Die Welt der Künstlichen Intelligenz schläft nie. Wer dachte, die Innovationskurve würde sich nach den epochalen Durchbrüchen der vergangenen Jahre abflachen, wird im Frühjahr 2026 eines Besseren belehrt. Wir erleben derzeit eine faszinierende Konvergenz von multimodaler Wahrnehmung, physischer Verkörperung in Robotik, extrem effizienten Open-Source-Modellen und einer völlig neuen Ära der Videogenerierung, die nicht mehr nur visuell beeindruckt, sondern echtes räumliches und physikalisches Verständnis demonstriert. Dieser Artikel taucht tief in die technologischen Erdbeben dieser Woche ein und analysiert, wie diese Entwicklungen die Art und Weise, wie wir arbeiten, forschen und mit Maschinen interagieren, fundamental verändern werden.
Die Evolution der Videogenerierung: Von Pixel-Wahrscheinlichkeit zu echtem physikalischen "Reasoning"
Noch vor wenigen Monaten bestanden die größten Herausforderungen der KI-gestützten Videogenerierung darin, zeitliche Konsistenz zu wahren. Ein generiertes Auto sollte sich nach fünf Sekunden nicht in einen fliegenden Toaster verwandeln. Heute, im Jahr 2026, sind wir einen gewaltigen Schritt weiter: KI-Modelle beginnen, die zugrunde liegende Physik und Logik der von ihnen gerenderten Szenen zu "verstehen".
VBVR (Very Big Video Reasoning Suite) revolutioniert Open-Source-Video
Ein absolutes Highlight ist die Vorstellung der Very Big Video Reasoning Suite (VBVR). Dieses Framework, das als intelligenter "Aufsatz" (Layer) für existierende Videogeneratoren wie das Open-Source-Modell Wan 2.2 fungiert, verleiht der KI eine bislang unerreichte Fähigkeit zum logischen Schließen (Reasoning) innerhalb bewegter Bilder.
