
Wir erleben gegenwärtig nicht weniger als die Geburtsstunde einer neuen technologischen Ära: Den Übergang von der rein reaktiven Künstlichen Intelligenz hin zu proaktiven, autonom handelnden Agenten-Systemen, die auf einer spezialisierten Hardware-Infrastruktur operieren, die jede bisherige Vorstellung von Rechenleistung sprengt. Mit der Vorstellung von MiniMax M2.7, der bahnbrechenden Reasoning-Engine MiroThinker und der massiven Rechenpower von NVIDIAs Groq 3 LPX-Plattform verschmelzen Software-Intelligenz und Hardware-Effizienz zu einer Einheit, die die digitale Wertschöpfung für immer verändern wird.
Die Architektur der Autonomie: MiniMax M2.7 und das Zeitalter der Agent-Harnesses
In den letzten Jahren lag der Fokus der KI-Entwicklung primär auf der Skalierung von Parametern und der Verbesserung der sprachlichen Nuancen von Chatbots. Doch die Industrie hat erkannt, dass ein intelligenter Gesprächspartner allein kein Problem löst. Die wahre Herausforderung liegt in der Execution – der Fähigkeit, komplexe Pläne über lange Zeiträume hinweg fehlerfrei auszuführen. Hier tritt MiniMax M2.7 auf den Plan.
MiniMax M2.7 definiert sich nicht primär als ein weiteres Sprachmodell, sondern als ein hochspezialisierter "Agent Harness". In der Informatik beschreibt ein Harness eine Test- oder Steuerungsumgebung, die Softwarekomponenten umschließt und deren Ausführung koordiniert. Für die Welt der KI bedeutet dies: M2.7 ist das Gehirn, das in der Lage ist, eine Vielzahl von Sub-Agenten zu steuern, Werkzeuge (Tools) zu bedienen und komplexe Produktivitätsaufgaben zu bewältigen, die bisher menschliche Projektmanager erforderten.

Benchmark-Analyse: Warum M2.7 die Konkurrenz im Regen stehen lässt
Die Überlegenheit von M2.7 zeigt sich besonders deutlich in Benchmarks, die über einfache Textgenerierung hinausgehen. Während Modelle wie GPT-4 oder Claude 3.5 Opus exzellente Generalisten sind, wurde M2.7 gezielt auf "Agentic Workflows" hin optimiert. Ein Blick auf die Daten zeigt eine beeindruckende Dominanz in spezifischen Disziplinen:
- SWE-Bench Pro: Dieser Benchmark misst die Fähigkeit eines Modells, reale Software-Probleme in GitHub-Repositories zu lösen. M2.7 erzielt hier Ergebnisse, die deutlich über dem Marktdurchschnitt liegen und zeigt eine enorme Stabilität bei der Code-Generierung und Fehlerbehebung.
- MLE-Bench lite: Hier geht es um Machine Learning Engineering Aufgaben. M2.7 beweist, dass es nicht nur Code schreiben, sondern auch komplexe mathematische Modelle verstehen und implementieren kann.
- Toolathlon: Wie der Name vermuten lässt, wird hier die Fähigkeit getestet, eine Vielzahl von externen Werkzeugen (APIs, Datenbanken, Browser) in der richtigen Reihenfolge und mit den korrekten Parametern zu nutzen.
