
Während sich die Welt in die Weihnachtsferien verabschiedet hat, liefen die GPUs in den Forschungslaboren heiß. Die letzte Woche des Jahres 2025 markiert einen Wendepunkt in der Open-Source-KI: Wir sehen Modelle, die nicht nur mit proprietären Giganten wie Gemini 3 und GPT-5.2 konkurrieren, sondern diese in spezifischen Nischen sogar übertreffen. Von autonomen Gaming-Agenten über revolutionäre Coding-Modelle bis hin zu physikalisch korrekter 3D-Rekonstruktion – dies ist der umfassende technische Deep-Dive in die wichtigsten AI-News zum Jahreswechsel.
NVIDIA NitroGen: Der Durchbruch für autonome Gaming-Agenten
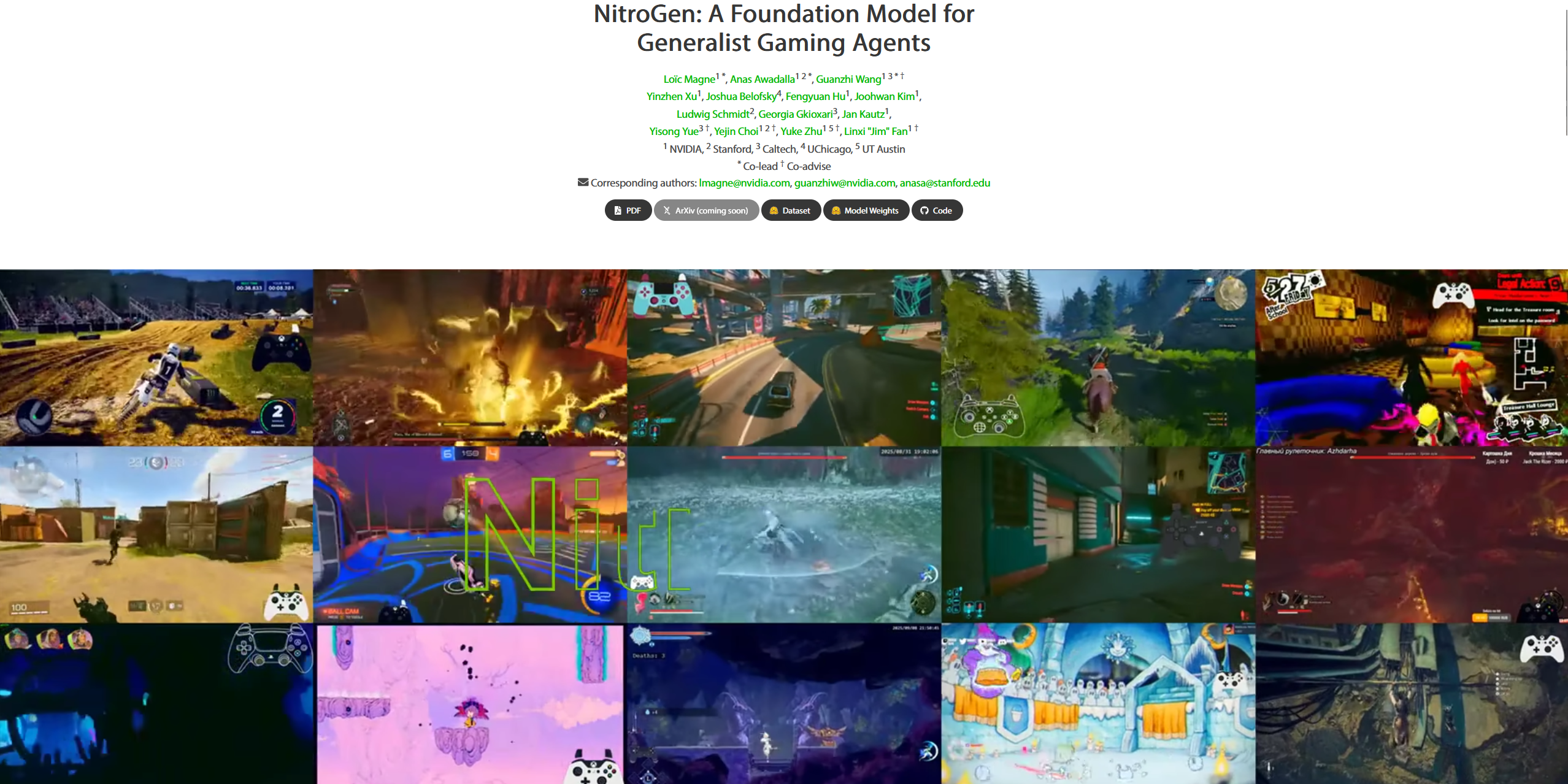
Das vielleicht faszinierendste Paper dieser Woche stammt von NVIDIA und trägt den Titel NitroGen. Es handelt sich hierbei um ein sogenanntes Vision-Action Foundation Model, das entwickelt wurde, um Videospiele auf einem Niveau zu spielen, das menschlichen Fähigkeiten entspricht – und das rein visuell, ohne Zugriff auf den internen Game-Code.
