
Die künstliche Intelligenz schläft nie, und die vergangenen Tage haben uns eine technologische Flutwelle beschert, die selbst erfahrene Branchenexperten staunend zurücklässt. Von Open-Source-Videogeneratoren, die native Audiospuren in Echtzeit synthetisieren, über revolutionäre Bildeditoren, die das räumliche Verständnis von Modellen neu definieren, bis hin zu KI-Agenten, die hochkomplexen GPU-Code selbstständig schreiben und optimieren – wir erleben gerade einen beispiellosen Paradigmenwechsel. Willkommen zur neuesten Ausgabe unserer Deep-Dive-Analyse der bahnbrechendsten KI-Entwicklungen.
Die Geschwindigkeit, mit der sich Foundation-Modelle, Architekturen für maschinelles Lernen und angewandte KI-Werkzeuge weiterentwickeln, hat einen Punkt erreicht, an dem traditionelle Entwicklungszyklen obsolet erscheinen. Was vor einem Jahr noch als akademisches Whitepaper galt, ist heute ein Open-Source-Tool, das auf einem handelsüblichen Rechner ausgeführt werden kann. In dieser umfassenden Analyse dekonstruieren wir die wichtigsten Durchbrüche dieser Woche. Wir betrachten nicht nur die beeindruckenden Ergebnisse, sondern tauchen tief in die zugrunde liegenden Mechanismen, Architekturen und die weitreichenden Implikationen für Entwickler, Kreative und die Industrie ein.
1. Die Revolution der KI-Videogenerierung: Von Echtzeit-Inferenz bis zu nativer Multimodalität
Die Generierung von Videos galt lange Zeit als der "Heilige Gral" der generativen KI. Die zeitliche Konsistenz über hunderte von Frames hinweg aufrechtzuerhalten, erfordert enorme Rechenleistung und ausgeklügelte Architekturen. Doch die aktuellen Durchbrüche zeigen, dass wir die Phase der experimentellen, flackernden Clips hinter uns lassen.
Kiwi-Edit: Der neue Goldstandard für quelloffene Videobearbeitung
Stellen Sie sich vor, Sie könnten ein bestehendes Video nehmen und seinen gesamten visuellen Stil mit einem einfachen Textbefehl oder einem Referenzbild transformieren, ohne dass die Bewegungen der Akteure ihre natürliche Dynamik verlieren. Genau das ermöglicht Kiwi-Edit, ein neues Open-Source-Videobearbeitungswerkzeug, das die Messlatte für Konkurrenten drastisch höher legt.

Die Architektur von Kiwi-Edit ist ein Meisterstück der modernen KI-Integration. Es kombiniert ein multimodales Large Language Model (LLM), das komplexe Benutzeranweisungen semantisch versteht, mit einem leistungsstarken Video Diffusion Transformer. Diese Kombination ermöglicht es nicht nur, globale Stile (wie "Skizze", "Aquarell" oder "Cartoon") anzuwenden, sondern auch präzise, objektbasierte Bearbeitungen vorzunehmen. So kann das System auf Anweisung bestimmte Personen oder Objekte aus dem Video entfernen oder neue, konsistente Elemente (wie eine Sonnenbrille oder einen Hut) hinzufügen. Im direkten Vergleich mit bisherigen Open-Source-Lösungen wie Vase oder Lucydit zeigt Kiwi-Edit eine signifikant höhere Stabilität. Zwar bleibt das proprietäre Cling01 noch ungeschlagen, doch Kiwi-Edit schließt die Lücke rasant. Mit einer Modellgröße von etwa 20 Gigabyte erfordert es zwar eine High-End-Consumer-GPU, bietet dafür aber volle lokale Kontrolle.
LTX 2.3: Native Audio-Video-Synthese in einem Modell
Während die meisten Videogeneratoren stumme Bilderfolgen produzieren, die nachträglich in externen Programmen vertont werden müssen, geht LTX 2.3 einen revolutionären Weg. Dieses neue Open-Source-Modell integriert die Audio-Generierung nativ in den Diffusionsprozess.