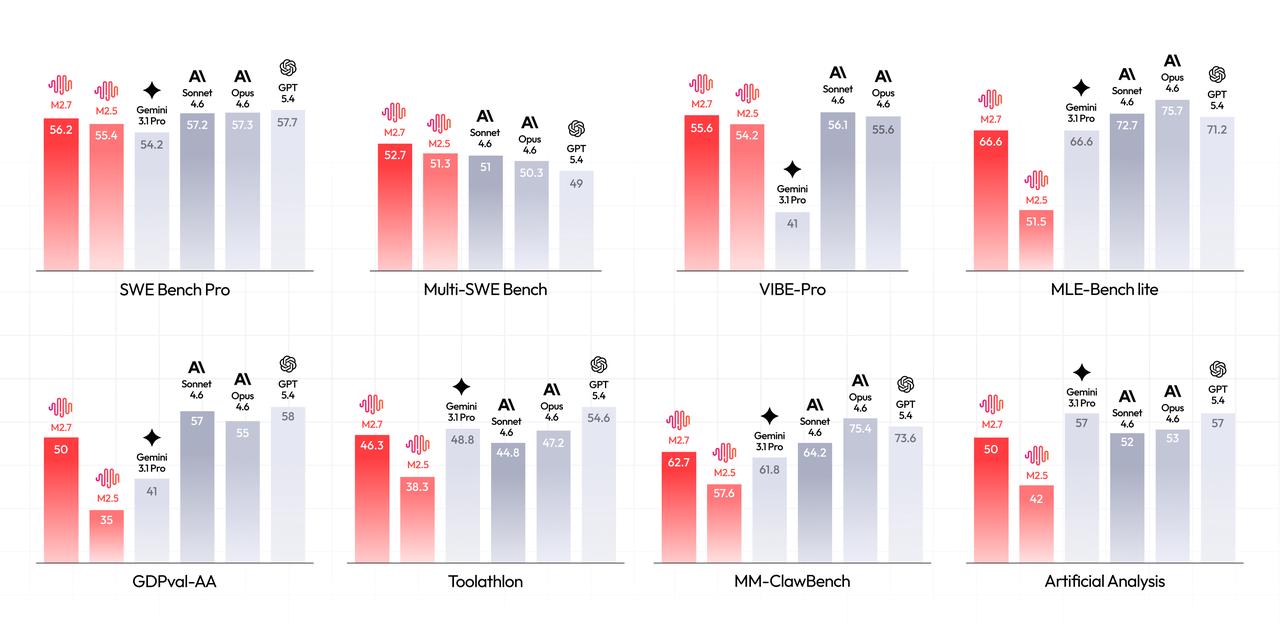
Besonders bemerkenswert ist das Abschneiden im GDPval-AA und MM-ClawBench. Diese Tests simulieren Umgebungen, in denen Agenten unter Zeitdruck und mit begrenzten Ressourcen Entscheidungen treffen müssen. M2.7 zeigt hier eine deutlich geringere Fehlerrate als seine Vorgänger, was es für den Unternehmenseinsatz in kritischen Infrastrukturen prädestiniert.
Reasoning 2.0: MiroThinker und die Kunst des methodischen Denkens
Während MiniMax die Ausführung perfektioniert, setzt MiroThinker (in den Versionen 1.7 und H1) bei der Qualität des Denkprozesses an. Wir sprechen hier von "Reasoning-Modellen". Im Gegensatz zu Standard-LLMs, die das wahrscheinlichste nächste Token basierend auf statistischen Mustern vorhersagen, nutzen Reasoning-Modelle einen internen Chain-of-Thought (CoT) Mechanismus.
Stellen Sie sich vor, Sie bitten eine KI, eine komplexe physikalische Formel herzuleiten. Ein Standardmodell "rät" das Ergebnis fast sofort. Ein Reasoning-Modell wie MiroThinker-H1 hält inne, simuliert verschiedene Rechenwege intern, prüft Zwischenergebnisse auf Logik und präsentiert erst dann die finale Lösung. Dies wird oft als "System 2 Thinking" bezeichnet – ein Begriff aus der Psychologie, der langsames, bewusstes und logisches Denken beschreibt.
