
Wir befinden uns in einer Phase der technologischen Evolution, in der der Begriff "atemberaubend" fast schon wie eine Untertreibung wirkt. Woche für Woche verschieben Forscher und Entwickler die Grenzen dessen, was künstliche Intelligenz leisten kann – von der hochpräzisen Videofreistellung über interaktive 3D-Welten bis hin zu völlig neuen Paradigmen im digitalen Marketing. Wenn wir einen Schritt zurücktreten und die schiere Flut an Innovationen betrachten, wird eines klar: KI ist längst nicht mehr nur ein Werkzeug für Textgenerierung. Sie ist der neue Motor für räumliches Verständnis, multimodale Verarbeitung und hyperpersonalisierte Erfahrungen. In diesem tiefgehenden Artikel werfen wir einen detaillierten Blick auf die bahnbrechendsten KI-Entwicklungen der letzten Tage und analysieren, wie sie unsere Arbeits- und Alltagswelt nachhaltig verändern werden.
Google Maps betritt das KI-Zeitalter: Ask Maps & Immersive Navigation
Navigation war gestern – heute sprechen wir von intelligentem räumlichen Bewusstsein. Google hat tiefgreifende KI-Funktionen in Google Maps integriert, die weit über die einfache Routenplanung hinausgehen. Die App verwandelt sich zunehmend in einen proaktiven, kontextsensitiven Assistenten.
Ask Maps: Der intelligente Reisebegleiter
Die erste große Neuerung nennt sich Ask Maps. Stellen Sie sich vor, Sie haben einen KI-Chatbot direkt in Ihrer Navigations-App, der Zugriff auf Milliarden von Fotos, Echtzeit-Verkehrsdaten, Unternehmensinformationen und Nutzerbewertungen hat. Anstatt nach generischen Kategorien wie "Restaurants" zu suchen, können Nutzer nun hochspezifische Anfragen im natürlichen Dialog stellen. Eine Frage wie "Finde ein gemütliches, ästhetisches Café mit guten veganen Optionen in meiner Nähe" liefert nicht nur eine Liste, sondern maßgeschneiderte Empfehlungen, bei denen die KI die Rezensionen liest, Schlüsselaspekte zusammenfasst und begründet, warum dieser Ort perfekt zur Suchanfrage passt.
Darüber hinaus lassen sich ganze Reisepläne erstellen. Ein Prompt wie "Plane einen Wochenendtrip in die Berge für mich" generiert ein vollständiges Itinerary – inklusive Routenplanung, Sehenswürdigkeiten und Aktivitäten, die dynamisch an die aktuellen Gegebenheiten angepasst sind.
Immersive Navigation: Die Zukunft der Wegführung
Ein weiteres Highlight ist die Immersive Navigation, die durch Gemini-Modelle angetrieben wird. Wer kennt es nicht: Man fährt auf einer mehrspurigen Autobahn, das GPS sagt "links abbiegen in 300 Metern", aber man hat keine Ahnung, welche der fünf Spuren die richtige ist. Die Immersive Navigation löst dieses Problem mit einer hyperrealistischen 3D-Ansicht. Gebäude, Überführungen, Terrains und exakte Fahrspuren werden visuell so aufbereitet, dass der Fahrer vorausschauend agieren kann. Das System warnt nicht nur vor dem nächsten Abbiegemanöver, sondern bereitet den Fahrer auch auf kurz darauffolgende, komplexe Verkehrsführungen vor.