Während herkömmliche Modelle Pixel lediglich aufgrund statistischer Wahrscheinlichkeiten anordnen, kann VBVR komplexe visuelle und physikalische Puzzles lösen. Ein Paradebeispiel: Gibt man dem Modell das Startbild eines physikalischen Experiments – etwa zwei verbundene Wasserbehälter mit ungleichem Füllstand –, so generiert VBVR ein Video, das den korrekten physikalischen Prozess des Flüssigkeitsausgleichs (Fluid Equilibrium) bis zum Stillstand exakt simuliert. Ebenso meistert das System geometrische Aufgabenstellungen, bei denen es die richtige Form für eine vorgegebene Lücke identifizieren und die Bewegung dorthin animieren muss.
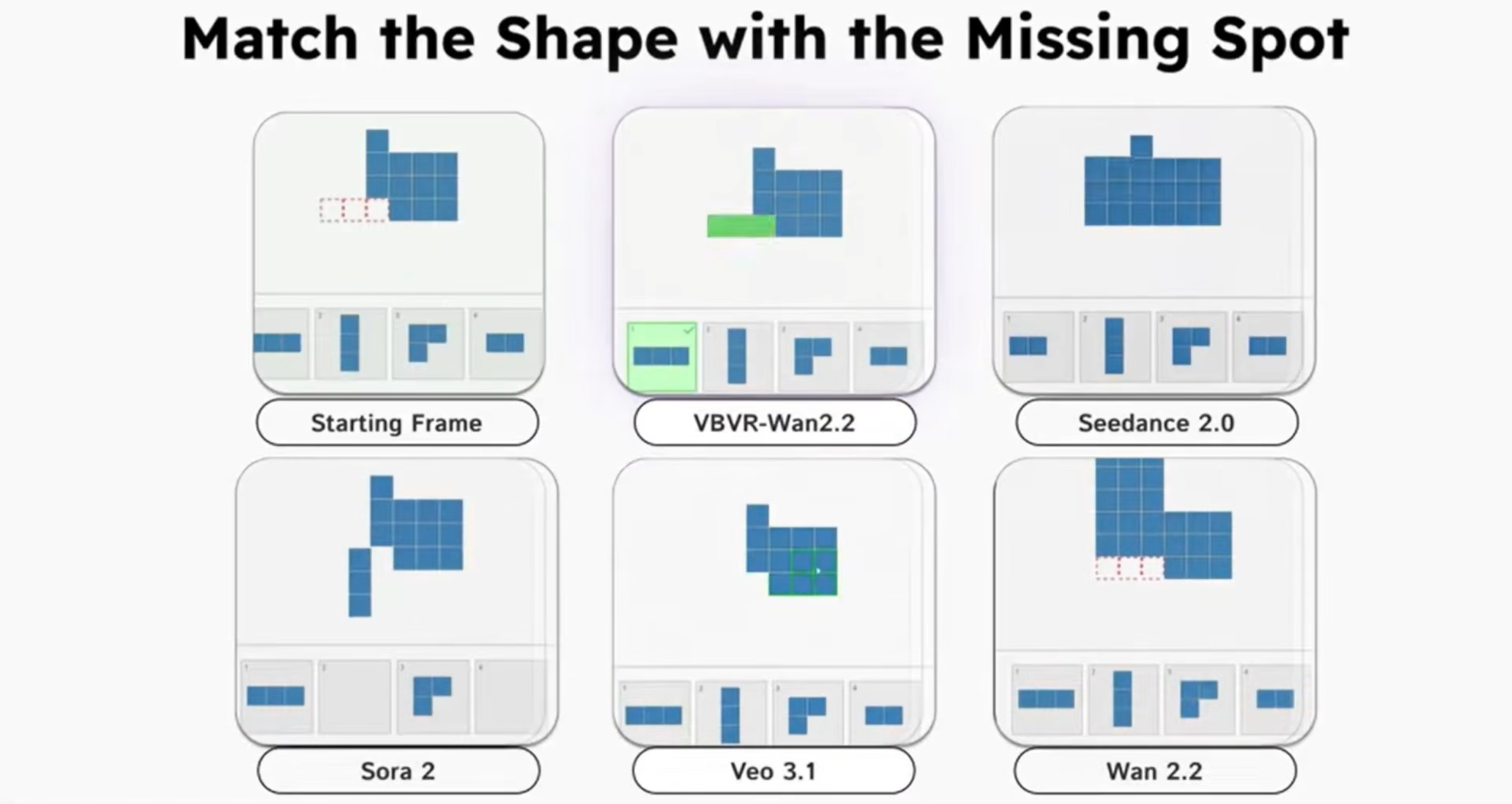
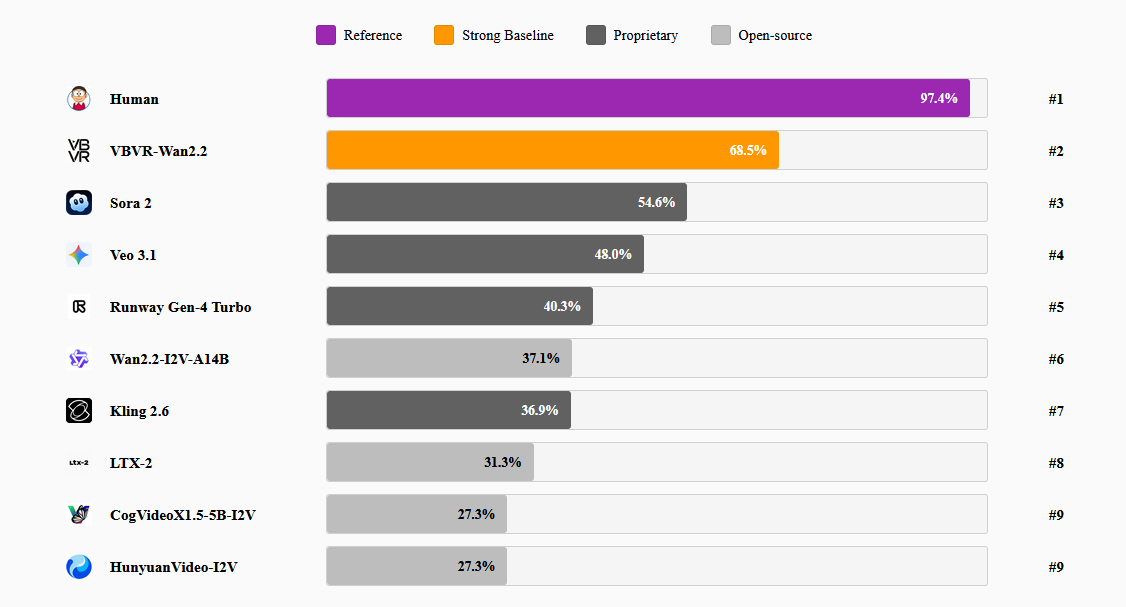
Ein Blick auf die Metriken verdeutlicht den Durchbruch: Während ein Mensch diese visuellen Tests zu rund 97,4 % besteht, scheitern prominente Modelle wie Sora 2 oder Veo 3.1 reihenweise und landen bei unter 55 % Genauigkeit. Die Kombination aus VBVR und Wan 2.2 hingegen katapultiert sich auf beeindruckende 68,5 % und degradiert damit milliardenschwere proprietäre Modelle.
PhysicEdit: Wenn Bildbearbeitung die Gesetze der Thermodynamik kennt
Diese Entwicklung hin zu physikalisch akkuraten Modellen zeigt sich auch in PhysicEdit, einem neuen Bildeditor, der auf der Architektur von Qwen Image Edit basiert. Wenn Sie diesem Tool befehlen, "das Eis schmelzen zu lassen" oder "einen Strohhalm in ein Wasserglas einzuführen", berechnet es korrekte Lichtbrechungen (Refraktionen), Aggregatzustandsänderungen und Materialermüdungen (z. B. das Zusammenbrechen eines Kartenhauses oder das Austrocknen einer Pflanze). Dies beweist, dass Diffusionsmodelle beginnen, ein latentes Verständnis für die 3D-Welt und ihre physikalischen Gesetzmäßigkeiten zu entwickeln, anstatt nur 2D-Texturen zu imitieren.