Wissenschaftliche Exzellenz und Deep Research
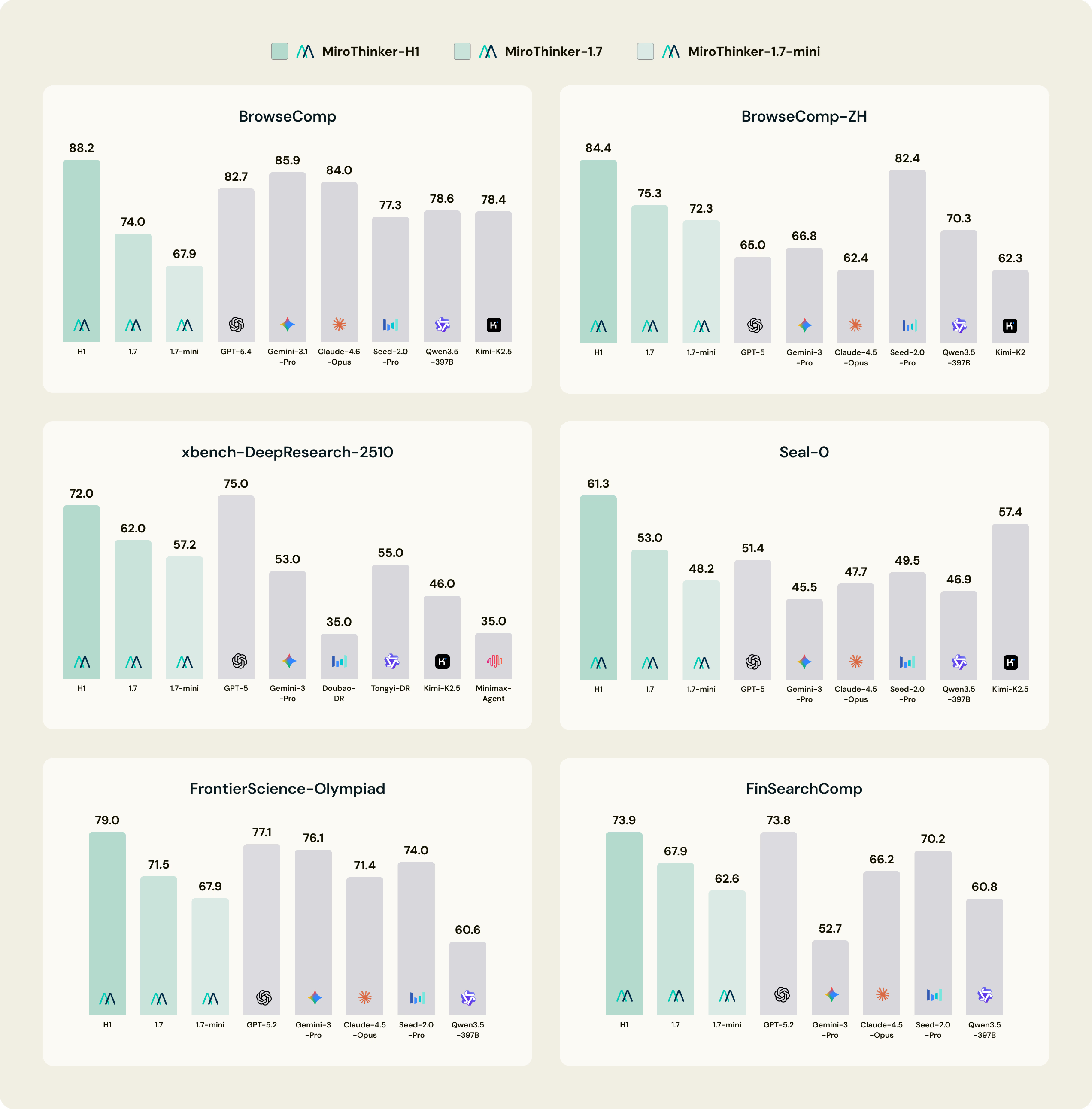
Die Benchmarks für MiroThinker-H1 sind atemberaubend. In Disziplinen wie der Frontier Science Olympiad oder BrowseComp (ein Test für komplexe Web-Recherche und Informationssynthese) lässt das Modell die bisherigen Marktführer hinter sich. Besonders im Bereich xbench-DeepResearch-2510 zeigt sich, dass MiroThinker in der Lage ist, hunderte von Quellen zu sichten, deren Validität zu prüfen und daraus hochgradig korrekte wissenschaftliche Arbeiten zu erstellen.
Der Financial Case: Präzision als Wettbewerbsvorteil
Um die theoretische Überlegenheit in die Praxis zu übersetzen, lohnt ein Blick auf die Goldpreis-Vorhersage von MiroThinker-1.7. In einem realen Testszenario am 10. Februar 2026 wurde das Modell gebeten, den Goldpreis für den 25. Februar vorherzusagen. Das Ergebnis war eine Punktlandung: Mit einer Fehlerrate von lediglich 0,08% (eine Abweichung von nur 4 Dollar bei einem Preis von über 5.000 Dollar) bewies MiroThinker, dass Reasoning-Fähigkeiten direkt in monetäre Vorteile transformiert werden können.