MatAnyone 2: Die Revolution in der Video-Freistellung
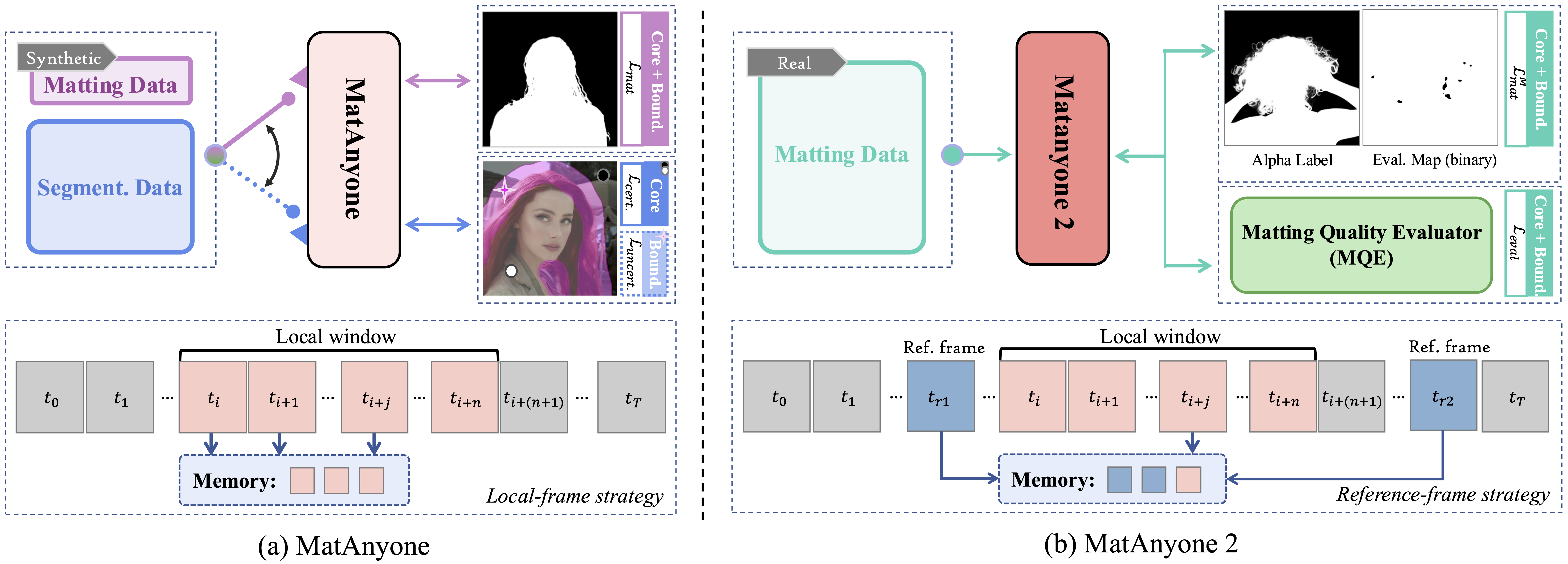
Jeder, der schon einmal in der Videoproduktion gearbeitet hat, weiß: Rotoskopierung und das Freistellen von Personen (Matting) gehören zu den mühsamsten und zeitaufwendigsten Aufgaben überhaupt. Besonders wenn schnelle Bewegungen, unscharfe Hintergründe oder komplexe Haarstrukturen im Spiel sind, stoßen klassische Algorithmen schnell an ihre Grenzen. Hier tritt MatAnyone 2 auf den Plan und setzt einen völlig neuen Standard.
Präzision auf Pixel-Ebene
MatAnyone 2 ist in der Lage, jede beliebige Person aus einem Video extrem sauber vom Hintergrund zu separieren. Selbst bei hektischen Tanzszenen oder hochdynamischen Actionaufnahmen erstellt das Modell eine akkurate Maske (Alpha Channel). Besonders beeindruckend ist die Handhabung von feinen Details wie wehenden Haaren. Im direkten Vergleich mit bisherigen Branchenstandards wie GVM (Grounded Video Matting) zeigt MatAnyone 2 eine drastisch höhere Auflösung und Kantenschärfe. Wo bei älteren Modellen die Haare zu einem verpixelten Brei verschwimmen, liefert MatAnyone 2 gestochen scharfe Transparenzwerte.

Das Modell ist dabei nicht auf reale Personen beschränkt. Es funktioniert ebenso makellos bei 3D-Renderings, Pixar-ähnlichen Charakteren und Szenen mit mehreren Personen. Mit nur wenigen Klicks in der Benutzeroberfläche lässt sich die Zielperson markieren, den Rest erledigt die KI.
Leichtgewichtig und Open Source
Trotz dieser enormen Leistungsfähigkeit ist das zugrunde liegende Modell erstaunlich kompakt. Mit einer Größe von nur etwa 140 Megabyte lässt es sich problemlos lokal ausführen. Die Entwickler haben den gesamten Code auf GitHub Open Source gestellt, komplett mit Anleitungen zur lokalen Installation. Für schnelle Tests steht zudem eine Hugging Face Space zur Verfügung.
ComfyUI App Mode: Komplexe Workflows endlich nutzerfreundlich
ComfyUI hat sich in der Open-Source-Community als der De-facto-Standard für bildgenerierende KI-Modelle wie Stable Diffusion oder Flux etabliert. Das knotenbasierte (node-based) System bietet unendliche Flexibilität. Doch diese Macht hat einen Preis: Die Benutzeroberfläche degeneriert bei komplexen Workflows oft zu einem unübersichtlichen "Spaghetti-Code" aus Kabeln und Boxen, der für Einsteiger absolut abschreckend wirkt.
