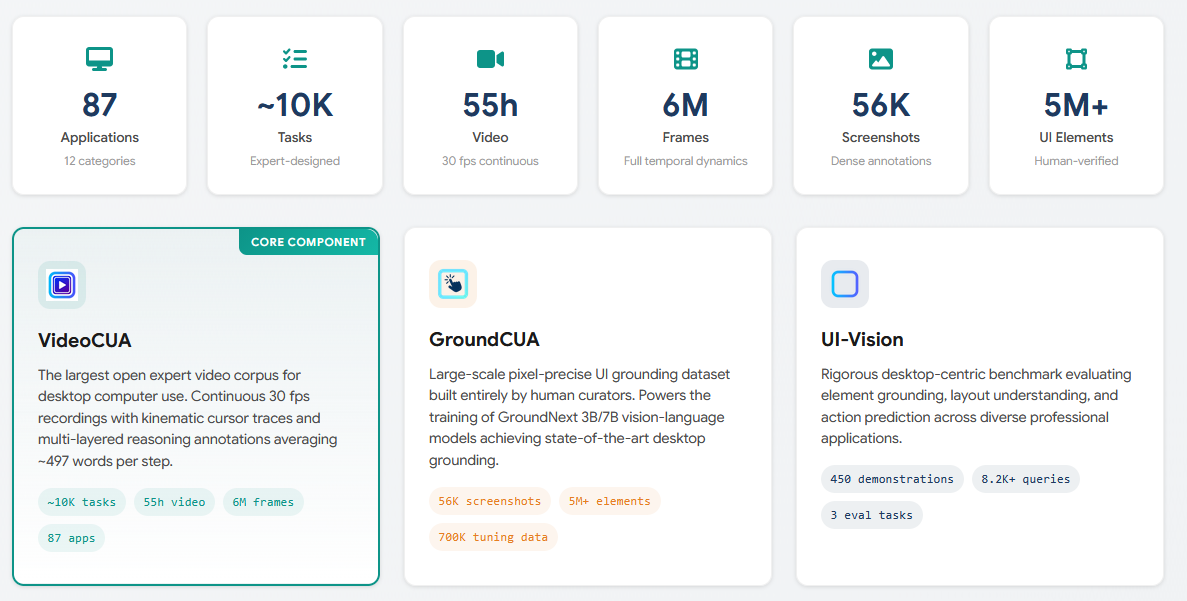
Während historische KI-Modelle allenfalls gelernt haben, via OCR statischen Text auf einem Bildschirm zu lokalisieren, liefert die CUA Suite die holistische Kinematik menschlicher Computerinteraktion. Der Datensatz enthält über 55 Stunden ultra-präzise Bildschirmaufzeichnungen in 30 fps, organisch gekoppelt mit kontinuierlichen, kinematischen Mausbewegungen (Cursor-Traces), exakten Klick-Koordinaten und Tastatur-Events. Doch das eigentliche Meisterstück sind die "Reasoning Annotations": Jeder einzelne Arbeitsschritt ist mit tiefgehenden logischen Erklärungen versehen – durchschnittlich gewaltige 497 Wörter pro ausgeführtem Klick oder Scroll-Vorgang. Die KI lernt somit nicht nur stumpf, wo sich der "Speichern"-Button befindet, sondern wie der menschliche Anwender die Maus dorthin geführt hat, wie lange er evaluierend zögerte und aus welchem strategischen Grund genau in dieser Sekunde diese spezifische Aktion ausgeführt wurde.