Wer in volatilen Märkten bestehen will, kann sich nicht mehr auf Glück verlassen. MiroThinker liefert die mathematische Gewissheit, die für moderne Handelsstrategien unerlässlich ist.
Analysten-Bericht, Fintech-Forum 2026
Das Hardware-Fundament: NVIDIA Groq 3 LPX und die Rubin-Roadmap
Software-Intelligenz benötigt einen Körper, um agieren zu können. In der Welt der KI ist dieser Körper das Rechenzentrum. NVIDIA hat mit der Ankündigung des Groq 3 LPX Compute Trays klargestellt, dass die Ära der Standard-GPUs für die Inferenz (die Anwendung von KI) zu Ende geht. Wir treten ein in das Zeitalter der LPUs (Language Processing Units).
Das Groq 3 LPX System ist ein technisches Meisterwerk. Es handelt sich um ein 1U-Server-Modul, das vollständig flüssigkeitsgekühlt ist. Diese Kühlung ist notwendig, da das System eine enorme Packungsdichte aufweist: 8 NVIDIA Groq 3 LPUs arbeiten in einem einzigen Tray zusammen. Der entscheidende Unterschied zur klassischen GPU liegt in der Latenz. Während GPUs auf den Durchsatz (viele Aufgaben gleichzeitig) optimiert sind, ist die LPU auf Geschwindigkeit (eine Aufgabe so schnell wie möglich) getrimmt. Für einen Agenten, der in Echtzeit auf eine menschliche Eingabe reagieren muss, ist dies der entscheidende Faktor.

Konnektivität ohne Grenzen: 400 Gb/s und C2C Optical Links
Rechenleistung allein reicht nicht aus, wenn die Daten nicht schnell genug fließen können. NVIDIA verbaut im Groq 3 Tray modernste Netzwerktechnologie. Mit 32 LPU C2C Optical Links und 400 Gb/s Ethernet-Anschlüssen wird sichergestellt, dass die Kommunikation zwischen den einzelnen Chips und über Server-Racks hinweg ohne spürbare Verzögerung stattfindet. Das System nutzt BlueField-4 DPUs (Data Processing Units), um den Hauptprozessor (CPU) von Netzwerkaufgaben zu entlasten, wodurch die volle Kapazität für die KI-Modelle reserviert bleibt.
Der Weg zu Rubin: NVIDIAs Vision eines globalen Gehirns
Doch Groq 3 ist nur ein Zwischenschritt. NVIDIA-Chef Jensen Huang präsentierte kürzlich die Rubin-Architektur. Benannt nach der Astronomin Vera Rubin, soll diese Generation die Grenzen zwischen Speicher und Rechenkern endgültig aufheben. In der Rubin-Vision besteht ein Supercomputer nicht mehr aus einzelnen Servern, sondern fungiert als eine einzige, gigantische logische Einheit.

Dieses Hardware-Ökosystem ist die Voraussetzung dafür, dass Modelle wie MiniMax M2.7 ihr volles Potenzial entfalten können. Ohne die extrem niedrigen Latenzzeiten der LPUs würden komplexe Agenten-Ketten sekundenlang pausieren müssen, was die Interaktion unnatürlich und ineffizient machen würde.