Dieses Problem wird nun durch den neuen App Mode gelöst. Diese Funktion ist ein Paradigmenwechsel für die Demokratisierung von KI-Tools.
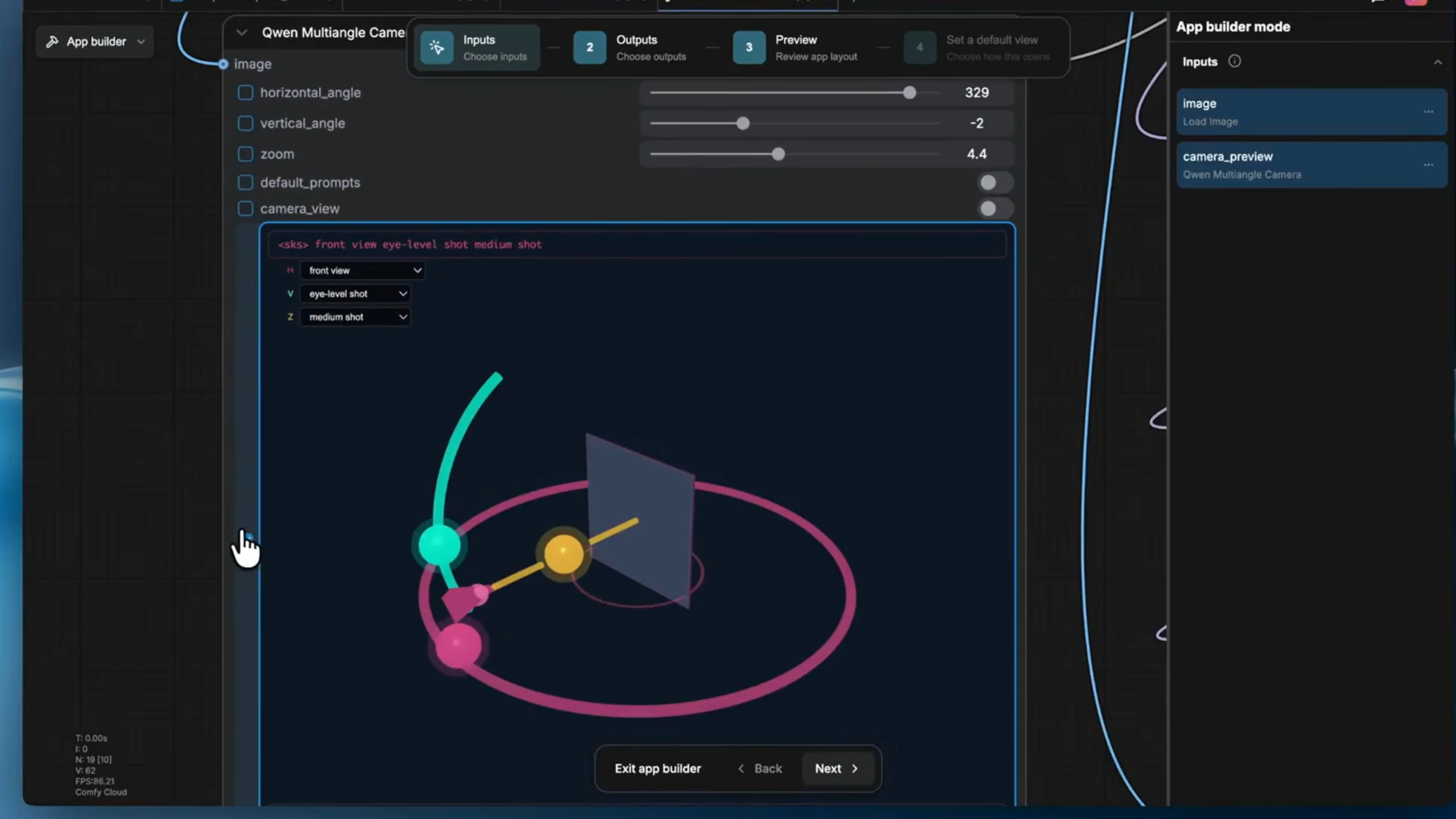
Von Nodes zur sauberen App
Der App Mode ermöglicht es Erstellern von Workflows, ihr komplexes Knoten-Geflecht in eine saubere, intuitive Benutzeroberfläche zu verpacken. Als Entwickler eines Workflows wählt man lediglich aus, welche Nodes als Eingabe (Inputs) für den Nutzer sichtbar sein sollen – zum Beispiel ein Textfeld für den Prompt, ein Upload-Feld für ein Referenzbild oder ein Schieberegler für die Intensität. Anschließend definiert man die Ausgabeknoten (Outputs), an denen das fertige Bild oder Video erscheint.