ByteDance Dream ID Omni: Der heilige Gral der multimodalen Deepfakes
Parallel zur physikalischen Korrektheit erreicht auch die fotorealistische Synthese neue Höhen. ByteDance kündigt mit Dream ID Omni einen Videogenerator an, der Text-, Bild- und Audio-Inputs simultan verarbeitet. Bemerkenswert ist die Fähigkeit, das Gesicht und die Stimme einer Referenzperson (z.B. eines Schauspielers) nahtlos in ein völlig neues Video zu übertragen – lippensynchron und mit Beibehaltung der emotionalen Nuancen in Mimik und Tonalität. Diese Technologie birgt enormes Potenzial für die Filmproduktion und Lokalisierung, wirft aber einmal mehr ernsthafte ethische Fragen bezüglich der Erstellung hyperrealistischer Deepfakes auf.
Solaris Engine: Der Schritt zu Multi-Agenten Weltmodellen
Wir alle kennen KI-generierte Videos aus der Egoperspektive, doch die Solaris Engine durchbricht eine völlig neue Barriere: Die simultane Videogenerierung aus den Blickwinkeln mehrerer Akteure in derselben Umgebung.
Solaris konzentriert sich aktuell auf das Spiel Minecraft als Sandbox. Das revolutionäre an diesem Modell ist nicht die Grafik, sondern das zugrunde liegende Raumverständnis. Die KI generiert gleichzeitig Video A (Perspektive von Spieler 1) und Video B (Perspektive von Spieler 2). Baut Spieler 1 einen Block ab, sieht Spieler 2 diesen Vorgang zeitgleich aus seinem eigenen Betrachtungswinkel. Dies erfordert ein tiefes, inhärentes 3D-Weltmodell innerhalb des neuronalen Netzes.