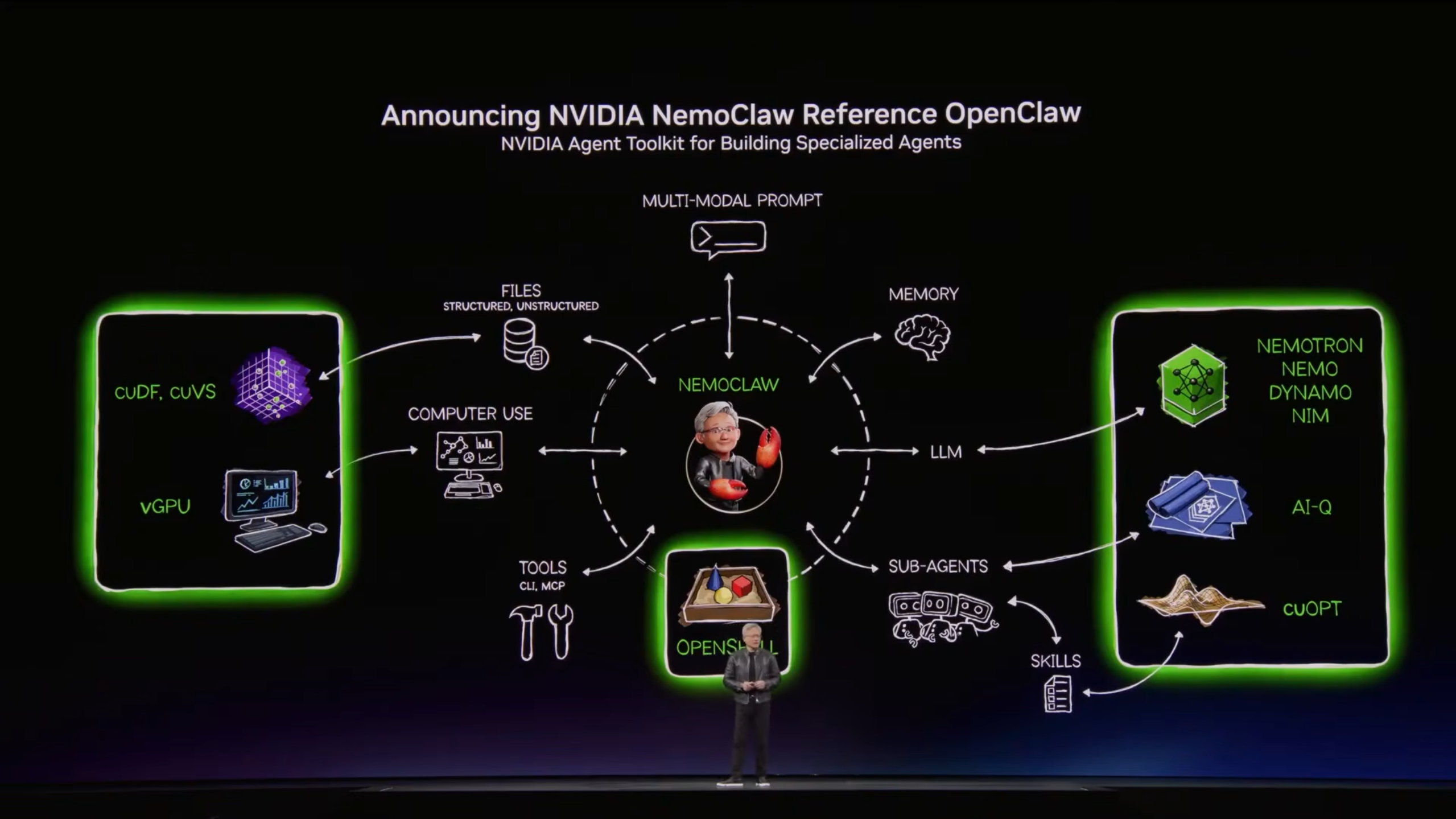
NemoClaw: Das Betriebssystem für die neue Agenten-Welt
Um die Brücke zwischen der massiven Hardware und den intelligenten Modellen zu schlagen, hat NVIDIA NemoClaw (basierend auf der OpenClaw-Referenz) vorgestellt. Man kann NemoClaw als eine Art "Agenten-Toolkit" oder "Betriebssystem für Agenten" bezeichnen. Es ermöglicht Entwicklern, spezialisierte KIs zu bauen, die Zugriff auf tiefe Systemressourcen haben.
Ein NemoClaw-Agent ist nicht auf Text beschränkt. Er kann:
- vGPUs nutzen: Für komplexe visuelle Analysen oder 3D-Rendering direkt im Workflow.
- cuDF und cuVS einsetzen: Diese Bibliotheken erlauben es, massive Datensätze direkt auf der GPU zu verarbeiten und zu visualisieren.