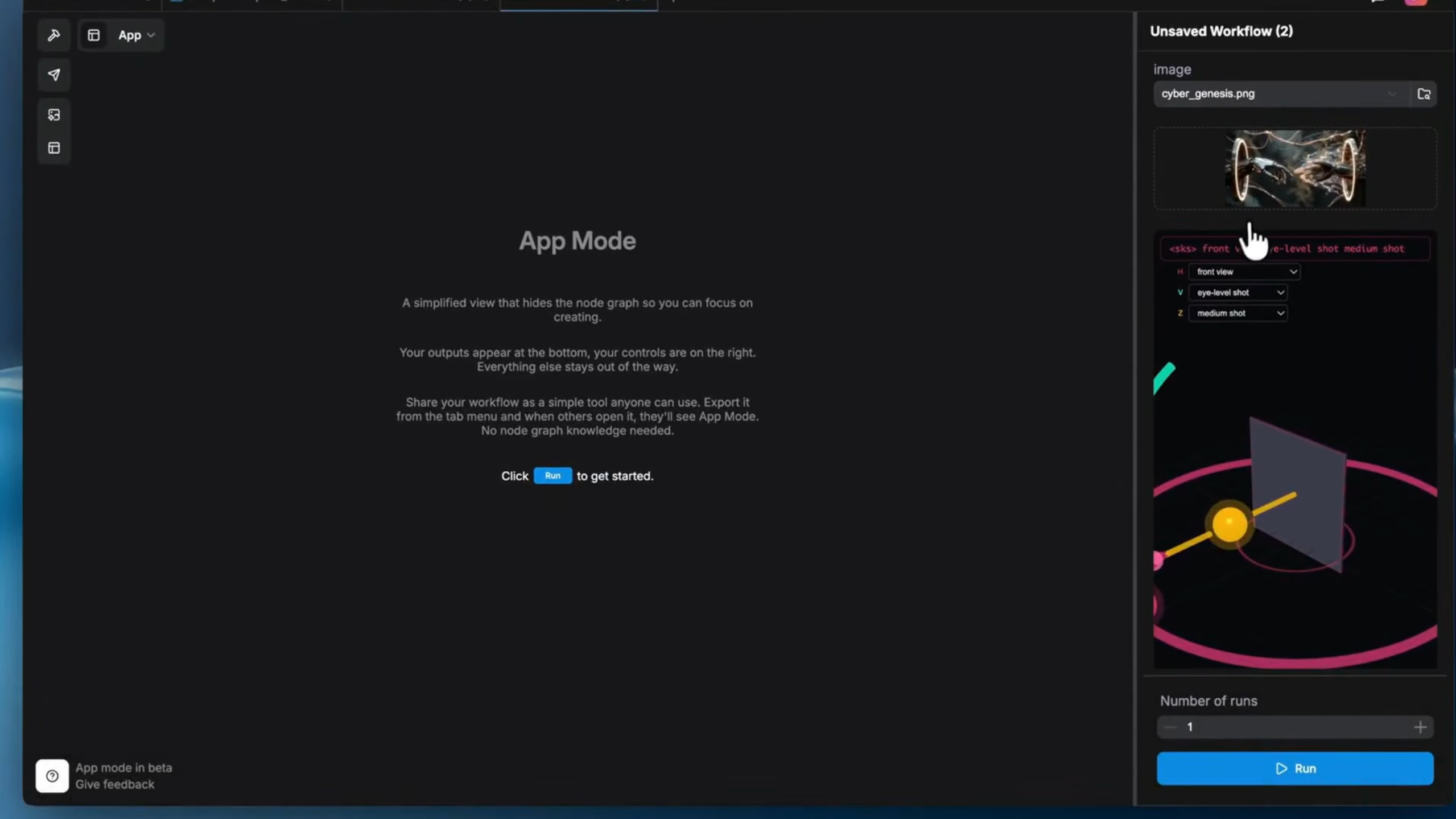
Das Resultat ist eine aufgeräumte Web-App-Ansicht, bei der auf der rechten Seite nur die relevanten Kontrollen zu finden sind, während auf der linken Seite die Ergebnisse generiert werden. Das technische Chaos im Hintergrund bleibt komplett verborgen. Dies ermöglicht es, hochentwickelte KI-Pipelines im Team oder mit Kunden zu teilen, ohne dass diese jemals verstehen müssen, wie ComfyUI unter der Haube funktioniert.