Das Resultat ist eine verblüffende Synchronisation zwischen dem visuellen Geschehen und dem generierten Ton. Wenn eine Person im Video spricht, passen die Lippenbewegungen zur Kadenz der generierten Stimme. Wenn ein Objekt fällt, ertönt das Geräusch exakt beim Aufprall. Diese multimodale Kohärenz wird erreicht, indem Audio- und Video-Token im selben latenten Raum verarbeitet werden. LTX 2.3 unterstützt Videos von bis zu 20 Sekunden Länge in 4K-Auflösung und hat nun – ein massives Upgrade für Social-Media-Creator – die native Unterstützung für vertikale Videoformate eingeführt. Die Schärfe der Details und die Fähigkeit, das Prompt strikt zu befolgen, machen es zu einem der mächtigsten Werkzeuge im Arsenal moderner Kreativer.
Helios: Echtzeit-Generierung auf dem Weg zum Holodeck
Der Begriff "Echtzeit" wird in der KI-Welt oft inflationär gebraucht, doch das Helios-Modell wird diesem Anspruch gerecht. Es generiert qualitativ hochwertige, bis zu einer Minute lange Videos mit erstaunlichen 19,5 Frames pro Sekunde auf einer einzelnen H100-GPU.
Warum ist das so wichtig? Bisherige Ansätze zur Echtzeit-Videogenerierung litten unter extremem Detailverlust, Rauschen und mangelnder zeitlicher Kohärenz. Helios nutzt hochoptimierte Inferenz-Pipelines und fortgeschrittene "Reward Forcing"-Techniken, um den Kompromiss zwischen Geschwindigkeit und Qualität drastisch zu verbessern. Zwar ist die H100-GPU kein Gerät für den Heimgebrauch, doch Helios liefert den ultimativen "Proof of Concept". Wenn man sich die historische Entwicklung der Hardware-Beschleunigung ansieht, ist es nur eine Frage von Monaten, bis ähnliche Architekturen durch Quantisierung und Destillation auf Consumer-Hardware laufen. Die Implikationen für interaktive Medien, Videospiele, bei denen Zwischensequenzen live generiert werden, und dynamische Benutzeroberflächen sind gigantisch.
FreeEdit und Real Wonder: Interaktive Physik und Frame-Propagierung
Neben der reinen Generierung verändern Werkzeuge wie FreeEdit und Real Wonder die Art und Weise, wie wir mit Videodaten interagieren.
- FreeEdit verfolgt einen bestechend logischen Ansatz für die Videobearbeitung: Der Nutzer bearbeitet lediglich das allererste Frame eines Videos (z.B. indem er einen roten Sportwagen in einen blauen verwandelt). Das System nutzt dann eine Technik namens "Editing-Aware Re-Injection". Durch den Einsatz von optischem Fluss (Optical Flow) innerhalb der Diffusionsblöcke wird diese Änderung konsistent über alle nachfolgenden Frames propagiert. Im Gegensatz zu älteren Methoden führt dies nicht zu Flackern oder unerwünschten Artefakten im Hintergrund.
- Real Wonder bringt physikalische Interaktion in generierte Videos. Nutzer können Echtzeit-Kräfte – repräsentiert durch direktionale Vektoren – auf Objekte im Video anwenden. Ein Pfeil auf eine Wasseroberfläche generiert realistische Wellen in die gewählte Richtung. Ein Vektor auf ein Kleidungsstück simuliert Windeinwirkung. Bei 13 FPS auf einer H200-GPU deutet dieses System an, wie die Zukunft von Physik-Engines aussehen könnte: Nicht durch hart codierte physikalische Formeln berechnet, sondern durch neuronale Netze visuell approximiert.
2. Bildbearbeitung der nächsten Generation: Der Siegeszug der Open-Source-Modelle
Lange Zeit dominierten proprietäre Systeme wie Midjourney oder DALL-E 3 die Szene. Doch die aktuelle Generation von Open-Source-Bildeditoren zeigt, dass die Community nicht nur aufgeholt, sondern in spezifischen Anwendungsfällen die Führung übernommen hat.
Fire Red Image Edit 1.1: Semantische Präzision in Perfektion
Die Veröffentlichung von Fire Red Image Edit 1.1 markiert einen neuen Höhepunkt in der semantischen Bildmanipulation. Im Kern geht es hierbei um die Fähigkeit der KI, die Identität und die essenziellen Merkmale eines Subjekts beizubehalten, während der restliche Kontext radikal verändert wird.