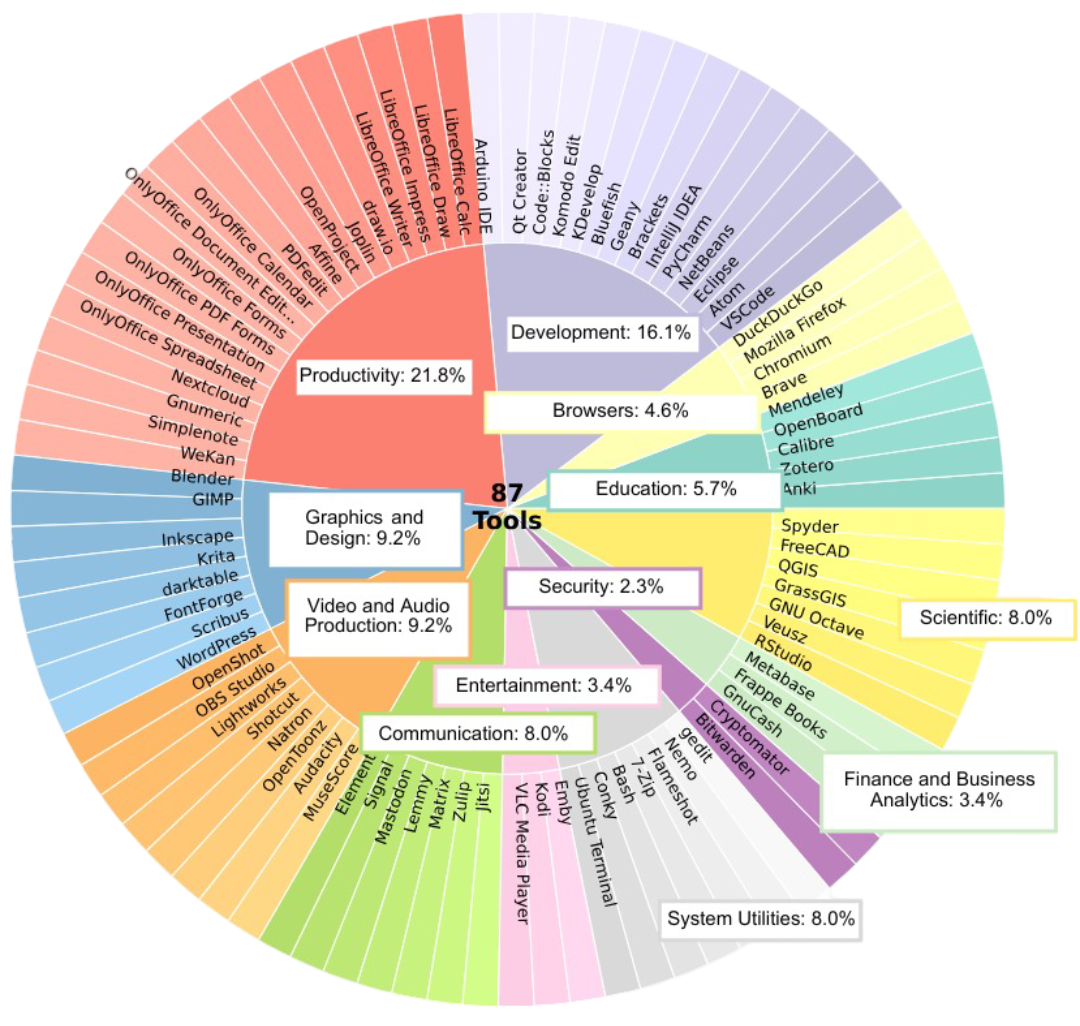
Mit über 10.000 hochkomplexen Aufgabenprofilen, die sich über 87 radikal unterschiedliche Desktop-Programme spannen, gießt dieser Datensatz das stabile Fundament für eine neue Generation digitaler Arbeiter. KI-Modelle, die mit der CUA Suite trainiert werden, können in naher Zukunft souverän E-Mails kategorisieren, vielschichtige Cross-Browser-Recherchen durchführen, fragmentierte Rohdaten in Pivot-Tabellen konsolidieren oder sogar in Software wie Adobe Premiere selbstständig Videoschnitte arrangieren – und das völlig autonom. Dass dieser unschätzbare Datenschatz, der gut 2,5-mal größer ist als alles bisher Dagewesene, der globalen Öffentlichkeit frei zugänglich gemacht wird, ist ein Katalysator für die Ära der Action-Models.
Demokratisierung von Leistung: ComfyUI Dynamic VRAM und Google Turboquant
Der wohl größte und frustrierendste Flaschenhals in der gegenwärtigen KI-Revolution ist paradoxerweise nicht die Software-Architektur, sondern pure Hardware-Limitation. Der astronomische Speicherhunger (VRAM) von State-of-the-Art-Modellen exkludiert Millionen von ambitionierten Anwendern mit handelsüblichen Workstations. Doch in dieser Woche brachen zwei technologische Innovationen diese Hardware-Mauer mit brachialer Eleganz ein.