- Computer Use: Der Agent kann – ähnlich wie ein Mensch – eine grafische Benutzeroberfläche (GUI) bedienen, Schaltflächen klicken und Dokumente per Drag-and-Drop verschieben.
- cuOPT Integration: Für logistische Optimierungsprobleme in Echtzeit (z.B. Routenplanung oder Ressourcenverteilung).
Branchenspezifische Revolutionen: Bildung und Medien
Während die oben genannten Technologien das Fundament bilden, sehen wir bereits die ersten spezialisierten Anwendungen, die ganze Industrien transformieren. Zwei herausragende Beispiele sind OpenMAIC und SparkVSR.
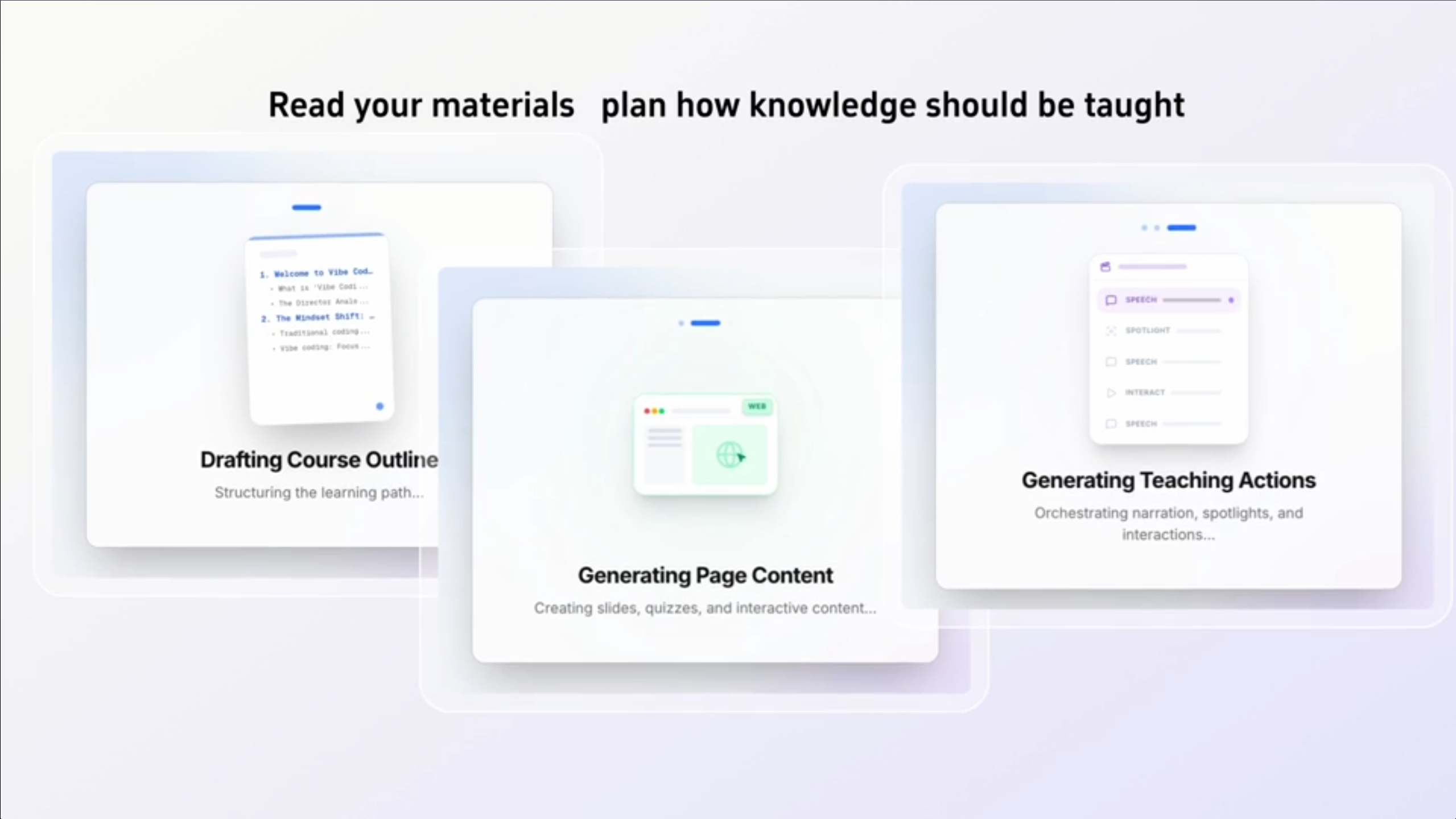
OpenMAIC: Die Demokratisierung des Wissens
Die Erstellung von hochwertigen Online-Kursen war bisher ein Prozess, der Wochen oder Monate dauerte. OpenMAIC automatisiert diesen Prozess vollständig. Das System ist in der Lage, rohe Materialien (Bücher, Whitepaper, Videos) zu lesen, eine logische Kursstruktur zu entwerfen und autonom den gesamten Inhalt zu generieren – inklusive Folien, Quizzes und interaktiven Elementen.