Wenn Sie das Foto einer Person einspeisen, kann Fire Red 1.1 den Hintergrund, die Kleidung und sogar die Pose komplett neu berechnen, ohne dass das Gesicht seine unverwechselbaren Züge verliert. Die Konsistenz, mit der das Modell komplexe Texturen – etwa feine Spitzenmuster an Kleidern oder spezifische Lichtreflexe – rekonstruiert, ist atemberaubend.

Darüber hinaus beherrscht das Modell hochpräzises "Typography-Transfer". Wenn Sie ein Referenzbild eines Posters mit einer spezifischen Schriftart hochladen, kann Fire Red diese exakte Typografie extrahieren und nahtlos in ein neues Bild integrieren, inklusive korrekter Perspektive und Beleuchtung. Die Benchmark-Tests sprechen eine klare Sprache: In vielen Kategorien schlägt Fire Red 1.1 etablierte Modelle wie Qwen ImageEdit, LongCat und sogar einige proprietäre Systeme. Der einzige Wermutstropfen ist aktuell die schiere Größe des Modells von fast 60 Gigabyte, die jedoch in naher Zukunft durch GGUF-Quantisierung für normale Grafikkarten zugänglich gemacht werden dürfte.
HY-WU von Tencent: Meisterklasse im Outfit-Transfer
Für die Modeindustrie, den E-Commerce und Cosplayer bringt der Tech-Gigant Tencent mit HY-WU ein Werkzeug heraus, das bisherige Grenzen sprengt.

Der Transfer von Kleidung in der KI-Bildgenerierung ist notorisch schwierig. Faltenwurf, Körperform, Lichtverhältnisse und komplexe Muster führen oft zu unnatürlichen Verschmelzungen. HY-WU löst dieses Problem durch einen genialen technischen Kniff: Es analysiert das hochgeladene Kleidungsstück und den Text-Prompt und generiert daraus in Sekundenbruchteilen ein winziges, temporäres LoRA (Low-Rank Adaptation) Modell. Dieses feingetunte Mikro-Modell wird dann "on the fly" in den eigentlichen Bildgenerator injiziert. Das Ergebnis ist eine phänomenale Genauigkeit bei der Übertragung von Texturen und Schnitten.

Die Leistungsfähigkeit von HY-WU zeigt sich besonders beim "Cross-Domain"-Transfer. Wie das Beispiel zeigt, kann das Modell problemlos ein Kostüm, das von einer Plüschfigur getragen wird, realitätsgetreu auf einen menschlichen Körper mappen, inklusive logischer Anpassungen der Proportionen. Dies revolutioniert die Produktfotografie, da Model-Shootings für neue Kollektionen nun vollständig virtuell und mit beliebigen Referenzbildern durchgeführt werden können.
Hi-Fi inPaint: Die Lösung für Produktplatzierungen
Eng verwandt mit der Mode-Generierung ist die kommerzielle Produktfotografie. Hi-Fi Paint adressiert das spezifische Problem, ein Produkt nachträglich in die Hand einer Person auf einem Foto zu integrieren. Während herkömmliche Inpainting-Modelle oft die Geometrie des Produkts verzerren oder falsche Schatten werfen, nutzt Hi-Fi Paint eine spezialisierte "Shared Enhancement Attention"-Methode. Diese verfeinert die Produktdetails mittels Hochfrequenz-Karten (High-Frequency Maps) auf mikroskopischer Ebene. Das Produkt wirkt dadurch nicht wie nachträglich eingefügt, sondern interagiert korrekt mit der Beleuchtung und der Anatomie der haltenden Hand.
3. Räumliches Verständnis und Inferenz-Beschleunigung: Das Fundament wird gestärkt
Trotz all der beeindruckenden visuellen Ergebnisse leiden fast alle Diffusionsmodelle unter einem fundamentalen Problem: Sie haben massive Schwierigkeiten mit räumlicher Logik (Spatial Reasoning). Wenn Sie ein Modell anweisen, "einen Apfel links von einer Tasse und ein Buch hinter der Tasse" zu generieren, versagt das System in den meisten Fällen. Die KI versteht zwar die Konzepte "Apfel", "Tasse" und "Buch", würfelt deren Positionierung aber oft beliebig durcheinander.
SpatialReward: Ein Durchbruch im Spatial Reasoning
Hier setzt das neue Framework SpatialReward an. Die Forscher erkannten, dass das Problem in der Natur der Text-Encoder (wie CLIP) liegt, die Sprache eher wie einen "Sack voller Wörter" behandeln und syntaktische Relationen vernachlässigen.