ComfyUI Dynamic VRAM
ComfyUI, die global unangefochtene, nodenbasierte Kommandozentrale für generative Bild- und Videoprozesse, hat ein unscheinbares, aber absolut transformatives Update ausgerollt: Dynamic VRAM Management. In der Vergangenheit herrschte eine binäre Realität: Ein KI-Modell musste vollständig und am Stück in den schnellen Videospeicher (VRAM) der Grafikkarte geladen werden. Überschritt die schiere Größe der Weights die Hardware-Kapazität – beispielsweise beim Versuch, ein 32-GB-Giganten-Modell auf einer verbreiteten 16-GB-GPU auszuführen –, kollabierte der Prozess unweigerlich mit einem verheerenden "Out of Memory"-Error (OOM).
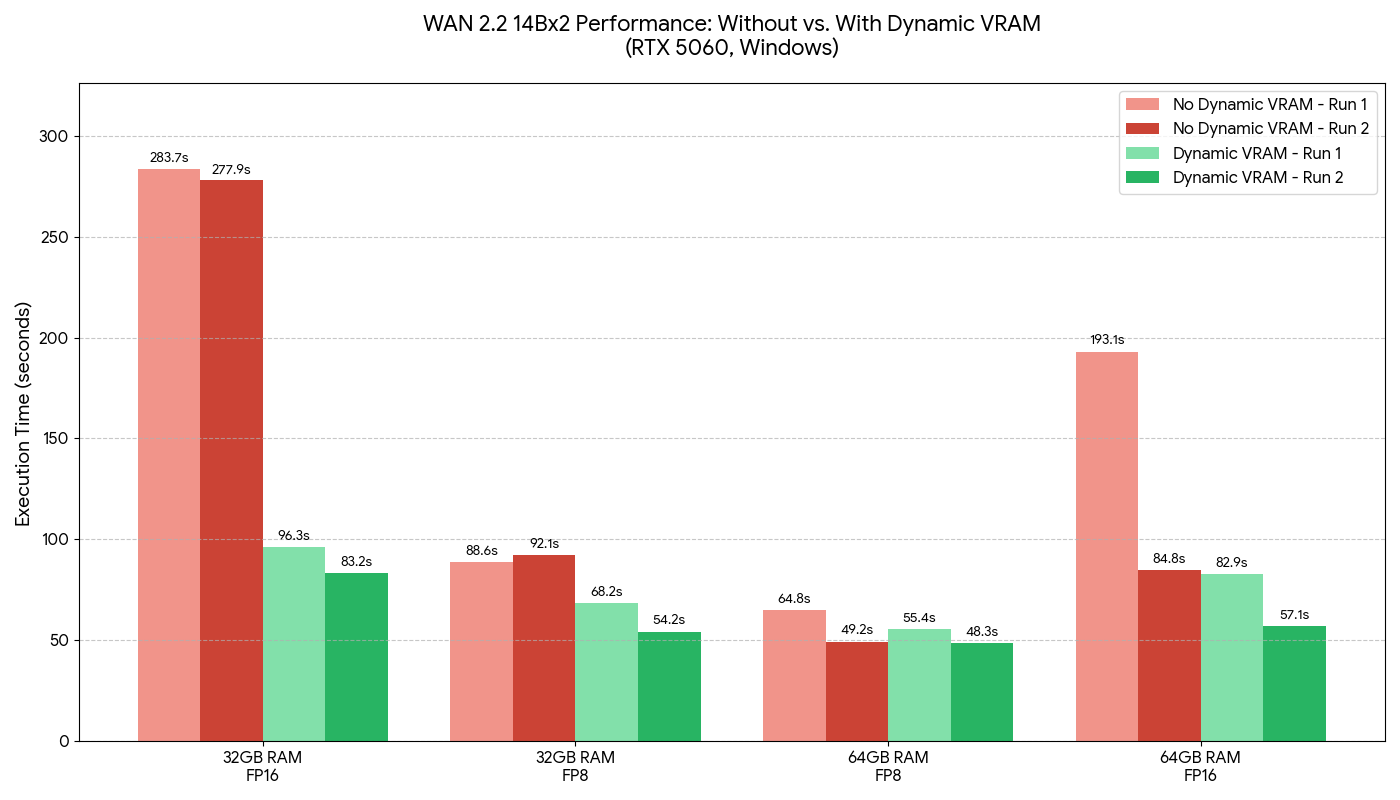
Das neue dynamische Speichersystem agiert wie ein brillanter Dirigent: Es lädt und entlädt spezifische Schichten (Layer) des neuronalen Netzes exakt nur in jenem Millisekunden-Zeitfenster in den VRAM, in dem sie mathematisch zwingend benötigt werden. Das Resultat gleicht fast schon Zauberei: Anwender können nicht nur plötzlich massivste Parameter-Modelle (wie das neue WAN 2.2 oder Flux) absolut stabil ausführen, auch die Generierungsgeschwindigkeit schießt paradoxerweise durch die Decke. Prozesse, die zuvor durch permanentes und ineffizientes Paging in den langsamen System-RAM (CPU-Memory) den Rechner stundenlang lahmlegten, werden nun intelligent asynchron orchestriert, was die Render-Zeiten in vielen Szenarien halbiert. Diese Funktion – aktuell fokussiert auf Nvidia-Karten unter Windows und Linux – bricht das Oligopol der teuren Datacenter-GPUs auf und demokratisiert höchste KI-Qualität für die breite Masse.