Architektur und Training
NitroGen unterscheidet sich fundamental von bisherigen Reinforcement-Learning-Ansätzen. Anstatt für jedes Spiel einzeln trainiert zu werden, wurde das Modell auf einem massiven Datensatz von 40.000 Stunden Gameplay aus über 1.000 verschiedenen Spielen trainiert. Diese Daten wurden "Internet-scale" aus öffentlich verfügbaren Videos extrahiert.
Technisch setzt NitroGen auf eine duale Struktur:
- Vision-Komponente: Ein SigLIP-2 Vision Transformer verarbeitet die Rohdaten des Bildschirms (256x256 Frames).
- Action-Komponente: Ein Diffusion-Transformer prognostiziert die notwendigen Controller-Eingaben.
Das Modell nutzt Flow Matching, um Sequenzen zukünftiger Aktionen (Chunks) basierend auf einem einzigen Frame vorherzusagen. Es "sieht" also das Spielgeschehen und "drückt" virtuelle Tasten auf einem Controller, inklusive analoger Stick-Bewegungen.
Warum das wichtig ist
Die Fähigkeit von NitroGen, Zero-Shot auf Spiele zu generalisieren, die es nie zuvor gesehen hat, ist bemerkenswert. In Tests zeigte sich, dass das Modell komplexe Logik anwenden kann – etwa das Verständnis, wie man ein Auto in einem Rennspiel wieder aufrichtet oder Boss-Mechaniken in einem Action-RPG durchschaut. Für die Spieleindustrie bedeutet dies eine Revolution im Bereich QA (Quality Assurance), da KI-Agenten nun Spiele unermüdlich auf Bugs testen können, genau wie menschliche Tester es tun würden.
3D-RE-GEN: Vom flachen Bild zur editierbaren 3D-Szene
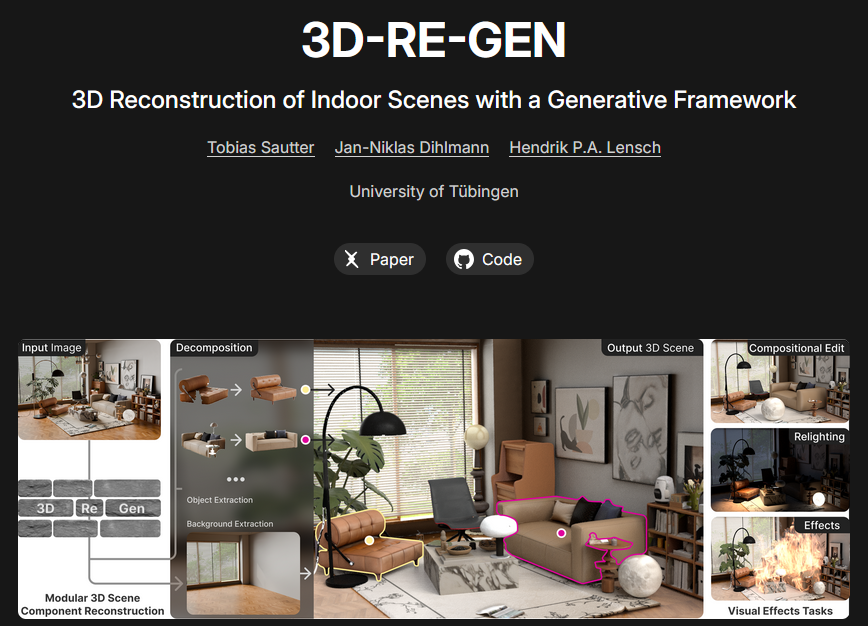
Ein weiteres Highlight aus der akademischen Welt kommt von der Universität Tübingen. Mit 3D-RE-GEN wird ein langjähriges Problem der Computer Vision adressiert: Die Umwandlung eines einzelnen 2D-Fotos in eine voll nutzbare, räumliche 3D-Szene, in der Objekte einzeln manipuliert werden können.