Dies ist ein Paradigmenwechsel für die betriebliche Weiterbildung. Wissen kann nun in Echtzeit "verdaubar" gemacht werden. Wenn sich eine Technologie heute ändert, kann OpenMAIC bis morgen einen kompletten Schulungskurs für die gesamte Belegschaft erstellen.
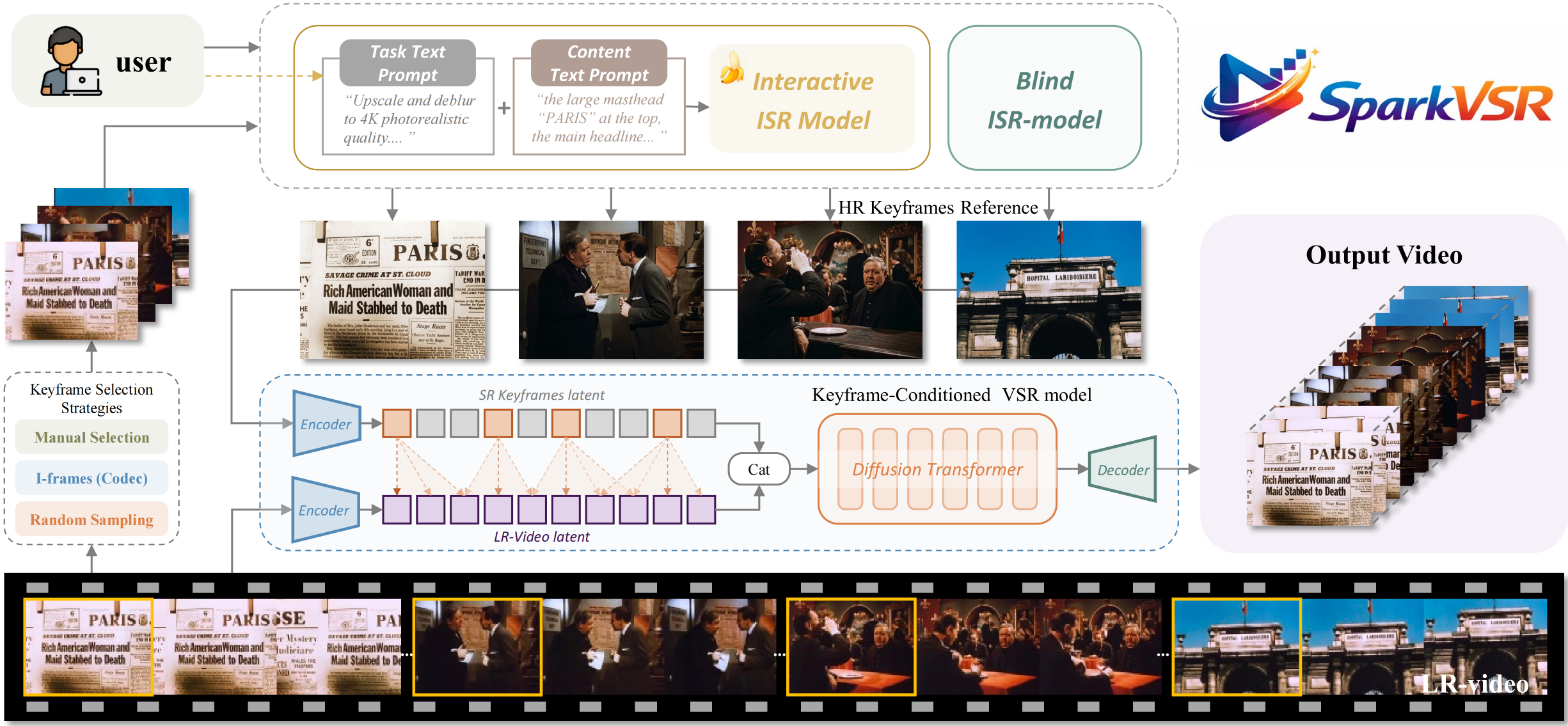
SparkVSR: Fotorealismus für die Ewigkeit
In der Welt der Medien ist Auflösung alles. Doch viel wertvolles historisches Material oder auch aktuelles Videomaterial aus Überwachungskameras liegt nur in niedriger Qualität vor. SparkVSR (Video Super-Resolution) löst dieses Problem mit einer Brillanz, die bisher unmöglich schien.
Im Gegensatz zu einfachen Upscalern nutzt SparkVSR einen Diffusion Transformer. Das Modell "versteht", was es sieht. Wenn es ein altes, verrauschtes Video einer Pariser Straße hochskaliert, weiß es, wie die Textur von Kopfsteinpflaster oder die Typografie historischer Schilder aussehen sollte. Es generiert keine Pixel hinzu, es rekonstruiert die Realität basierend auf seinem tiefen Verständnis der Welt.

Technisch gesehen basiert SparkVSR auf einem komplexen Framework, das Keyframes zur Referenz nutzt und die Information über die Zeit hinweg (Temporal Consistency) stabil hält. So wird das typische "Flackern" verhindert, das man von vielen KI-generierten Videos kennt.
Strategisches Fazit: Wie Sie sich auf die KI-Zukunft vorbereiten