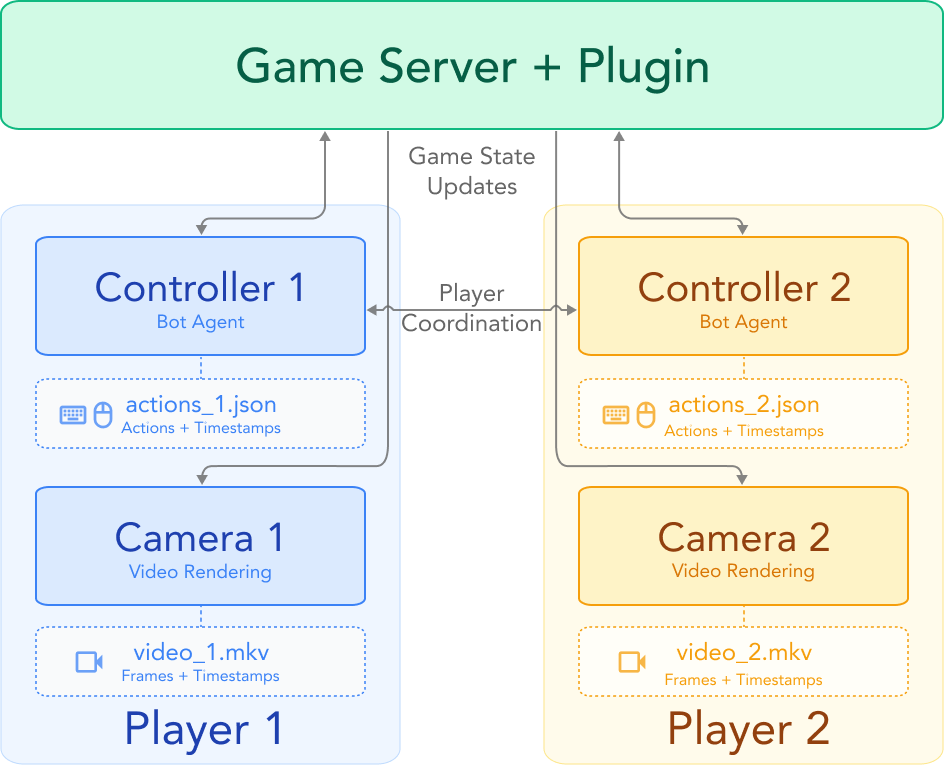
Um dieses Modell zu trainieren, bauten die Entwickler eine Engine, die autonome KI-Bots in Minecraft koordinierte. Diese Bots interagierten, kämpften, bauten und sammelten Ressourcen, während das System ihre jeweiligen Ego-Perspektiven aufzeichnete. Das Resultat ist ein gigantischer Datensatz mit über 6,32 Millionen Frames pro Agent.
