
Willkommen zu einer der ereignisreichsten Wochen in der Geschichte der Künstlichen Intelligenz. Während das Jahr 2026 unaufhaltsam voranschreitet, erleben wir derzeit eine beispiellose Beschleunigung in der Entwicklung von KI-Modellen. Was einst als unmöglich galt – komplexe multimodale Modelle, die lokal auf Smartphones laufen, fotorealistische 3D-Rekonstruktionen in Echtzeit und offengelegte Agenten-Frameworks der Branchenriesen –, ist heute Realität. Dieser Artikel taucht tief in die neuesten technologischen Durchbrüche ein und analysiert, wie diese Innovationen unsere Arbeitswelt, die Softwareentwicklung und die kreativen Industrien für immer verändern werden.
Google Gemma 4: Ein Quantensprung für Open-Source und Edge-Computing
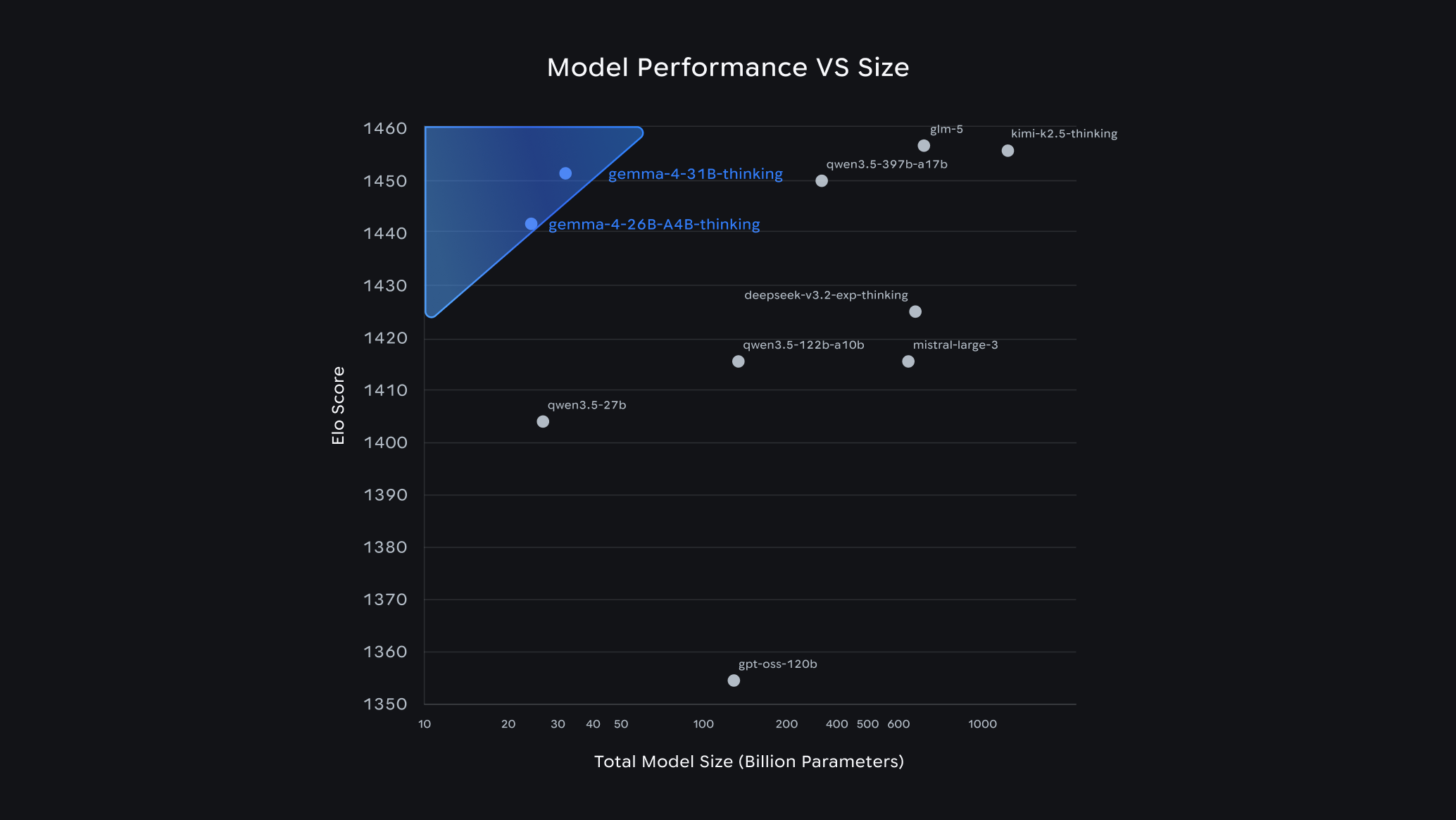
Google hat mit der Veröffentlichung der Gemma 4-Familie ein unmissverständliches Signal an die Open-Source-Community gesendet. Basierend auf der gleichen zukunftsweisenden Forschung, die auch dem kommerziellen Flaggschiff Gemini 3 zugrunde liegt, bringt Gemma 4 eine nie dagewesene Leistungsdichte auf lokale Endgeräte. Das Modell ist unter der äußerst permissiven Apache 2.0-Lizenz verfügbar, was Entwicklern, Forschern und Unternehmen maximale Freiheit bei der Integration und kommerziellen Nutzung einräumt.