Google Turboquant: Die Magie der extremen Kompression
Während ComfyUI den Speicher schlau orchestriert, geht Google Research mit Turboquant das Problem an der Wurzel an: der schieren physikalischen Größe der Modelle. Klassische neuronale Netze operieren meist mit 16-Bit-Fließkommazahlen (FP16). Quantisierung zielt darauf ab, diese immense Genauigkeit auf 8-Bit, 4-Bit oder gar aberwitzige 2-Bit zu schrumpfen, um gigantische Speicherersparnisse zu erzielen. Der physikalische Preis war bisher klar: Je stärker die Kompression, desto spürbar "dümmer", halluzinierender und unpräziser wurde die KI.
Turboquant pulverisiert dieses Dogma durch eine hochkomplexe, revolutionäre Mathematik namens Polar Quant Method, die organisch mit dem fortgeschrittenen Fehlerkorrektur-Algorithmus KGL synchronisiert ist. Diese Fusion erlaubt es den Forschern, gigantische Large Language Models auf ein Sechstel (6x Kompression) ihres ursprünglichen Footprints zusammenzupressen, ohne auch nur den Hauch einer messbaren Leistungseinbuße hinzunehmen. In gnadenlosen "Needle in a Haystack"-Tests – bei denen die KI ein kryptisches, winziges Detail in einem 100.000-Wörter-Dokument extrahieren muss – bleibt das Modell gestochen scharf und fehlerfrei. Mehr noch: Turboquant beschleunigt die Inferenz (Data Retrieval) um das bis zu Achtfache. Dies ist kein reines Labor-Experiment; es ist der finale Schlüssel, um vollumfängliche, brillante KI-Modelle schon morgen nativ und ohne Cloud-Anbindung lokal auf dem Smartphone in unserer Hosentasche auszuführen.
Weltenbau, Echtzeit-Audio und Robotik: Wenn die digitale Illusion physisch wird
Die Art und Weise, wie Künstliche Intelligenz digitale Räume konstruiert, physikalische Gesetzmäßigkeiten interpretiert und schlussendlich in die analoge Welt überführt, hat in den letzten Tagen einen regelrechten Quantensprung vollzogen. Wir blicken nicht mehr nur auf generierte, flache 2D-Pixel. Wir betrachten voll interaktive, kohärente Räume, spüren korrekte Tonalität und erleben Maschinen, die auf unsere Worte mit physischer Aktion antworten.
Interaktive 3D-Welten aus dem puren Nichts
Systeme wie Matrix Game 3.0 von Skywork AI sprengen das konventionelle Verständnis von "Video-Generierung". Matrix Game generiert keine abgeschlossenen MP4-Dateien; es fungiert als interaktiver, spielbarer Welt-Simulator. Basierend auf einem hochgradig effizienten 5-Milliarden-Parameter-Modell erzeugt es in flüssiger Echtzeit (40 fps bei 720p-Auflösung) eine endlose 3D-Umgebung, die unmittelbar auf klassische Game-Eingaben (W-A-S-D-Tasten und Mausbewegungen) reagiert. Das entscheidende architektonische Meisterstück hierbei ist das implementierte Long-Term Memory Modul. Bei bisherigen generativen Modellen schmolz die Welt hinter dem Betrachter quasi dahin; drehte man sich um, war alles verändert. Matrix Game verankert Objekte permanent in einem konsistenten Raum-Zeit-Gefüge. Ein Objekt bleibt dort, wo man es abgelegt hat.