Modulare Rekonstruktion
Im Gegensatz zu bisherigen Methoden, die oft nur eine "Backbox"-Szene als Mesh ausgeben, arbeitet 3D-RE-GEN modular. Das System identifiziert Objekte im Bild (z.B. Sofa, Lampe, Tisch), separiert diese vom Hintergrund und rekonstruiert sie als eigenständige 3D-Assets. Der Hintergrund wird dabei intelligent "inpainted", um die verdeckten Bereiche hinter den Objekten aufzufüllen.
Die Forscher nutzen eine 4-DoF-Optimierung (Degrees of Freedom), um sicherzustellen, dass alle Objekte korrekt auf der Grundebene (Ground Plane) stehen und physikalisch plausibel im Raum platziert sind. In Nutzerstudien wurde die Qualität der Layout-Komposition mit 81% Präferenz bewertet – ein enormer Sprung gegenüber existierenden SOTA-Modellen.
MiniMax M2.1: Der neue König des Open-Source-Codings?
Die vielleicht größte Überraschung der Woche liefert MiniMax mit ihrem neuen Modell M2.1. Während die Welt auf GPT-5 wartet, zeigt MiniMax, dass effiziente, spezialisierte Modelle oft nützlicher sind als gigantische Generalisten.

Benchmarks und Leistung
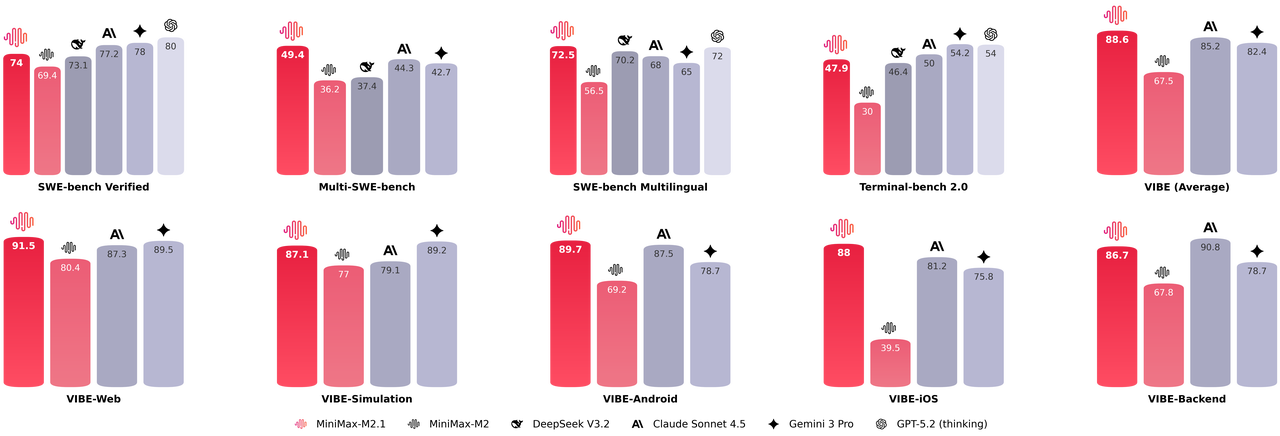
Die Zahlen sprechen eine deutliche Sprache. MiniMax M2.1 erreicht auf dem SWE-bench Verified und der multilingualen Variante Scores, die etablierte Größen wie Claude 3.5 Sonnet und Gemini 3 Pro hinter sich lassen. Besonders beeindruckend ist die Effizienz: Das Modell nutzt eine Mixture-of-Experts (MoE) Architektur mit etwa 10 Milliarden aktiven Parametern (bei einer größeren Gesamtanzahl), was die Inferenzkosten drastisch senkt (ca. $0.30 pro Million Token).
"Vibe Coding" und Real-World-Anwendungen
Was bedeutet das in der Praxis? Das Modell brilliert beim sogenannten "Vibe Coding" – dem Erstellen kompletter Applikationen oder Spiele mit einem einzigen Prompt. Tests zeigten, dass M2.1 in der Lage ist, komplexe 3D-Rennspiele mit Physik-Engine oder detaillierte Bienenschwarm-Simulationen in HTML/JS zu schreiben, ohne dass der Nutzer Code korrigieren muss.