Architektur und Skalierung: Von Edge bis Enterprise
Die Gemma 4-Familie ist strategisch in vier verschiedene Architekturen und Größen unterteilt, um ein extrem breites Spektrum an Anwendungsfällen nahtlos abzudecken:
- E2B und E4B (2 bzw. 4 Milliarden Parameter): Diese hochgradig optimierten, kompakten Modelle sind speziell für den Einsatz auf sogenannten Edge-Geräten konzipiert. Egal ob auf dem neuesten Smartphone, Drohnen-Controllern oder ressourcenschonenden Einplatinencomputern – sie laufen lokal und autark. Trotz ihrer geringen Größe bieten sie ein massives Kontextfenster von 128.000 Token, was etwa 100.000 Wörtern oder einer Stunde Audiomaterial entspricht.
- 26B (Mixture of Experts): Dieses Modell nutzt eine hochmoderne MoE-Architektur (Mixture of Experts). Obwohl es insgesamt über 26 Milliarden Parameter besitzt, sind bei jeder logischen Anfrage (Inference) nur etwa 3,8 Milliarden Parameter aktiv. Ein intelligenter Router-Mechanismus leitet den Input nur an die "Experten"-Subnetze weiter, die für das spezifische Thema relevant sind. Dies drückt den VRAM-Bedarf und die Latenz dramatisch nach unten, während das Modell gleichzeitig die Breite eines massiven Netzwerks beibehält.
- 31B (Dense Model): Das Flaggschiff der Reihe verzichtet auf die MoE-Struktur zugunsten eines dichten neuronalen Netzes. Es maximiert die reine Ausgabequalität, das logische Denken (Reasoning) und die Faktenpräzision und zielt auf High-End-Workstations und Server ab. Die Kontextgröße verdoppelt sich hier auf immense 256.000 Token.
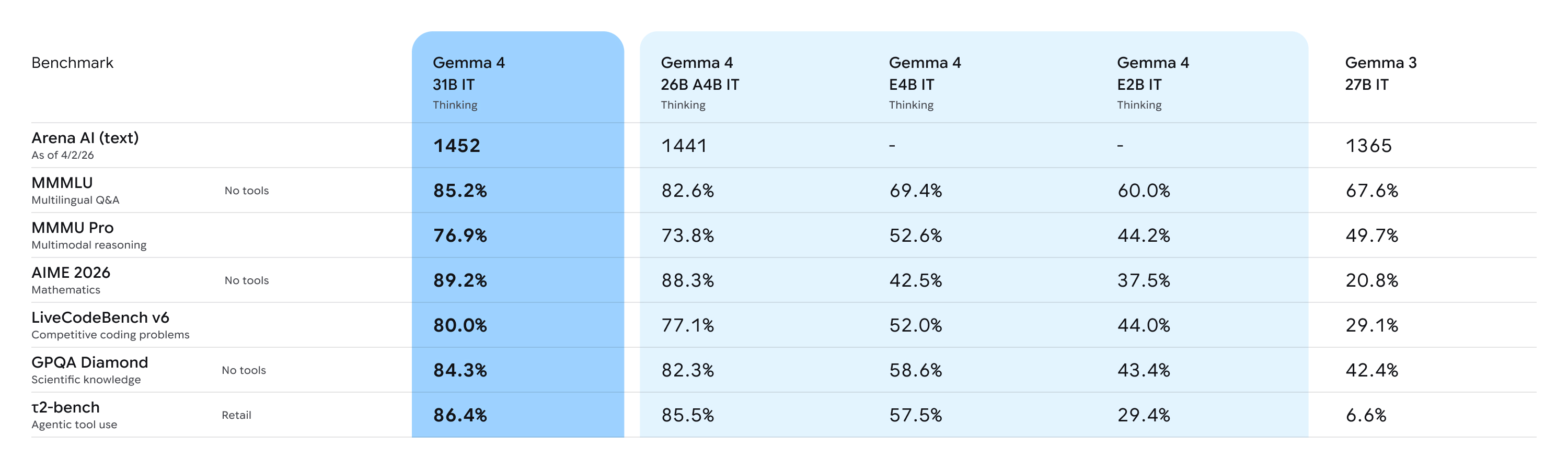
Was Gemma 4 jedoch wirklich revolutionär macht, ist seine native Multimodalität out-of-the-box. Das Modell verarbeitet Text, Bilder und Audio in einem einzigen neuronalen Netz, ohne auf separate, fehleranfällige Module für die Sprach-zu-Text-Transkription (ASR) oder Bilderkennung angewiesen zu sein. Für mobile Anwender bedeutet dies, dass Sprachassistenten nun mit nahezu null Latenz in Echtzeit reagieren können, da sie den rohen Audio-Stream direkt semantisch erfassen. Gepaart mit der nativen Unterstützung für über 140 Sprachen wird Gemma 4 zu einem universellen, verzögerungsfreien Übersetzungswerkzeug und persönlichen Begleiter.
Generative World Renderer: Die Neuerfindung der AAA-Spieleentwicklung
Die Art und Weise, wie Videospiele entwickelt, modifiziert und gerendert werden, steht vor einem massiven Paradigmenwechsel. Der neu vorgestellte Generative World Renderer demonstriert eindrucksvoll, wie Künstliche Intelligenz genutzt werden kann, um Echtzeit-Grafiken in AAA-Spielen durch reine Texteingaben stilistisch komplett zu transformieren, ohne die eigentliche Spiel-Logik oder Physik zu beeinträchtigen.
Der technologische Clou hinter dieser Innovation liegt im intelligenten Zugriff auf sogenannte GBuffers (Geometry Buffers). Moderne Rendering-Engines (wie beispielsweise die Unreal Engine 5) berechnen ein fertiges Bild nicht einfach als flaches Pixelraster. Stattdessen generieren sie während des Rendering-Prozesses verschiedene physikalische Datenkanäle für jeden Frame:
- Depth (Tiefe): Präzise räumliche Informationen darüber, wie weit ein virtuelles Objekt von der Kamera entfernt ist.