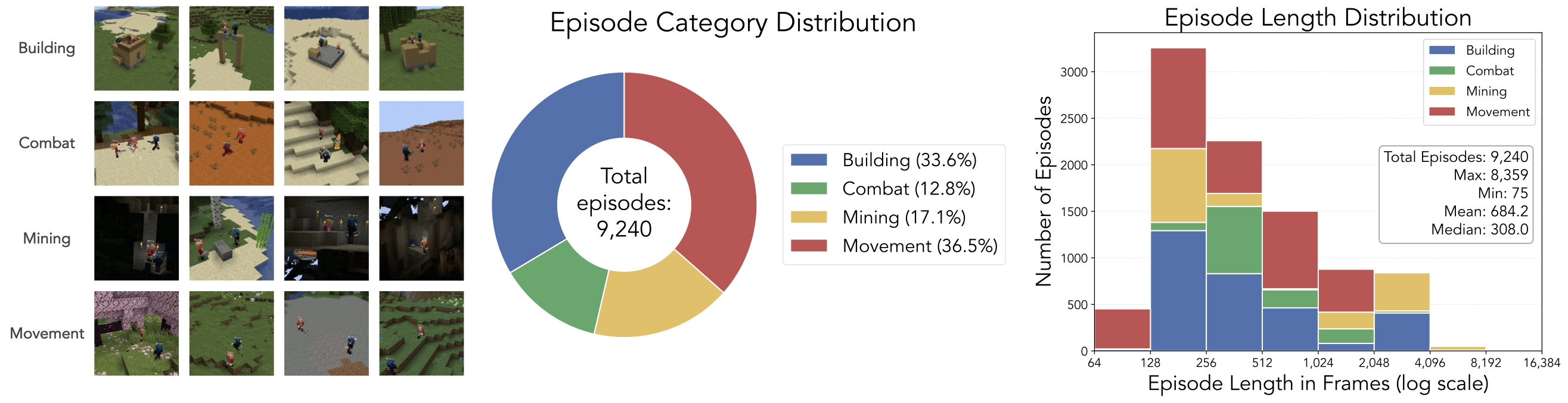
Warum ist das relevant, auch außerhalb von Videospielen? Die Antwort lautet: Synthetische Daten für Robotik-Schwärme. Wenn wir Fabriken der Zukunft bauen, in denen Dutzende humanoide Roboter zusammenarbeiten, benötigen diese ein gemeinsames Verständnis ihrer Umgebung. Solaris beweist, dass KI-Modelle fähig sind, multi-perspektivische, konsistente Umgebungen zu simulieren, was ein entscheidender Schritt für das "Sim-to-Real" Training kooperativer Robotik ist.

Die Demokratisierung der Super-Intelligenz: Qwen 3.5 und lokales Hosting
Während Modelle immer leistungsfähiger werden, stellt sich zunehmend die Frage der Zugänglichkeit. Brauchen wir alle bald Serverfarmen in unseren Kellern? Alibaba sagt ganz klar: Nein. Mit der Veröffentlichung von Qwen 3.5 wird die Landschaft der Large Language Models (LLMs) neu geordnet.
Qwen 3.5 reiht sich nahtlos in die Liga der Giganten wie GPT-5.2, Gemini Advanced und Claude ein. Was dieses Release jedoch historisch macht, ist nicht das massive Flaggschiffmodell mit hunderten Milliarden Parametern, sondern die extrem destillierten, kleineren Varianten (2B, 27B und 35B Parameter). Diese "kleinen" Modelle performen in anspruchsvollen Benchmarks auf dem Niveau, das vor kurzem noch den absolut größten Modellen vorbehalten war.

Durch fortschrittliche Quantisierungsverfahren (wie FP8) und Werkzeuge von Unsloth schrumpft der VRAM-Bedarf massiv. Ein hochintelligentes 27-Milliarden-Parameter-Modell, das fähig ist, tiefgehende Codierungs-, Mathematik- und Logikaufgaben zu lösen, passt dank dieser Optimierungen in lediglich 10 bis 12 GB VRAM. Das bedeutet, dass Entwickler, Forscher und Enthusiasten mit handelsüblichen Consumer-Grafikkarten hochkomplexe KI lokal, datenschutzkonform und latenzfrei betreiben können.
Das Gedächtnisproblem gelöst: Sakana AIs "Doc to LoRA" Paradigmenwechsel
Eines der frustrierendsten Probleme bei der Arbeit mit LLMs ist das begrenzte Kontextfenster. Gibt man einem Modell ein 100-seitiges Dokument, vergisst es oft wichtige Details in der Mitte ("Lost in the Middle"-Phänomen) oder die Inferenz wird extrem langsam und teuer, da bei jeder neuen Frage der gesamte Text erneut verarbeitet (Tokenized und durch die Attention-Layer geschickt) werden muss.
Das japanische Startup Sakana AI hat hierfür eine bahnbrechende Lösung präsentiert: Doc to LoRA und Text to LoRA. Anstatt das Dokument in den Prompt (den Eingabekontext) zu kopieren, nutzt ein Hypernetzwerk das Dokument, um blitzschnell einen kleinen Adapter – eine sogenannte LoRA (Low-Rank Adaptation) – zu trainieren. Dieser Adapter enthält das destillierte Wissen des Dokuments in Form von neuronalen Gewichten.