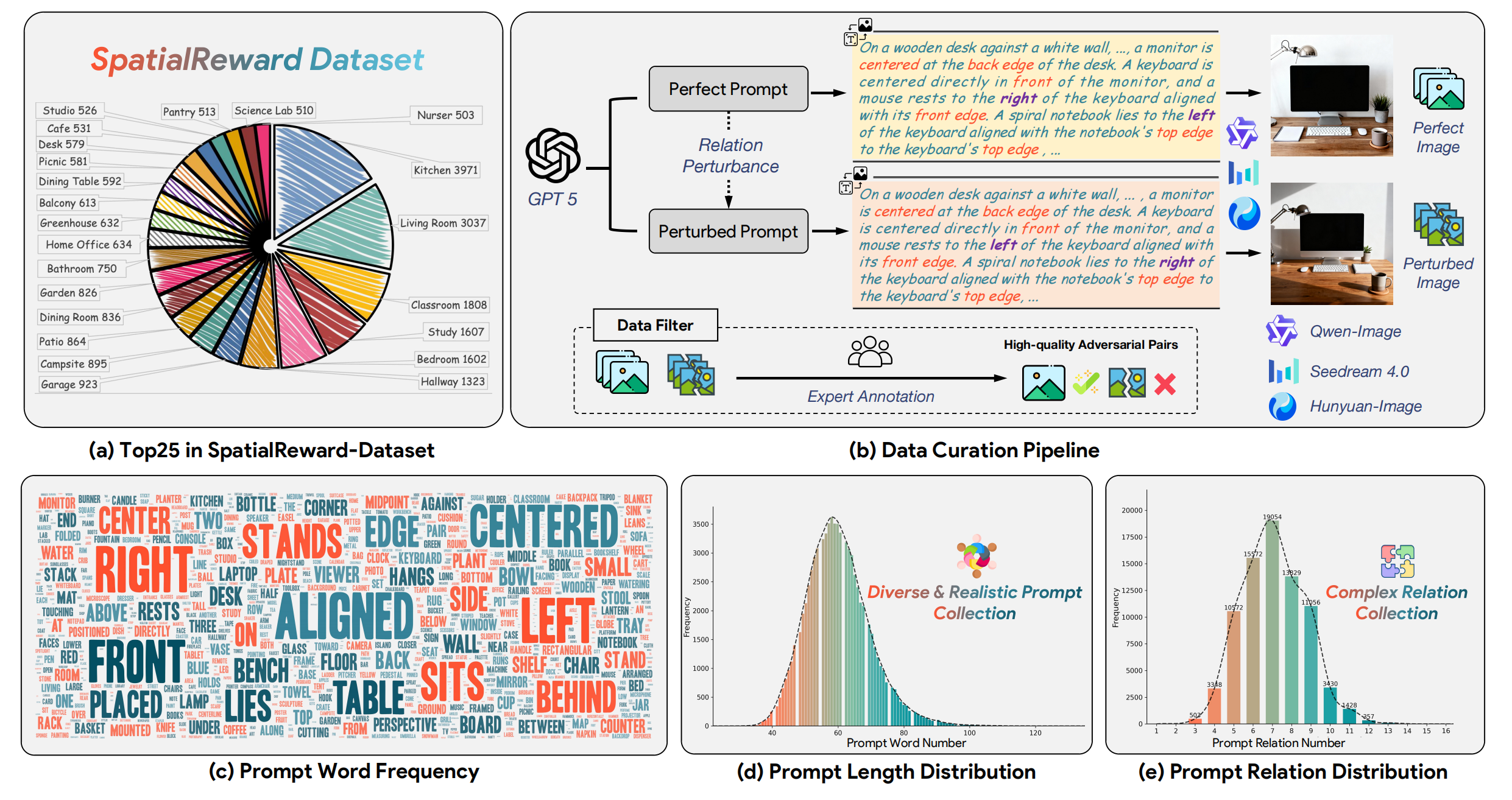
Die Lösung? Reward Modeling, eine Technik, die auch beim Training von LLMs (RLHF) extrem erfolgreich ist. Die Entwickler schufen einen gigantischen Datensatz mit über 80.000 Bild-Text-Paaren. Der Clou: Neben dem korrekten Bild wurde gezielt ein inkorrektes Bild generiert, bei dem die räumlichen Relationen (z.B. Objekt A vor Objekt B) absichtlich manipuliert wurden. Ein spezielles Reward-Modell wurde darauf trainiert, genau diese Unterschiede zu erkennen und zu bestrafen.