Wir haben gesehen, dass KI im Jahr 2026 kein Spielzeug mehr ist. Es ist ein hochpräzises Werkzeug für Forschung, Finanzen, Ingenieurswesen und Bildung. Die Kombination aus Reasoning (MiroThinker), Execution (MiniMax M2.7) und Infrastruktur (NVIDIA Groq 3) schafft eine Dynamik, der sich kein Unternehmen entziehen kann.
Die Gewinner der nächsten Jahre werden diejenigen sein, die aufhören, KI nur als "besseres Google" zu betrachten. Stattdessen müssen wir lernen, Agenten-Harnesses zu bauen und zu steuern. Wir müssen verstehen, dass Rechenkapazität das neue Gold ist und dass Präzision in der Vorhersage (wie bei den Goldpreis-Modellen) den entscheidenden Marktvorteil liefert.
Die technologische Basis ist bereit. Die Hardware ist im Rack, die Modelle sind geladen. Es liegt nun an uns, diese beispiellose Macht verantwortungsvoll und kreativ einzusetzen, um die komplexen Herausforderungen unserer Zeit zu lösen.
 ZS Studio - Ihr Partner für erstklassige Webentwicklung
ZS Studio - Ihr Partner für erstklassige WebentwicklungIn einer digitalen Welt, die sich ständig weiterentwickelt, ist eine leistungsstarke und skalierbare Website das Fundament Ihres Unternehmenserfolgs. Wir unterstützen Unternehmen dabei, technologische Hürden zu überwinden und digitale Erlebnisse zu schaffen, die sowohl technisch als auch strategisch überzeugen.
Suchen Sie nach einem erfahrenen Partner für Ihr nächstes Web-Projekt? Erfahren Sie mehr über unsere Leistungen auf unserer Unternehmenswebsite oder vereinbaren Sie direkt ein unverbindliches Erstgespräch für eine kostenlose Website-Analyse über unser Kontaktformular.
Lassen Sie uns gemeinsam Ihre digitale Präsenz auf das nächste Level heben.