- Normal (Normalen-Vektor): Die exakte Ausrichtung der Oberfläche jedes Polygons im 3D-Raum. Dies ist absolut entscheidend für die physikalisch korrekte Licht- und Schattenberechnung.
- Albedo: Die reine, flache Grundfarbe eines Objekts ohne jegliche Schatten oder Lichteinflüsse.
- Metallic & Roughness: Materialeigenschaften, die der Engine mitteilen, wie stark, spiegelnd oder diffus eine Oberfläche das Licht reflektiert (z.B. der Unterschied zwischen rauem Asphalt und nassem Autolack).

Indem das KI-Modell diese komplexen GBuffer-Daten als fundamentalen Input nutzt, besitzt es ein perfektes, dreidimensionales physikalisches Verständnis der Szene. Ein Spieler kann beispielsweise das Action-Rollenspiel Black Myth: Wukong spielen und das System anweisen: "Verwandle die Umgebung in eine neonbeleuchtete Cyberpunk-Stadt im strömenden Regen". Das Modell legt nicht einfach nur einen billigen Filter über den Bildschirm. Es berechnet korrekte Reflexionen in Pfützen, generiert volumetrischen Nebel und platziert neonfarbene Lichtquellen, die organisch mit der existierenden Level-Geometrie interagieren. Für Modding-Communities und Indie-Entwickler eröffnet dies völlig neue Horizonte, da hochkomplexe Environments in Zukunft adaptiv generiert werden können, ohne wochenlange manuelle 3D-Modellierung.
Gen Searcher: Grounded Generation für absolute Fakten-Treue
Bildgeneratoren wie Midjourney oder DALL-E produzieren zweifelsohne atemberaubende digitale Kunst, scheitern jedoch im professionellen Einsatz oft kläglich an der Faktentreue. Wenn ein Modell in seinen Trainingsdaten nie spezifisch auf ein obskures Gebäude, ein detailliertes wissenschaftliches Diagramm oder einen sehr spezifischen Popkultur-Charakter trainiert wurde, neigt es unweigerlich zum "Halluzinieren" – es erfindet Details, die visuell ansprechend wirken mögen, aber sachlich völlig falsch sind.
Hier greift das neue, brillante Framework Gen Searcher ein. Es kombiniert die Autonomie eines webbasierten Such-Agenten mit der generativen Kraft eines Diffusionsmodells. Bevor der eigentliche Bildgenerierungsprozess startet, analysiert der KI-Agent den Prompt des Nutzers. Verlangt der Nutzer beispielsweise das detaillierte Poster einer extrem abgelegenen Forschungsstation in Grönland mit historischen Temperaturdaten, oder einen spezifischen Charakter aus dem Spiel Wuthering Waves inklusive exakter UI-Elemente, stoppt das System zunächst. Der Gen Searcher sucht selbstständig im Internet nach offiziellen Artworks, realen Fotos, Wikipedia-Einträgen und aktuellen Fakten.

Diese gesammelten Referenzbilder und verifizierten Daten werden dann in das Diffusionsnetzwerk eingespeist. Dieser Ansatz ist vergleichbar mit der RAG-Methodik (Retrieval-Augmented Generation), die Textmodelle vor Halluzinationen bewahrt. Das Ergebnis sind Bilder, die historische Korrektheit, architektonische Präzision und typografische Exaktheit aufweisen. Da dieses Framework komplett modellagnostisch aufgebaut ist, lässt es sich prinzipiell als Plugin auf jedes bestehende Open-Source- oder Closed-Source-Bildmodell anwenden, was seine Attraktivität für den Enterprise-Sektor enorm steigert.
Der Anthropic-Vorfall: Was uns der Claude Code Leak über die Zukunft der Softwareentwicklung lehrt
Eines der brisantesten Themen dieser Woche in der Tech-Welt war zweifellos der unbeabsichtigte Leak des Quellcodes von Anthropics ambitioniertem Claude Code. Durch einen simplen, aber folgenschweren Fehler beim Erstellen und Publizieren eines NPM-Pakets (Node Package Manager) gelangte eine gewaltige Source-Map-Datei an die Öffentlichkeit. Diese Datei enthielt den gesamten proprietären TypeScript-Code – über 500.000 Zeilen verteilt auf fast 2.000 Dateien – im lesbaren Klartext.
Dieser Leak ist deshalb so faszinierend für Analysten und Entwickler, weil er nicht die mathematischen Gewichte (Weights) des eigentlichen KI-Basismodells enthüllte. Stattdessen zeigte er das hochkomplexe Agenten-Framework, das klug um das rohe Modell herum konstruiert wurde. In der heutigen KI-Landschaft wird zunehmend klar: Das Basismodell ist oft nur noch der Motor. Das wahre Betriebsgeheimnis und der Wettbewerbsvorteil liegen im Chassis – also in der Architektur, die regelt, wie große Aufgaben in Teilaufgaben zerlegt, externe Werkzeuge aufgerufen und der Langzeit-Kontext verwaltet wird. Der Code-Leak offenbarte faszinierende, bisher geheime interne Features:
- Das Buddy-System (Gamification der CLI): Ein verstecktes Feature-Flag zeigte eine Art virtuelles Haustier (ähnlich einem Tamagotchi), das als ASCII- oder Pixel-Art neben der Eingabeleiste des Entwicklers im Terminal sitzt und dynamisch auf den geschriebenen Code, Fehlermeldungen oder Erfolge reagiert. Eine charmante, psychologische Methode, um die oft trockene CLI (Command Line Interface) menschlicher und einnehmender wirken zu lassen.