Ein weiteres Feature ist das "Interleaved Thinking". Das Modell trennt internen Denkprozess und finale Ausgabe strikt, was es erlaubt, komplexe logische Ketten zu bilden, bevor eine Zeile Code geschrieben wird. Dies ist essenziell für Agenten-Workflows, bei denen das Modell autonom Fehler suchen und beheben muss.
Generative Refocusing: Rettung für unscharfe Fotos
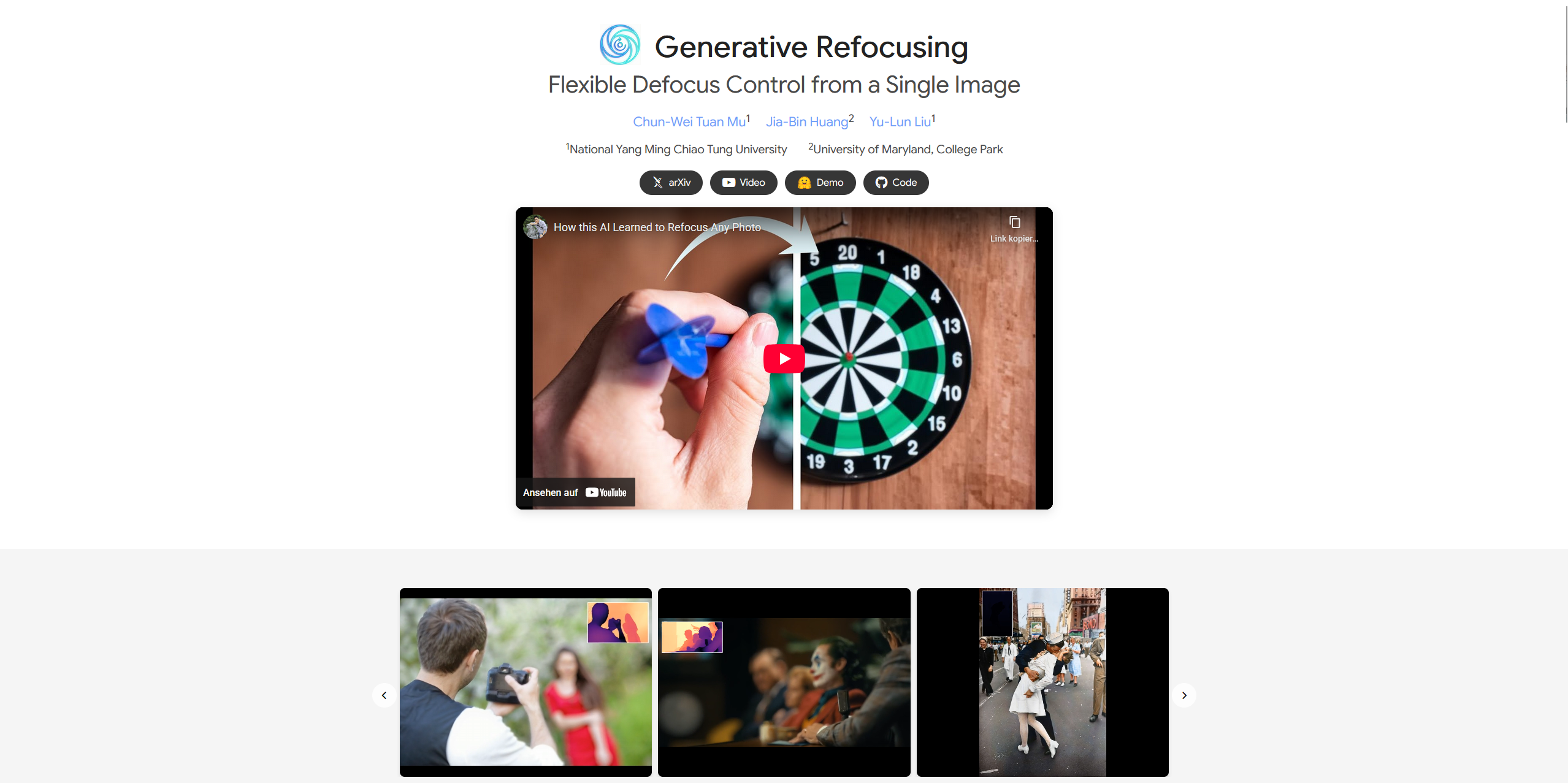
Jeder Fotograf kennt den Schmerz: Der perfekte Moment ist eingefangen, aber der Fokus saß falsch. Ein neues Paper namens Generative Refocusing verspricht hier Abhilfe auf einem neuen Level.