Gemini Embedding 2: Die multimodale Zukunft des Maschinenverständnisses
Wenn wir über große Sprachmodelle (LLMs) sprechen, vergessen wir oft die unsichtbare Brücke, die unsere menschlichen Eingaben mit dem maschinellen Verständnis verbindet: Embeddings. Ein KI-Modell versteht keine Wörter, Bilder oder Töne an sich. Alles muss in hochdimensionale Vektoren (Zahlenreihen) übersetzt werden. Bisher war diese Übersetzung strikt getrennt: Ein Text-Embedding-Modell kümmerte sich um Wörter, ein Bild-Modell um Fotos und so weiter.
Mit Gemini Embedding 2 stellt Google nun sein erstes nativ multimodales Embedding-Modell vor, und die Implikationen sind gewaltig.

Ein gemeinsamer Raum für alle Daten
Gemini Embedding 2 zwingt alle Datenformate – sei es ein Text, ein Bild, eine Audiodatei, ein Video oder ein PDF-Dokument – in denselben mathematischen Vektorraum. Das bedeutet, die semantische Bedeutung eines bellenden Hundes ist im Vektorraum identisch, egal ob es sich um den geschriebenen Text "ein Hund bellt", ein Foto eines Hundes, eine Audioaufnahme von Bellen oder ein Video davon handelt.
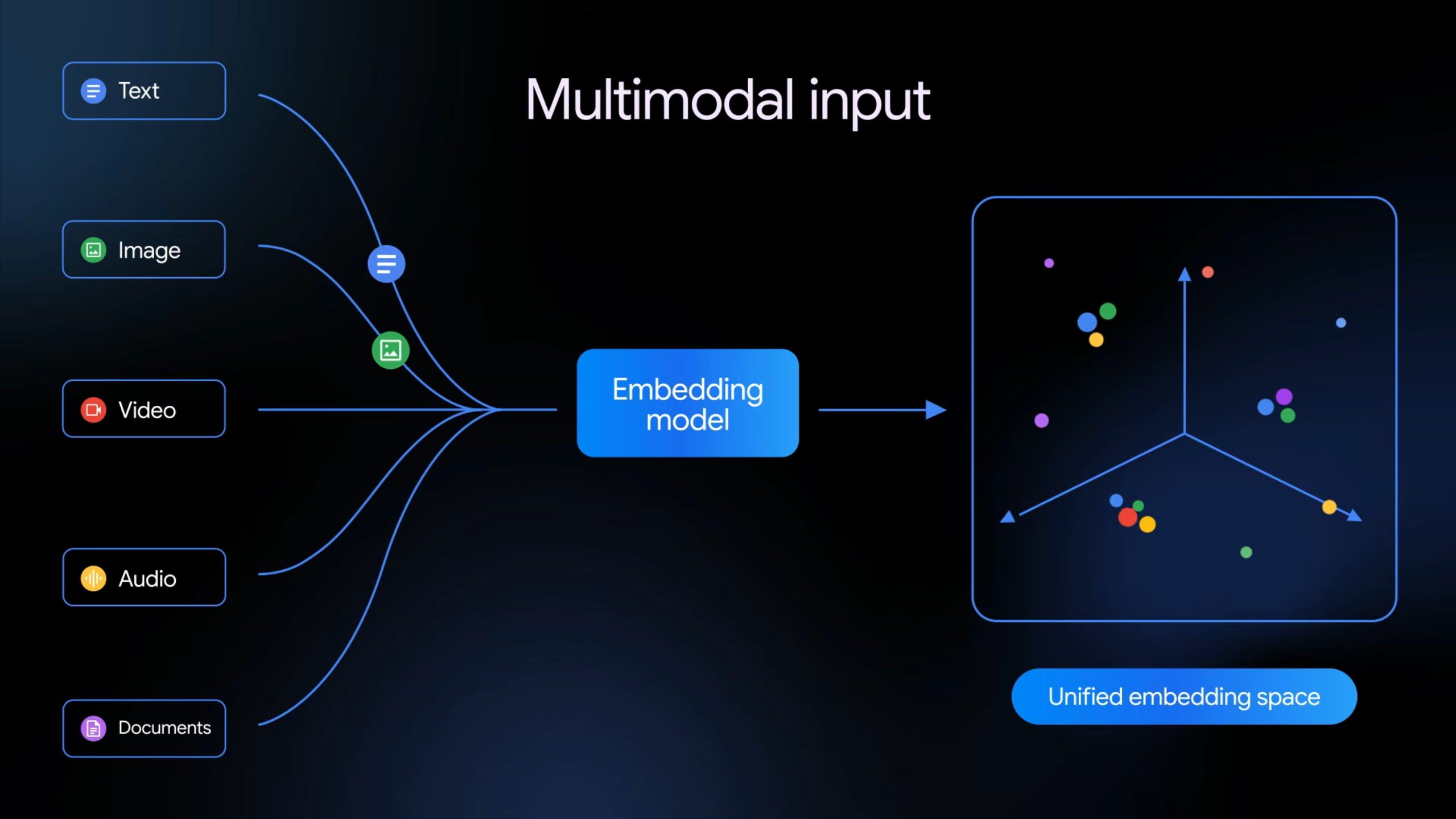
Die Leistungsdaten sind beeindruckend:
- Text: Unterstützt einen Kontext von über 8.000 Token.