- Chyros (Der proaktive Background Agent Mode): Ein tiefgreifendes System, das Claude erlaubt, asynchron im Hintergrund weiterzuarbeiten, auch wenn der Entwickler nicht aktiv am Computer sitzt. Während der Entwickler schläft, kann Chyros die gesamte Codebase scannen, Refactoring-Vorschläge erarbeiten, Speichereinträge konsolidieren (ein Prozess, der frappierend an das menschliche Träumen erinnert) und sogar proaktiv auf GitHub-Issues, Pull-Requests oder Slack-Nachrichten des Teams reagieren.
- Undercover Mode: Das vielleicht spannendste und humorvollste Detail war der System-Prompt für den sogenannten "Undercover-Modus". Dieser weist die KI unmissverständlich an, sich bei Beiträgen in öffentlichen Open-Source-Repositories strikt wie ein menschlicher Entwickler zu verhalten. Die KI darf unter keinen Umständen interne Modellnamen, Anthropic-Projektcodes oder ihre maschinelle Natur verraten. Der Prompt befiehlt wörtlich: "Do not blow your cover". Ironischerweise war es vermutlich genau dieser Modus, der durch den Leak so spektakulär enttarnt wurde.
Der Vorfall gibt der weltweiten Open-Source-Community nun quasi ungewollt eine brillante Blaupause an die Hand, wie man robuste, agentische Speichersysteme und intelligente Tool-Calling-Mechanismen für eigene Projekte aufbauen kann. Es beweist, dass "Prompt Engineering" auf Systemebene weit mehr ist als nur das Schreiben netter Sätze – es ist knallharte Systemarchitektur.
PS Designer: Das Ende des flachen Pixels in der Grafikbranche
Für professionelle Grafikdesigner und Art-Direktoren war die KI-Revolution bislang ein zweischneidiges Schwert. Diffusionsmodelle liefern zwar auf Zuruf atemberaubende Rastergrafiken, doch eine flache, einlagige PNG-Datei ist im professionellen Druck- oder Web-Workflow oft weitgehend nutzlos. Warum? Weil sich Texte, Firmenlogos, störende Bildelemente oder Hintergrundfarben in einem flachen Pixelbrei nicht nachträglich verschieben oder flexibel an Kundenwünsche anpassen lassen. PS Designer löst exakt dieses gravierende Branchenproblem, indem es vollständig bearbeitbare, sauber strukturierte Photoshop-Dateien (.psd) nativ generiert.
Der komplexe Workflow von PS Designer basiert auf einem hochgradig iterativen, multi-agentischen System:
- Asset Collector Agent: Analysiert den initialen Text-Prompt präzise und sammelt oder generiert isolierte Einzelelemente (z.B. einen freigestellten Kuchen, florale Muster, spezifische Typografie und Hintergrundtexturen).
- Graphic Planner: Fungiert als virtueller Art-Direktor. Er entwirft ein logisches Layout, das den strengen visuellen Regeln von Komposition, optischer Hierarchie, Whitespace und Farbtheorie entspricht.
- Tool Executor: Übersetzt diesen Layout-Plan in echte, maschinenlesbare Photoshop-Aktionen. Er positioniert die Ebenen, wendet Ebenenstile (wie Drop Shadow, Inner Glow oder Stroke) an, setzt nicht-destruktive Masken und verarbeitet Smart Objects.

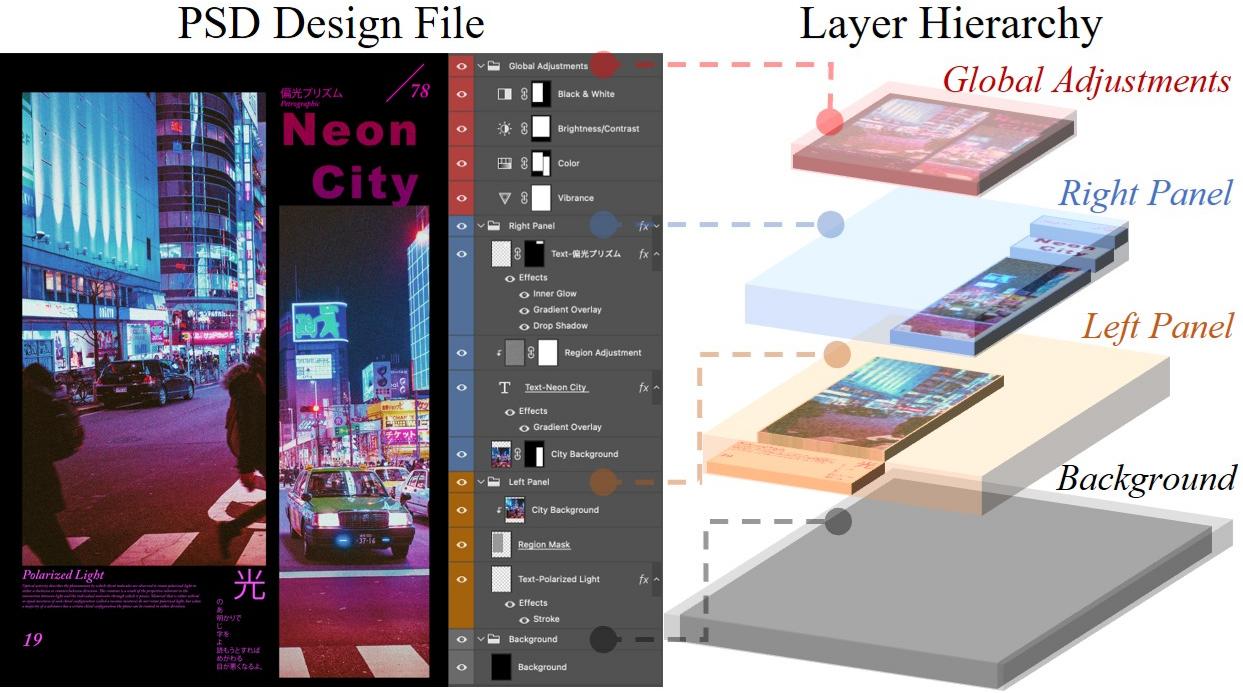
Das Resultat ist ein iterativer Feedback-Loop, bei dem sich das KI-System selbst evaluiert und korrigiert, bis das finale Layout professionellen Standards entspricht. Für Werbeagenturen, Verlage und Content-Creator bedeutet dies den lang ersehnten Durchbruch: KI liefert nicht länger ein unveränderliches Endprodukt, sondern den perfekten Ausgangspunkt und Projektentwurf, der dann in der gewohnten Software-Umgebung (Adobe Photoshop) manuell verfeinert wird.