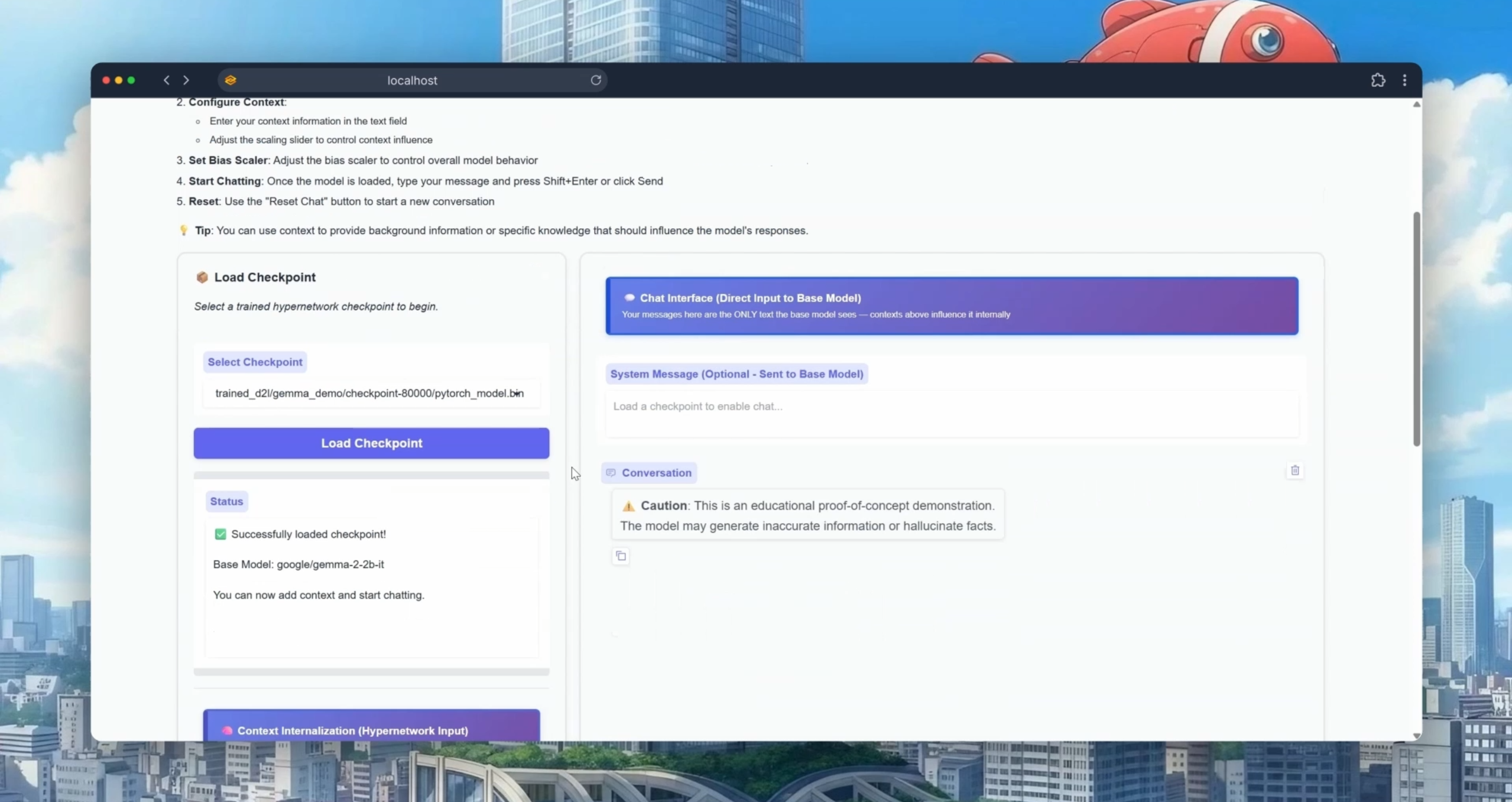
Dieser Ansatz ist genial: Wenn Sie nun Fragen zu Ihrem Dokument stellen, laden Sie einfach diese winzige LoRA auf Ihr Basismodell. Das Modell "erinnert" sich an das Dokument, als hätte es dieses seit Anbeginn der Zeit auswendig gelernt. Das Ergebnis sind blitzschnelle Antwortzeiten, null Einschränkungen durch Kontextfenster-Limits und ein persistentes, aufgabenspezifisches Gedächtnis. Das Gleiche funktioniert für komplexe System-Anweisungen (Text to LoRA), sodass Sie das Verhalten Ihres Modells dauerhaft formen können, ohne bei jeder Chat-Session seitenlange Instruktionen mitschicken zu müssen. Faszinierenderweise können so sogar Bildinformationen aus PDFs in die Gewichte encodiert werden, wodurch textbasierte Modelle Fragen zu diesen Bildern beantworten können, ohne über echte Vision-Fähigkeiten zu verfügen.