Wenn dieses SpatialReward-Modell nun auf Basis-Modelle wie Flux angewendet wird, verhalten sich diese plötzlich absolut logisch. Kerzen stehen in einer präzisen Linie sortiert nach Größe, Teetassen befinden sich exakt auf der angegebenen Seite des Tisches, und Wandbilder hängen zentriert über spezifischen Objekten. Für Architekten, Designer und alle, die auf präzise Kompositionen angewiesen sind, ist dies ein existenzielles Upgrade, das den Frust beim "Prompt-Engineering" massiv reduziert.
Spectrum von ByteDance: Mathematik auf Steroiden
ByteDance (der Mutterkonzern von TikTok) liefert mit Spectrum einen algorithmischen Durchbruch, der die Rechenzeit für Bild- und Videogenerierung drastisch verkürzt, ohne neue Hardware zu benötigen. Spectrum ist kein eigenes Diffusionsmodell, sondern ein Modul, das auf Modelle wie Flux oder Hunyuan Video aufgesetzt werden kann.
Der Prozess der Diffusionsgenerierung ist traditionell iterativ und langsam: Das Modell entfernt in Dutzenden von Schritten schrittweise Rauschen aus einem Bild. Spectrum nutzt eine mathematische Technik basierend auf Tschebyscheff-Polynomen, um die Veränderung von Features über die Zeit hochpräzise zu modellieren. Anstatt jeden Schritt mühsam durchzurechnen, kann Spectrum zukünftige Diffusionsschritte akkurat vorhersagen. Das Ergebnis? Eine Beschleunigung der Generierung um das 3,5- bis 4,7-fache bei quasi unsichtbarem Qualitätsverlust. Während andere Beschleuniger (wie Taylor-basierte Methoden) oft verfälschte Farben oder Artefakte erzeugen, bleiben die Ergebnisse mit Spectrum gestochen scharf und farbtreu.
4. KI an der Edge und die Automatisierung der Hardware: Ein Paradigmenwechsel
Der Trend ging lange Zeit nur in eine Richtung: Größere Modelle, mehr Parameter, gigantische Rechenzentren. Doch diese Woche zeigt eindrucksvoll, dass Effizienz das neue Wachstum ist.
Qwen 3.5: Die Rückkehr der kleinen Riesen
Alibaba beweist mit der Veröffentlichung der Qwen 3.5 Familie, dass weniger oft mehr ist. Nachdem sie erst kürzlich potente "Medium"-Modelle veröffentlicht hatten, stürmen nun radikal verkleinerte Versionen den Markt: Modelle mit 9 Milliarden, 4 Milliarden, 2 Milliarden und sogar winzigen 0,8 Milliarden Parametern.
Das 0.8B-Modell ist komprimiert nur rund 2 Gigabyte groß. Das bedeutet, es passt mühelos in den Arbeitsspeicher fast jedes modernen Smartphones oder Raspberry Pi. Und das Beste daran: Die Benchmarks dieser Winzlinge sind surreal. Die 9B- und 4B-Varianten können in Disziplinen wie komplexer Mathematik (Harvard-Niveau), multikulturellem Wissen und Instruction-Following mühelos mit weitaus größeren Open-Source-Modellen und sogar geschlossenen Architekturen wie Gemini 2.5 Flash mithalten. Dieser Durchbruch in der Modelldestillation (Knowledge Distillation) bedeutet, dass leistungsstarke, unzensierte und private KI-Assistenten bald nativ und offline auf jedem Endgerät laufen werden – ohne Latenz und ohne Datenabfluss in die Cloud.
GPT 5.4: Der Proprietäre Titan
Auch wenn Open-Source triumphiert, darf man den neuesten Wurf von OpenAI nicht ignorieren: GPT 5.4. Es wird als das bisher fähigste Frontier-Modell beschrieben, mit einem enormen Fokus auf logisches Schließen (Reasoning) und agentische Workflows. Es glänzt besonders darin, selbstständig komplette Office-Aufgaben zu übernehmen, Tabellenkalkulationen auszuführen, komplexe Dokumentationen zu erstellen und Physik- sowie Mathematikprobleme auf Expertenniveau zu lösen. Es setzt die Benchmark für das, was an der absoluten Spitze des technisch Machbaren im Cloud-Sektor möglich ist.