Die Qwen-Offensive: Alibabas Frontalangriff mit 3.5 Omni und 3.6 Plus
Alibaba Cloud etabliert sich derzeit mit atemberaubender Geschwindigkeit als dominierende, treibende Kraft im globalen Open-Source-KI-Markt. Mit der simultanen und unerwarteten Veröffentlichung von Qwen 3.5 Omni und Qwen 3.6 Plus setzen sie völlig neue Maßstäbe, an denen sich selbst geschlossene Premium-Modelle wie GPT-4 von OpenAI oder Gemini 1.5 Pro von Google messen lassen müssen.
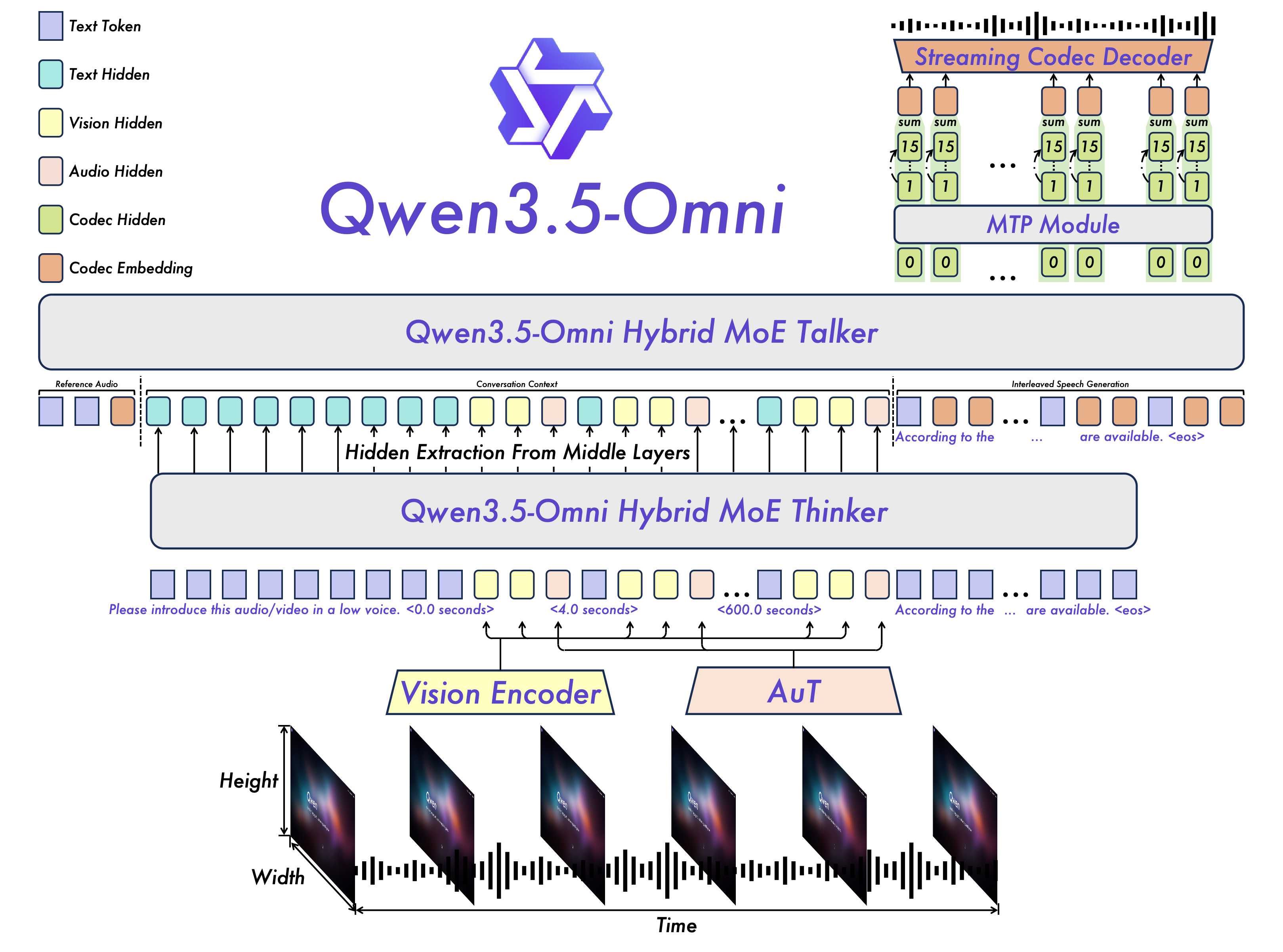
Qwen 3.5 Omni: Wahre Multimodalität ohne Umwege
Der Zusatz "Omni" (aus dem Lateinischen für "alles") wird hier nicht als bloßes Marketing-Buzzword verwendet. Das Modell verarbeitet Video, Audio, Bilder und Text synchron und nativ. Die faszinierende interne Architektur integriert einen hybriden Mixture-of-Experts (MoE) Ansatz, unterteilt in sogenannte "Talker"- und "Thinker"-Module. Das bedeutet in der Praxis: Man kann dem Modell ein verwackeltes Smartphone-Video zeigen, in dem ein rudimentäres Snake-Videospiel auf einem Bildschirm gespielt wird. Ohne jeglichen begleitenden Textprompt erkennt Qwen die grundlegende Spielmechanik, analysiert die Bewegungen der digitalen Schlange, versteht die UI-Elemente und generiert augenblicklich den korrekten HTML-, CSS- und JavaScript-Code, um das Spiel im Browser exakt nachzuprogrammieren.