- Multimedial: Kann pro Anfrage bis zu sechs Bilder, 120 Sekunden Video oder Audio verarbeiten.
- Dokumente: Liest PDFs mit bis zu sechs Seiten am Stück ein.
- Sprachen: Unterstützt über 100 Sprachen nativ.
Die Zukunft von RAG (Retrieval-Augmented Generation)
Diese Technologie revolutioniert, wie wir Daten suchen und verknüpfen. Bisherige Suchsysteme suchten Text in Text. Mit einem multimodalen Vektorraum können Sie nun eine Suchanfrage stellen wie: "Finde den Moment in diesem dreistündigen Video-Meeting, in dem der Umsatzgraph für das 3. Quartal gezeigt wurde." Das System versteht Ihre Textanfrage und findet den semantisch passenden Bild-Vektor im Video. Dies wird RAG-Systeme in Unternehmen auf ein völlig neues Level heben, da Informationssilos zwischen Text-, Audio- und Videodatenstrukturen endgültig aufgelöst werden.
BrandFusion: Die neue Ära des automatisierten Product Placements
Während sich generative Videomodelle rasant weiterentwickeln, tut sich die Werbeindustrie oft noch schwer, Marken konsistent und organisch in diese synthetischen Inhalte zu integrieren. Genau hier setzt BrandFusion an, ein revolutionäres Framework zur nahtlosen Integration von Marken und Produkten in KI-generierte Videos.
Wie BrandFusion funktioniert
BrandFusion agiert als intelligenter Mittelsmann zwischen dem Nutzer (oder der Marketingagentur) und dem eigentlichen Video-Generierungs-Modell (wie Sora, Kling, Veo oder CogVideo). Das System basiert auf einer Multi-Agenten-Architektur:
- Brand Knowledge Base: Das System verfügt über eine umfangreiche Offline-Datenbank, in der Markenprofile, Logos, Produktkategorien und Referenzbilder gespeichert sind. Auch neue Marken (Novel Brands) können mittels Fine-Tuning hinzugefügt werden.
- Brand Selection Agent: Ausgehend von einem generischen Nutzer-Prompt (z. B. "Eine Frau geht an einem sonnigen Nachmittag mit ihrem Hund im Stadtpark spazieren") wählt dieser Agent eine kontextuell passende Marke aus der Datenbank aus, etwa eine Automarke.
- Strategy Generation Agent & Prompt Rewriting Agent: Diese Agenten arbeiten zusammen, um die gewählte Marke organisch in die Szene einzubauen. Der ursprüngliche Prompt wird so umgeschrieben, dass die Marke natürlich wirkt, z. B. "Eine Frau parkt ihren BMW am Straßenrand, bevor sie mit ihrem Hund in den Park geht."
- Critic Agent: Ein Bewertungs-Agent überprüft den modifizierten Prompt daraufhin, ob die ursprüngliche Semantik erhalten blieb und ob das Product Placement natürlich wirkt. Er gibt Feedback, was zu weiteren Iterationen führt.