Dieser Trend zum hyperrealistischen Weltenbau wird kongenial durch Meta's Real Master Projekt flankiert. Real Master adressiert ein massives Problem der KI-Industrie: Den Mangel an hochqualitativen Videodaten für das Training von autonomen Systemen (wie selbstfahrenden Autos). Das Modell nimmt künstlich wirkende, "plastikartige" Computergrafik-Renders (beispielsweise direkt aus der Engine von Grand Theft Auto) und transformiert diese in hyperrealistisches, filmisches Material, das von Kameraaufnahmen aus der echten Welt nicht mehr zu unterscheiden ist. Der Clou: Es tut dies, während die zugrundeliegende, strenge physikalische Geometrie des Spiels (Abstände, Kollisionsboxen, Schattenwürfe) auf den Millimeter exakt erhalten bleibt. Real Master überbrückt somit endgültig die "Sim-to-Real-Gap" – KIs können fortan in perfekten, künstlichen Matrix-Welten gefahrlos Autofahren lernen, um diese Erfahrung 1:1 auf die echte Straße zu übertragen.
Audio-Synchronität und latenzfreie Echtzeit-Sprache
Selbst die schönste KI-generierte Szene bricht emotional in sich zusammen, wenn sie stumm bleibt. Prism Audio nimmt sich genau dieses gravierenden Defizits an. Mit einem überraschend winzigen 518-Millionen-Parameter-Modell analysiert es die rohe Pixelbewegung eines stummen Videos und generiert dazu perfekte, physikalisch logische Soundeffekte. Fällt ein zerbrechliches Glas zu Boden, schlägt ein Skateboard auf den Asphalt oder zupft eine Hand über Gitarrensaiten – Prism Audio erkennt das Material, den Aufprallwinkel und die Intensität und generiert das exakt passende akustische Profil, welches absolut synchron zum Frame-Verlauf auf der Timeline platziert wird.
Noch atemberaubender – weil unmittelbar interaktiv – ist der Release von Googles neuer API Gemini 3.1 Flash Live. Diese Technologie terminiert endgültig das ärgerlichste Problem moderner Sprachassistenten: die unnatürliche, sekundenlange Latenz. Da Gemini ein von Grund auf multimodales Modell ist, entfällt der fehleranfällige und langsame Umweg über externe Speech-to-Text- und Text-to-Speech-Engines. Das Netz lauscht direkt dem Audio-Stream und antwortet in Echtzeit. Es versteht subtile emotionale Nuancen im menschlichen Tonfall, passt sein eigenes Sprechtempo dynamisch an, streut authentische Lacher oder "Ähms" an den korrekten Stellen ein und – was am wichtigsten ist – lässt sich fließend im Satz unterbrechen, genau wie ein menschlicher Gesprächspartner. In der Praxis bedeutet das: Man kann sich mit der KI über ein UI-Design unterhalten ("Mach diesen Button bitte eher in einem warmen Erdton"), und noch während man spricht, vollzieht die KI parallel die visuelle Änderung im Interface-Programm.
Der Ausbruch in die physische Realität: Verkörperte KI
Der finale Evolutionsschritt dieser Woche betrifft den Punkt, an dem die Künstliche Intelligenz den flachen Bildschirm endgültig verlässt und in einen physischen Körper iteriert. Das Framework Action Plan demonstriert eindrucksvoll, wie menschliche und robotische Bewegungsmuster aus simplen Text-Prompts ("Kicke nach rechts", "Verschränke die Arme") in Echtzeit synthetisiert werden. Das Geheimnis liegt in der "Future-Aware"-Architektur: Das Modell berechnet nicht nur das aktuelle Frame, sondern plant die physikalische Balance und Kinematik zukünftiger Tausendstelsekunden voraus. Im Einsatz – beispielsweise live an den agilen, humanoiden Unitree G1 Roboter gekoppelt – werden verbale Kommandos völlig verzögerungsfrei in flüssige, hochgradig ausbalancierte Körperbewegungen aus Stahl und Servomotoren übersetzt.