Verkörperte KI: Humanoide Roboter erobern die Industrie
Die Software lernt sehen und denken – doch erst die Hardware bringt diese Intelligenz in die reale Welt. Die aktuelle Woche markiert einen signifikanten Wendepunkt im Bereich der "Embodied AI" (verkörperte Künstliche Intelligenz).
Agibot G2: Der Meister der Sub-Millimeter-Präzision
Während viele Unternehmen humanoide Roboter bauen, die auf zwei Beinen laufen (was extrem viel Rechenleistung für die Balance erfordert), geht der Hersteller Agibot mit dem Agibot G2 einen bestechend pragmatischen Weg für industrielle Umgebungen. Dieser Roboter besitzt einen Radantrieb, konzentriert seine gesamte Rechenleistung jedoch auf den extrem komplexen Oberkörper und die Hände.

Angetrieben von einem massiven Nvidia Jetson T5000 Chip (der über 2.000 Teraflops an Edge-Computing-Leistung liefert), navigiert der G2 völlig autonom durch Fabrikhallen. Seine wahre Magie liegt in den Händen: Mit 19 Freiheitsgraden (Degrees of Freedom) allein in den Manipulatoren greift dieser Roboter empfindliche elektronische Bauteile wie Computer-RAM-Riegel oder Prozessoren und setzt diese mit absoluter Sub-Millimeter-Präzision zusammen. Ein integriertes Hot-Swap-Batteriesystem ermöglicht einen 24/7-Betrieb ohne Ausfallzeiten.

Nvidia Ego Scale: Roboter lernen durch Zusehen
Die Hardware ist bereit, aber wie programmiert man einen Roboter für Tausende verschiedene Aufgaben? Hartcodierung ist keine Option. Nvidia hat mit dem Ego Scale System die Antwort gefunden. Ego Scale ist ein Vision-Language-Action (VLA) Modell, das auf über 20.000 Stunden Videomaterial aus der menschlichen Ego-Perspektive trainiert wurde.
Das Prinzip: Der Roboter schaut sich Videos an, in denen Menschen Wäsche falten, Werkzeuge benutzen, kochen oder Flaschen öffnen. Das Modell extrahiert die genauen Handposen, korreliert sie mit textlichen Anweisungen und übersetzt sie in motorische Befehle für die Roboter-Gelenke. Anstatt jeden Millimeter einer Bewegung mühsam zu programmieren, lernt der Roboter schlicht durch Imitation – exakt so, wie ein menschliches Kind lernt.
Unitrees eiserner Wolf
Doch auch außerhalb ebener Fabrikhallen gibt es enorme Fortschritte. Unitree Robotics demonstrierte die neueste Iteration ihres Roboterhundes. Diese Maschine ist kein Spielzeug mehr: Sie sprintet mit 5 Metern pro Sekunde über unwegsamstes, zerklüftetes Terrain, ist IP54 wetterfest und kann dabei bis zu 105 Kilogramm Nutzlast tragen. Die Einsatzmöglichkeiten für Search-and-Rescue-Missionen in Katastrophengebieten sind schier grenzenlos.