CUDA Agent: KI, die sich selbst optimiert
Der vielleicht weitreichendste Durchbruch dieser Woche kommt ebenfalls von ByteDance und trägt den Namen CUDA Agent. Um die Bedeutung dieses Systems zu verstehen, muss man kurz ausholen:
KI-Modelle laufen auf GPUs. Damit GPUs diese unvorstellbaren Datenmengen parallel verarbeiten können, benötigen sie speziellen Code, sogenannte "Kernel", die in der Sprache CUDA (von Nvidia) geschrieben werden. Das Schreiben und Optimieren von CUDA-Kerneln ist eine der schwierigsten Disziplinen der Informatik. Es erfordert tiefstes Verständnis von Hardware-Architektur, Speicherhierarchien und Thread-Synchronisation. Selbst brillante Programmierer brauchen oft Wochen, um einen Kernel um wenige Prozentpunkte schneller zu machen.
Der CUDA Agent ist ein KI-System, das exakt dafür trainiert wurde. Er analysiert den Bedarf, schreibt den GPU-Code, kompiliert ihn, testet die Geschwindigkeit, identifiziert Flaschenhälse und schreibt den Code um – in einer kontinuierlichen Schleife, bis die absolute Maximalleistung der Hardware erreicht ist. In Vergleichen deklassierte der CUDA Agent selbst Top-Modelle wie Claude Opus 4.5 oder Gemini 3 Pro bei der Erstellung von fehlerfreiem, hochoptimiertem Hardware-Code. Wir betreten hier die Ära der rekursiven Selbstverbesserung: KI-Systeme optimieren die exakte Softwareebene, auf der sie selbst laufen, was zu exponentiellen Geschwindigkeitszuwächsen in der künftigen KI-Forschung führen wird.
5. 3D-Welten, Robotik und die Simulation der Realität
Die letzte große Grenze der KI ist der Sprung aus dem zweidimensionalen Bildschirm in die physische (und simulierte dreidimensionale) Welt. Die Werkzeuge, die dafür gerade entwickelt werden, lesen sich wie Science-Fiction.
Die Entschlüsselung der 3. Dimension
- Cube Composer: Stellen Sie sich vor, Sie filmen mit Ihrem Smartphone ein einfaches Video eines verschneiten Feldes. Cube Composer nimmt dieses singuläre, flache Video und extrapoliert daraus ein vollständiges, in 4K hochgerechnetes 360-Grad-Video, in dem Sie sich per Virtual Reality umsehen können. Es zerlegt das Video virtuell in eine Sphäre, generiert Seite für Seite des 3D-Raums und nutzt "Sparse Attention" aus einem Kontext-Pool, um sicherzustellen, dass die generierten Rückseiten der Szene logisch zum gefilmten Vorne passen. Im Vergleich zu älteren Tools wie Argus oder Viewpoint ist die Qualität ein Quantensprung.
- Track for World: Dieses Modell analysiert ein Standardvideo und berechnet für absolut jeden Pixel im Bild dessen Bewegung im dreidimensionalen Raum über die Zeit. Ob Parkour-Läufer oder Skifahrer – die KI erstellt präzise 3D-Trajektorien aus einer 2D-Aufnahme. Dies ermöglicht perfekte Motion-Capture-Daten ohne teure Anzüge oder Tracking-Punkte und bildet die Grundlage für hochakkurate 3D-Rekonstruktionen.
- UniA (Unified AI für Point Clouds): Normalerweise benötigt man völlig unterschiedliche KI-Modelle, um die Radar-Scans (LiDAR) eines selbstfahrenden Autos, die Innenraum-Scans eines Robotersackmachers oder die Satellitendaten der Erde zu verstehen. UniA vereint all dies. Es ist ein einzelner, nur rund 550 Megabyte großer Encoder, der jede Art von 3D-Punktwolke versteht und semantisch einordnen kann. Ein Durchbruch für die Robotik und autonome Navigation.