Und für jene, die sich nach sozialer und emotionaler physischer Interaktion sehnen, hat das renommierte chinesische Hardware-Labor Head Form den Origin F1 präsentiert. Wir sprechen hierbei nicht über blecherne Sci-Fi-Droiden, sondern über einen hyperrealistischen humanoiden Kopf mit einer lebensechten, warmen Silikonhaut. Verborgen unter dieser anthropomorphen Oberfläche verrichten 25 bis 30 hochpräzise Mikro-Aktuatoren ihren Dienst. Sie simulieren subtilste menschliche Mikromimik in Perfektion: Die Augen suchen intuitiv den stetigen, natürlichen Blickkontakt, der Kopf neigt sich empathisch zur Seite, wenn das Gegenüber spricht, und feine Muskelgruppen um Mundwinkel und Augenbrauen reagieren mikrosekundengenau und dynamisch auf den emotionalen Verlauf des Gesprächs. Ein Blick in das Antlitz des Origin F1 ist gleichermaßen ein Wunderwerk der Technik wie ein tiefer Trip in das Uncanny Valley – und der ultimative Beweis, dass KI nicht nur unsere Arbeit, sondern auch unser Bedürfnis nach Gesellschaft tiefgreifend umstrukturieren wird.
Fazit: Eine Branche im unaufhaltsamen Hyper-Drive
Die massiven tektonischen Verschiebungen dieser Woche unterstreichen ein unumstößliches Faktum: Der Fortschritt in der Künstlichen Intelligenz ist nicht mehr linear messbar, er verläuft in einer brutalen Exponentialkurve. Während etablierte Titanen wie OpenAI strategisch rigoros umstrukturieren, unrentable Consumer-Spielzeuge wie Sora abstoßen und den scharfen Fokus auf tiefgreifende physikalische Modelle und hochprofitable Enterprise-Lösungen richten, stürmt die globale Open-Source-Community mit gewaltiger Innovationskraft nach vorne und füllt jedes noch so kleine Vakuum in Rekordzeit aus.
Wir erleben eine faszinierende Konvergenz der Disziplinen: Modelle simulieren unsere innersten Gehirnaktivitäten, während andere auf dem heimischen PC dank revolutionärem VRAM-Management gigantische grafische Universen entwerfen. Gleichzeitig erwachen Maschinen aus Stahl und Silikon durch Latenzfreiheit und Action-Frameworks zu echtem Leben. Wer die schwindelerregende Geschwindigkeit dieser Evolution in ihrer vollen audiovisuellen Pracht nachvollziehen möchte, dem sei ein vertiefender Blick in kuratierte Expertenformate wärmstens empfohlen, wie etwa in den exzellenten Branchenüberblick von AI Search. Eines ist bei all diesen Durchbrüchen gewiss: Die Werkzeuge, Algorithmen und digitalen Begleiter, die uns schon morgen zur Verfügung stehen werden, sprengen alles, was wir heute für möglich halten. Es liegt nun an uns, als Gesellschaft, Entwickler und Anwender, dieses titanische Potenzial verantwortungsvoll, ethisch und visionär zu lenken.
 ZS Studio - Ihr Partner für erstklassige Webentwicklung
ZS Studio - Ihr Partner für erstklassige WebentwicklungIn einer digitalen Welt, die sich ständig weiterentwickelt, ist eine leistungsstarke und skalierbare Website das Fundament Ihres Unternehmenserfolgs. Wir unterstützen Unternehmen dabei, technologische Hürden zu überwinden und digitale Erlebnisse zu schaffen, die sowohl technisch als auch strategisch überzeugen.
Suchen Sie nach einem erfahrenen Partner für Ihr nächstes Web-Projekt? Erfahren Sie mehr über unsere Leistungen auf unserer Unternehmenswebsite oder vereinbaren Sie direkt ein unverbindliches Erstgespräch für eine kostenlose Website-Analyse über unser Kontaktformular.
Lassen Sie uns gemeinsam Ihre digitale Präsenz auf das nächste Level heben.