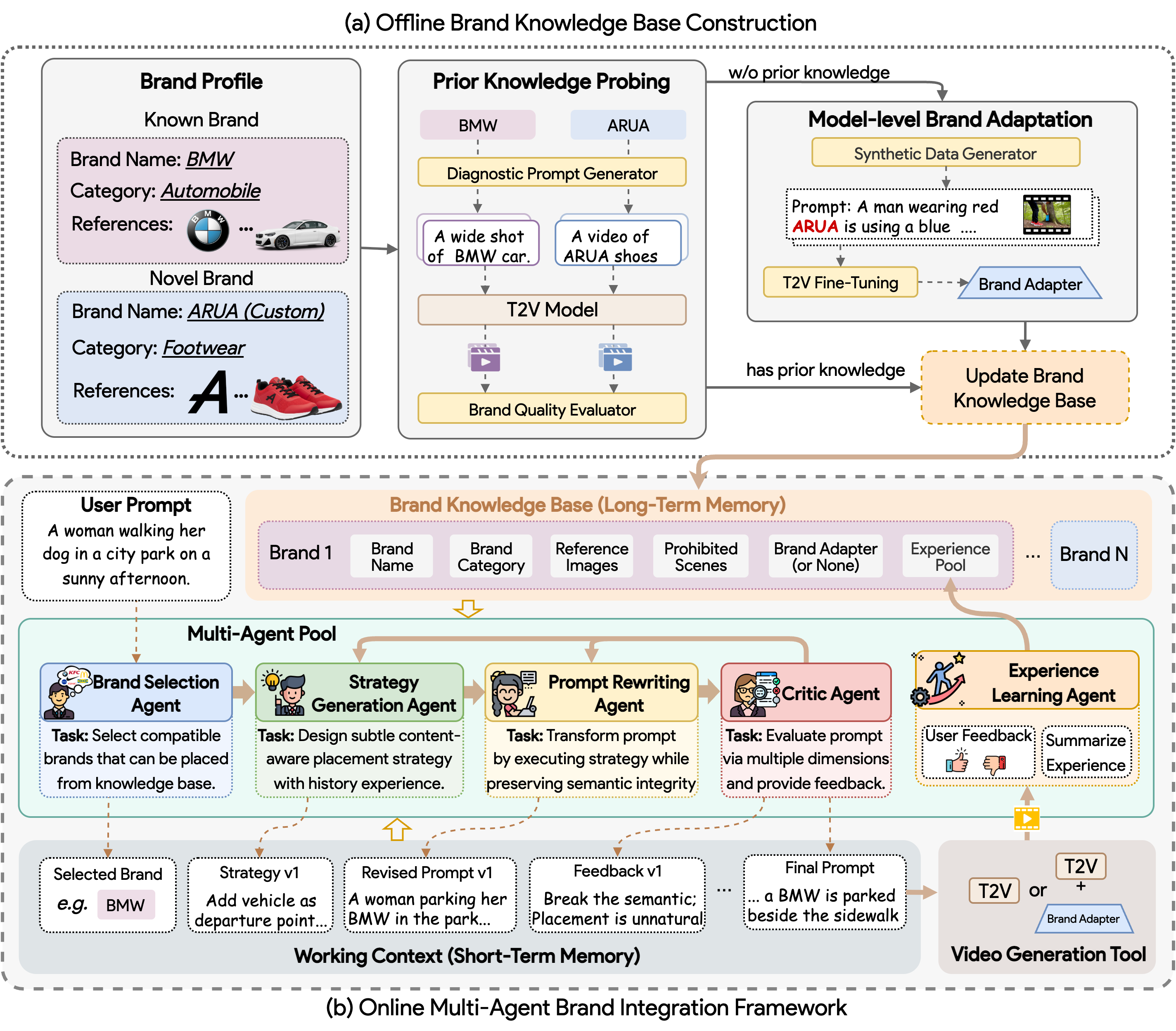
Nahtlose Integration in der Praxis
Die Ergebnisse sind verblüffend. Aus einem einfachen Prompt über ein Basketballspiel generiert BrandFusion ein Video, in dem subtil, aber klar erkennbar Nike-Logos auf den Trikots und Banden prangen. Aus einer generischen Cyberpunk-Straße wird eine Szene mit leuchtenden Coca-Cola-Neonreklamen, die sich perfekt in die nassen, reflektierenden Straßen einfügen. Selbst Möbel von IKEA oder Kaffeebecher von Starbucks werden physikalisch korrekt und in der passenden Beleuchtung gerendert.

Dieses Framework könnte die Art und Weise, wie Video-Werbung produziert wird, grundlegend verändern. Anstatt teure Shootings zu organisieren, können maßgeschneiderte Werbeclips für spezifische Zielgruppen dynamisch generiert werden, wobei die Markenidentität streng gewahrt bleibt.
Weitere bemerkenswerte Durchbrüche der Woche
Die Innovationsgeschwindigkeit ist so hoch, dass selbst die obigen Highlights nur die Spitze des Eisbergs darstellen. Hier sind weitere signifikante Entwicklungen, die unsere Aufmerksamkeit verdienen:
Nvidias Neotron 3 Super: Das neue Open-Source-Schwergewicht
Nvidia hat mit Neotron 3 Super sein bisher stärkstes "agentisches" Sprachmodell veröffentlicht. Es handelt sich um ein Mixture-of-Experts (MoE) Modell. Obwohl es massive 120 Milliarden Parameter umfasst, sind bei jeder Anfrage nur 12 Milliarden aktiv, was die Inferenz enorm effizient macht. Der eigentliche Clou ist jedoch das Kontextfenster von 1 Million Token. Dies erlaubt es, dem Modell gigantische Datenmengen (etwa 700.000 Wörter, ganze Code-Basen oder tausende Seiten Handbücher) in einem einzigen Prompt zu übergeben. Das Modell schlägt in internen Benchmarks Konkurrenten wie Qwen 3.5 und besticht durch vollkommen offene Gewichte und offengelegte Trainingsdaten.