Qwen 3.6 Plus: Das 1-Millionen-Token-Monster
Parallel dazu treibt Qwen 3.6 Plus die schiere Skalierbarkeit der Informationsverarbeitung auf die absolute Spitze. Mit einem gewaltigen Kontextfenster von 1 Million Token kann das Modell ganze Fachbibliotheken, gigantische Enterprise-Codebases (wie beispielsweise große Teile des Linux-Kernels) oder stundenlange, unbearbeitete Videotranskripte in einem einzigen Prompt gleichzeitig im "Kurzzeitgedächtnis" halten. Besonders im kritischen Bereich des autonomen, agentischen Programmierens zeigt dieses Modell phänomenale Ergebnisse und eignet sich perfekt als das leistungsstarke Backend für komplexe Frameworks wie das zuvor erwähnte Claude Code oder OpenDevin.

Weitere Meilensteine: See-Through, GLM-5V-Turbo und Netflix VOID
See-Through: Dekonstruktion von Anime-Kunst und 2D-Animation
Für Animatoren in der Spieleentwicklung und Schöpfer von VTuber-Avataren (Virtual YouTuber) ist das Modell See-Through ein lange ersehnter Gamechanger, der zahllose Arbeitsstunden eliminiert. Das Modell nimmt eine einzige, völlig flache Illustration (z.B. ein typisches Anime-Artwork) und zerlegt diese algorithmisch präzise in logische, hochauflösende und transparente Ebenen (wie Haare im Vordergrund, Gesichtspartien, Kleidung, Requisiten und den Hintergrund). Besonders herausragend dabei ist die Fähigkeit der KI zum intelligenten Inpainting: Bereiche des Körpers oder des Hintergrunds, die im Originalbild durch andere Objekte verdeckt waren, werden logisch und stilistisch passend aufgefüllt und generiert. Kombiniert mit der automatischen Schätzung der Raumtiefe (generierte Depth Maps) können aus statischen, leblosen Bildern binnen Sekunden voll animierbare, dreidimensionale Live2D-Modelle für Streams oder Spiele abgeleitet werden.

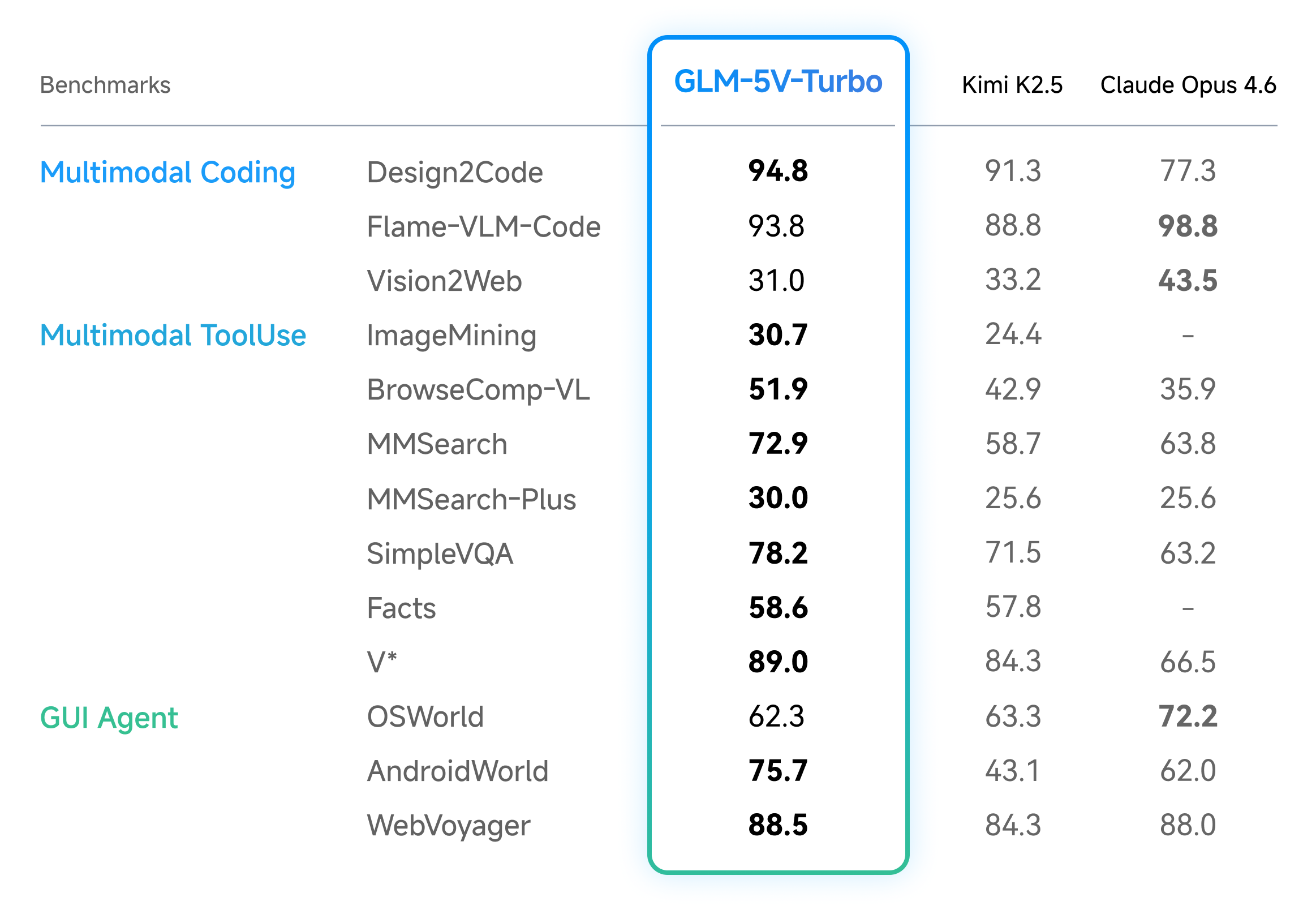
GLM-5V-Turbo: Zhipu AIs unangefochtener Vision-Coder
Aus der hochinnovativen chinesischen KI-Szene kommt mit GLM-5V-Turbo von Zhipu AI ein extrem spezialisiertes Vision-Language-Modell, das sich fast ausschließlich auf das perfekte Übersetzen von visuellen Inputs in funktionsfähigen Code fokussiert. Softwareentwickler oder Designer können hastig gezeichnete Skizzen auf Papierservietten, strukturierte Wireframes oder sogar Bildschirmaufnahmen interagierender Websites hochladen. Die KI begnügt sich nicht mit dem Erfassen des grundlegenden Layouts, sondern extrahiert präzise CSS-Animationen, komplexe Hover-Effekte, Responsive-Design-Strukturen und Farbpaletten, um in Sekundenschnelle sofort einsetzbaren, sauberen Frontend-Code zu generieren, der den Originalvorgaben bis auf den Pixel gleicht.
Netflix VOID: Physisch korrekte Video-Manipulation aus Hollywood