Zwei-Stufen-System
Das System arbeitet in zwei Schritten:
- DeblurNet: Zuerst wird das Bild komplett scharf gerechnet ("All-in-Focus"). Hierbei werden Unschärfen entfernt, die durch falsche Fokussierung oder Bewegung entstanden sind.
- BokehNet: Anschließend wendet das Modell eine künstliche Tiefenunschärfe an, die physikalisch akkurate Linseneffekte simuliert.
Der Clou ist das semi-supervisierte Training. Die Forscher nutzten EXIF-Metadaten von echten Fotos, um dem Modell beizubringen, wie echte Objektive Licht brechen (Bokeh). Das Ergebnis ist nicht nur ein "Weichzeichner", sondern eine realistische Simulation optischer Tiefe, die nachträglich angepasst werden kann.
Qwen-Image-Edit 2511: Der Photoshop-Killer?
Alibaba Cloud drückt weiter aufs Gaspedal. Mit Qwen-Image-Edit 2511 (eigentlich für November geplant, jetzt im Dezember erschienen) stellen sie den wohl aktuell besten Open-Source Image Editor vor.

Integrierte LoRAs und Konsistenz
Das größte Problem bei KI-Bildbearbeitung war bisher die Konsistenz: Verändert man die Kleidung einer Person, veränderte sich oft auch das Gesicht. Version 2511 löst dies durch eine verbesserte Architektur, die Identitäten extrem stabil hält.
Besonders spannend für Power-User: Beliebte Community-Techniken (LoRAs) wurden direkt in das Basismodell integriert:
- Relighting: Die Beleuchtung einer Szene kann per Textprompt komplett geändert werden.
- Novel View Synthesis: Das Modell kann Objekte drehen oder die Kameraperspektive ändern ("Zoom in", "Front View"), ohne die Geometrie zu zerstören.
Das Modell basiert auf einer MMDiT-Architektur (Multimodal Diffusion Transformer) und ist auch in einer quantisierten Version verfügbar, die auf Consumer-Grafikkarten mit 8GB VRAM läuft.
Weitere Entwicklungen im Schnelldurchlauf
Die Fülle an Veröffentlichungen diese Woche ist so groß, dass wir einige weitere Highlights nur kurz anreißen können, die aber nicht weniger revolutionär sind:
FlashPortrait
Ebenfalls von Alibaba kommt FlashPortrait. Dieses Tool generiert "Infinite Length" Portrait-Videos. Während Konkurrenten wie Live Portrait oft nur wenige Sekunden schaffen, bevor das Gesicht verzerrt, hält FlashPortrait die Konsistenz über Minuten hinweg stabil. Es ist zudem 6-mal schneller als bisherige Methoden.
RICO (Region Constraint in Context)
RICO wird als "Nano Banana für Video" beschrieben. Es erlaubt das punktgenaue Editieren von Videoinhalten. Sie können in einem bestehenden Video einen Mann durch einen Pinguin ersetzen oder einem Objekt eine Mütze aufsetzen. Das Besondere: Das Tracking ist extrem robust, selbst bei bewegten Kameras.
Carry 4D & AnyX
NVIDIA zeigt mit Carry 4D, wie man aus Videos von Menschen, die Objekte benutzen, 3D-Daten extrahiert, um Roboter zu trainieren. Passend dazu erlaubt AnyX, beliebige 3D-Charaktere in 3D-Welten zu platzieren und per Text zu animieren ("Jensen Huang spielt Harfe").
Fazit
Das Jahr 2025 endet mit einem Feuerwerk an Innovationen. Besonders der Trend zu spezialisierten, hoch-effizienten Modellen (wie MiniMax M2.1) und die Verschmelzung von Vision und Action (NitroGen) zeigen, wohin die Reise 2026 geht: Weg von reinen Chatbots, hin zu echten Agenten, die in virtuellen und echten Welten handeln können.
"Even though it's Christmas holiday, AI never sleeps."
AI Search - YouTube