- Artifixer 3D & Nvidia Diffusion Harmonizer: Die Generierung von 3D-Szenen aus wenigen Fotos (Sparse Reconstruction) führt oft zu Artefakten, Löchern und matschigen Texturen. Artifixer agiert hier als "Heiler", der diese fehlerhaften 3D-Szenen durch Diffusionsmodelle glättet, Details hinzufügt und chaotische Hintergründe logisch auffüllt. Nvidias Diffusion Harmonizer geht noch einen Schritt weiter und löst das "Sim-to-Real"-Problem. Wenn in einer Echtzeitsimulation digitale Objekte (wie Autos) künstlich oder deplatziert wirken, berechnet der Harmonizer in Echtzeit realistische Schatten, passt den Weißabgleich an und lässt die gerenderten Objekte nahtlos und fotorealistisch in die simulierte Welt verschmelzen.
Omni Xtreme: Robotik jenseits der menschlichen Physis
Die vielleicht spektakulärste visuelle Demo dieser Woche betrifft die Robotik. Omni Xtreme ist ein Framework zur Steuerung von humanoiden Robotern, das uns eindrucksvoll vor Augen führt, dass die motorischen Fähigkeiten von Maschinen bald unsere eigenen übertreffen könnten.
Das Video zeigt einen humanoiden Roboter, der nicht nur geht oder Kisten hebt, sondern Breakdance tanzt, aufeinanderfolgende Rückwärtssaltos schlägt, sich auf einer Hand balanciert und Martial-Arts-Kicks in der Luft ausführt. Die Fluidität und Geschwindigkeit dieser Bewegungen sind beispiellos. Aber wie funktioniert das?
Das Geheimnis liegt im zweistufigen Training. In einer rein digitalen Simulation lernt das System zunächst von sogenannten "Motion Tracking Experts" – isolierten Algorithmen, die nur eine einzige extreme Bewegung (z.B. einen Salto) perfekt beherrschen. Diese vielen Einzel-Experten werden dann durch eine fortschrittliche Technik namens "Flow Matching" zu einer massiven, universellen Basis-Policy (einem übergeordneten "Gehirn") zusammengefasst. Der Roboter "weiß" nun theoretisch, wie all diese Bewegungen ablaufen.
Das Problem: Die physikalische Welt ist unberechenbar, und Motoren können durchrutschen oder überhitzen. Daher wird beim Einsatz im echten Roboter eine leichte "Residual Policy" (eine Art Sicherheitsinstanz) über die Basis-Policy gelegt. Diese kontrolliert in Millisekundenbruchteilen die Echtzeit-Sensordaten und passt die Bewegungen minimal an, um sicherzustellen, dass die physikalischen Grenzen der Hardware nicht überschritten werden und der Roboter das Gleichgewicht behält. Das Ergebnis ist eine Symbiose aus digital erlernter Akrobatik und physischer Echtzeit-Reaktivität, die die Tür zu einer völlig neuen Generation von Robotern aufstößt.
Fazit: Die Singularität der Werkzeuge
Wenn wir die Entwicklungen dieser Woche Revue passieren lassen, zeichnet sich ein klares Bild ab: Die Fragmentierung der KI schwindet. Werkzeuge werden multimodaler, räumlich bewusster und greifen tief in die Optimierung ihrer eigenen physikalischen Hardware (wie beim CUDA Agent) ein. Gleichzeitig demokratisiert die Open-Source-Community Spitzenleistung in einem Tempo, das selbst für Großkonzerne beängstigend sein muss. Ein Modell, das auf Ihrem Smartphone läuft und mit Universitätsabsolventen mithalten kann, oder ein quelloffener Videoeditor, der hollywoodreife Effekte erzielt, sind keine Zukunftsmusik mehr – sie sind hier, mit frei verfügbarem Quellcode.
Für Kreative, Entwickler und Unternehmer bedeutet dies: Die Barrieren für hochkomplexe Produktionen und Anwendungen sinken gegen Null. Die einzige verbleibende Grenze ist die eigene Vorstellungskraft und die Bereitschaft, sich auf diese rasant lernenden Werkzeuge einzulassen.
Innovation in der KI vollzieht sich nicht mehr linear, sondern exponentiell. Jedes gelöste Problem ist der Schlüssel zu zehn neuen, bisher undenkbaren Möglichkeiten.
Inspirationsquelle: KI-Entwicklungs-Trends, reflektiert durch den YouTube-Kanal "AI Search"