Dass ausgerechnet der Streaming-Gigant Netflix einen derart signifikanten Open-Source-Beitrag zur KI-Forschung leistet, überraschte selbst Branchenkenner. Ihr Modell VOID (Video Object and Interaction Deletion) ermöglicht es, Objekte, Fahrzeuge oder Personen aus komplex bewegten Videoszenen nahtlos zu entfernen. Anders als bisherige, oft fehleranfällige "Content-Aware Fill"-Werkzeuge herkömmlicher Schnittsoftware, versteht VOID die tiefgreifenden physikalischen Zusammenhänge einer Szene. Entfernt man in einem Video beispielsweise eine herabrollende Bowlingkugel, die gerade im Begriff ist, Pins abzuräumen, rekonstruiert das Modell nicht nur den verdeckten Hintergrund (die Textur der leeren Holzbahn), sondern passt die Szene kausal so an, dass die Pins stehen bleiben, da die Krafteinwirkung der Kugel fehlt. Diese kausale und strikt zeitliche Konsistenz ist absolut bahnbrechend für aufwendige Postproduktions-Workflows, VFX-Artists und die Filmindustrie im Allgemeinen.
Omni Voice & Dreamlight: KI überall und für jeden
Mit Omni Voice steht Entwicklern ab sofort eine extrem mächtige Open-Source Text-to-Speech (TTS) Engine zur Verfügung, die unfassbare 600 globale Sprachen und Dialekte beherrscht. Noch beeindruckender ist die revolutionäre Fähigkeit des sogenannten Cross-Lingual-Clonings: Die KI kann die Charakteristika einer englischen Sprecherstimme anhand weniger Sekunden Audiomaterial analysieren und diese Stimme anschließend mit exakt derselben Betonung, Stimmlage und emotionalen Nuance fehlerfreies Japanisch, Koreanisch oder Russisch sprechen lassen. Das gezielte Einfügen von emotionalen Steuerungs-Tags wie [laughter] (Lachen), [surprise] (Überraschung) oder [dissatisfaction] macht die generierten synthetischen Stimmen im Alltag kaum noch von echten, menschlichen Sprechern zu unterscheiden.
Parallel dazu zeigt der Tech-Konzern ByteDance (Mutterkonzern von TikTok) mit Dreamlight eindrucksvoll, wohin die Reise der Konsumenten-KI in den nächsten Jahren unweigerlich geht. Dieses extrem komprimierte, winzige Diffusionsmodell (mit gerade einmal 0,39 Milliarden Parametern) kann komplett offline auf modernen Smartphones (wie dem Apple iPhone 17 Pro) ausgeführt werden. Zwar kann es in puncto mikroskopischer Texturen (wie menschliche Hautporen oder feines Tierfell) nicht mit riesigen Cloud-Giganten wie Midjourney v6 mithalten, doch es liefert in unter drei Sekunden solide, ansprechende Bilder. Vor allem ermöglicht es schnelle, lokale und 100% datenschutzfreundliche Bildbearbeitung on-the-fly (z.B. das Hinzufügen eines Regenbogens, das Entfernen von Personen im Hintergrund oder das Umwandeln eines Selfies in ein stilisiertes Ölgemälde), ohne jemals auf eine Internetverbindung oder teure Cloud-Abos angewiesen zu sein.