Shotverse: Kinoreife Multi-Shot-Videos
Bisherige KI-Videogeneratoren kämpfen oft mit der Konsistenz, wenn sich die Kameraperspektive ändert. Shotverse adressiert dieses Problem, indem es Multi-Shot-Videos mit flüssigen, professionell wirkenden Kamerabewegungen aus einem Guss generiert. Anstatt unzusammenhängende Clips aneinanderzureihen, bleiben Charaktere und Umgebung über verschiedene Kameraeinstellungen hinweg perfekt konsistent. Das Geheimnis? Das Modell wurde ausschließlich auf echten cineastischen Daten trainiert und verschmäht synthetische (KI-generierte) Trainingsdaten, was die Qualität drastisch erhöht.
Robotik: Von rollenden Butler-Bots bis zu mechanischen Pferden
Die physische KI macht ebenfalls riesige Sprünge:
- Reflex Robotics: Ein aufstrebendes Startup aus New York präsentierte einen humanoiden Roboter, der zwar auf Rollen statt auf Beinen unterwegs ist, dafür aber unglaubliche feinmotorische Fähigkeiten besitzt. Demos zeigen den Roboter dabei, wie er selbstständig Frühstück zubereitet, Obst schneidet, einen Mixer bedient, die Spülmaschine ausräumt und sogar ein Steak brät.
- Deep Robotics: Ein chinesisches Unternehmen sorgte für Aufsehen mit einem vierbeinigen Roboter im Design eines Pferdes, auf dem erwachsene Menschen reiten können. Auch wenn dies teilweise als Marketing-Gag im "Jahr des Pferdes" gesehen werden kann, zeigt es die beeindruckende Tragkraft und Balance-Algorithmen moderner Quadruped-Roboter.
Realtime 3D & Audio-Evolution
Im Bereich der 3D-Generierung zeigte World FM, wie man aus einem einfachen Bildansatz in Echtzeit navigierbare 3D-Welten generieren kann, die sogar auf Consumer-Hardware (wie einer RTX 4090) flüssig laufen. Gleichzeitig ermöglicht das neue Projekt Mobile GS (Gaussian Splatting), hochdetaillierte 3D-Szenen auf handelsüblichen Smartphones mit über 120 Frames pro Sekunde zu rendern – bei einer Modellgröße von unter 5 Megabyte.
Auch die Audio-Synthese stagniert nicht: Open-Source-Modelle wie Tada und Fish Audio S2 demonstrieren Voice-Cloning auf einem Niveau, das von menschlichen Sprechern kaum noch zu unterscheiden ist. Null Halluzinationen, perfekte Betonungen und die Möglichkeit, Regieanweisungen wie [Einatmen], [Lachen] oder [Flüstern] direkt in den Text zu codieren, geben Creatorn nie dagewesene Werkzeuge an die Hand.
Fazit: Die Konvergenz der Modalitäten
Wenn wir die Nachrichten dieser Woche zusammenfassen, zeichnet sich ein deutlicher Trend ab: Wir verlassen die Ära isolierter KI-Tools und betreten das Zeitalter der Konvergenz und Integration. Werkzeuge wie Gemini Embedding 2 zeigen, dass die Grenzen zwischen Text, Bild und Video in der maschinellen Wahrnehmung verschwinden. Systeme wie BrandFusion und der App Mode in ComfyUI beweisen, dass der Fokus nun stark auf der Nutzbarkeit, Prozessintegration und wirtschaftlichen Verwertbarkeit liegt. Und die Fortschritte in der Robotik und räumlichen Navigation (Google Maps) holen die KI endgültig aus den Serverräumen hinein in unsere physische Realität.
Es bleibt spannend, und als Entwickler, Marketer oder Technik-Enthusiast war es noch nie so wichtig – und so faszinierend – am Ball zu bleiben.
Wir stehen erst am Anfang einer Revolution, in der KI nicht nur unsere digitalen, sondern auch unsere physischen Welten kartografiert, versteht und neu erschafft.
Die Informationen und Inspirationen für diesen Artikel basieren in großen Teilen auf der herausragenden wöchentlichen Kuration des YouTube-Kanals "AI Search".