Fazit & Ausblick: Das Zeitalter der Spezialisierung, Agenten und Dezentralisierung
Wenn wir die massiven Entwicklungen und Veröffentlichungen allein dieser ersten Aprilwoche 2026 analytisch betrachten, zeichnet sich ein unübersehbares, weitreichendes Muster ab: Die Ära der gigantischen, monolithischen und primär cloud-gebundenen "One-Size-Fits-All"-Modelle nähert sich langsam, aber sicher ihrem konzeptionellen Ende. Stattdessen bewegen wir uns rasant auf ein hochdynamisches Ökosystem zu, das durch drei wesentliche technologische Säulen definiert wird:
- Edge Computing & Radikale Effizienz: Modelle wie Google Gemma 4 und ByteDance Dreamlight beweisen eindrucksvoll, dass massive, energiehungrige Rechenzentren nicht mehr für jede noch so kleine KI-Aufgabe zwingend notwendig sind. Durch ausgeklügelte Quantisierungsverfahren, extrem kompakte Architekturen und intelligente "Mixture-of-Experts"-Ansätze wandert die geballte künstliche Intelligenz direkt auf unsere lokalen Endgeräte. Dies löst nicht nur drängende Latenz- und Datenschutzprobleme souverän, sondern demokratisiert den Zugang zu High-End-KI-Funktionen auf globaler Ebene.
- Echtes multimodales und kausales Verständnis: KI beginnt, unsere reale Welt nicht mehr nur als abstrakte Folge von Text-Token oder flachen Pixelrastern zu begreifen. Innovative Technologien wie der Generative World Renderer, Alibabas Qwen 3.5 Omni oder Googles bahnbrechendes V GGPO (Latent Geometry Model) statten Algorithmen mit einem echten dreidimensionalen, physikalischen und zeitlichen Verständnis aus. Sie wissen schlichtweg, dass Wände solide Barrieren sind, dass virtuell gelöschte Objekte keine echten physikalischen Effekte mehr auslösen können und dass Licht und Schatten sich logisch entsprechend der Raumgeometrie verhalten müssen.
- Agentische Frameworks statt isolierter Text-Prompts: Der aufsehenerregende Leak des Anthropic Claude Codes sowie der immense praktische Erfolg von Architekturen wie PS Designer unterstreichen eine fundamentale Wahrheit: Die clevere Orchestrierung der KI – also das systematische Planen, tiefgehende Reflektieren, externe Suchen (wie beim Gen Searcher) und methodische Korrigieren durch unzählige interagierende Sub-Agenten – ist der wahre Schlüssel zur vollständigen Automatisierung extrem komplexer menschlicher Arbeitsabläufe. Wir interagieren in naher Zukunft nicht mehr mit einem passiven "Chatbot", sondern delegieren ganze Projekte an ein hochspezialisiertes Team von virtuellen Fachexperten.
Für Softwareentwickler, UI/UX-Designer, Filmemacher, Marketing-Experten und generelle Technikenthusiasten bedeuten diese neuartigen Werkzeuge eine beispiellose, fast schon beängstigende Erweiterung ihres kreativen und operativen Handlungsspielraums. Der erbitterte, aber fruchtbare Wettbewerb zwischen idealistischen Open-Source-Initiativen und den kapitalstarken, geschlossenen Laboren treibt die globale Innovation in einer iterativen Geschwindigkeit voran, die selbst die größten Technologie-Optimisten im Silicon Valley derzeit überrascht.
In einer schnelllebigen Welt, in der sich die mächtigsten digitalen Werkzeuge fast wöchentlich neu erfinden und gegenseitig übertreffen, wird in Zukunft nicht das starre Beherrschen eines spezifischen Software-Tools entscheidend für den beruflichen Erfolg sein, sondern die geistige Flexibilität, Anpassungsfähigkeit und das tiefe architektonische Verständnis dafür, wie man komplexe agentische KI-Systeme orchestriert und lenkt.
Redaktioneller Kommentar, KI-Trends & Analyse 2026
Dieser umfangreiche Blog-Beitrag fasst detailliert die rasanten technologischen Entwicklungen, Whitepaper-Releases und Modell-Vorstellungen aus der globalen Tech- und Entwickler-Community der vergangenen Woche zusammen. Teile der Erkenntnisse wurden inspiriert durch aktuelle kuratierte Zusammenfassungen wie das aktuelle AI Search News-Roundup. Die Zukunft der Technologie schläft nie, und der nächste Durchbruch steht bereits unmittelbar bevor.
 ZS Studio - Ihr Partner für erstklassige Webentwicklung
ZS Studio - Ihr Partner für erstklassige WebentwicklungIn einer digitalen Welt, die sich ständig weiterentwickelt, ist eine leistungsstarke und skalierbare Website das Fundament Ihres Unternehmenserfolgs. Wir unterstützen Unternehmen dabei, technologische Hürden zu überwinden und digitale Erlebnisse zu schaffen, die sowohl technisch als auch strategisch überzeugen.
Suchen Sie nach einem erfahrenen Partner für Ihr nächstes Web-Projekt? Erfahren Sie mehr über unsere Leistungen auf unserer Unternehmenswebsite oder vereinbaren Sie direkt ein unverbindliches Erstgespräch für eine kostenlose Website-Analyse über unser Kontaktformular.
Lassen Sie uns gemeinsam Ihre digitale Präsenz auf das nächste Level heben.