Von 3D-Rekonstruktion bis Audio-Magie: Die Werkzeuge der Creator
Auch kreative Workflows erfahren einen massiven Effizienz-Boost durch neue Open-Source-Modelle.
TTTLRM: Fotorealistisches 3D aus 2D-Bildern
Die Generierung von 3D-Assets war bisher oft fehleranfällig, und Techniken wie 3D Gaussian Splatting (3DGS) erzeugten in komplexen Umgebungen oft Artefakte, Rauschen oder fliegende Wolken. TTTLRM (Test Time Training for Long Context Autoregressive 3D Reconstruction) ändert das. Das System nutzt "Fast Weights", um die Parameter des Modells in Echtzeit an die hochgeladenen Bilder eines Tempels, eines Innenhofs oder eines Objekts anzupassen. Das Resultat sind glasklare, extrem detailreiche 3D-Rekonstruktionen, die selbst feinste Kabel oder Texturen auf Plakaten bewahren. Und das Beste: Das Modell ist kleiner als 4 GB und läuft auf Consumer-Grafikkarten.
Vec Glypher: Skalierbare Vektorgrafiken und Schriften
Eine weitere Lücke im KI-Arsenal waren bisher Vektorgrafiken (SVGs). Während Midjourney und DALL-E atemberaubende Pixelbilder erzeugen, sind diese für Logos oder Typografie oft ungeeignet, da sie bei Vergrößerung verpixeln. Vec Glypher (von Quiver) schließt diese Lücke bravourös. Ob durch Texteingabe oder basierend auf einem hochgeladenen Bild – das Modell generiert makellose mathematische Pfade. Sie können eine komplette Schriftart entwerfen lassen, indem Sie dem Modell nur den Stil "Vintage, verspielt, handgeschrieben" mitgeben. In aktuellen Benchmarks deklassiert Vec Glypher dabei universelle Modelle wie Claude oder GPT haushoch, da es dezidiert auf die Erstellung von Vektor-Geometrie spezialisiert ist.
Lava SR & Sony Audio: Die Sound-Revolution
Visuelle Exzellenz benötigt herausragendes Audio. Hier brilliert Lava SR, ein winziges 50-Megabyte-Modell, das Hintergrundrauschen aus Sprachaufnahmen entfernt und die Audioqualität signifikant verbessert. Seine Effizienz ist astronomisch: Auf einer GPU verarbeitet es Audio 5.000-mal schneller als in Echtzeit, auf einer gewöhnlichen CPU immer noch 60-mal schneller. Perfekt für den Einsatz in mobilen Apps.
Für die Videoproduktion liefert Sony mit seiner neuen AI, basierend auf dem MMHNet (Multimodal Hierarchical Networks) in Kombination mit der Mamba-Architektur, ein Werkzeug, das passende Soundeffekte und Atmosphären für bis zu 5-minütige Videos generiert. Der generierte Sound passt sich dynamisch an Bildschnitte und Aktionen der Charaktere an – ein massiver Fortschritt gegenüber bisherigen Modellen, die oft asynchron klangen oder bei langen Clips inkonsistent wurden.
Die Zukunft ist immersiv: Interaktive VR und Digitale Entitäten
Was passiert, wenn wir Echtzeit-Videogenerierung mit großen Sprachmodellen und Virtual Reality kombinieren? Wir betreten das Zeitalter der dynamischen XR (Extended Reality).
Ein experimentelles Projekt namens Generated Reality ermöglicht es Usern, ein VR-Headset aufzusetzen, das Kopf- und Handbewegungen trackt. Ein KI-Modell generiert in Echtzeit (aktuell bei ca. 11 Frames pro Sekunde) eine visuelle Welt um den Nutzer herum. Egal ob Sie mit einem Ritter kämpfen, eine Fackel halten oder einen Hund streicheln wollen – das Diffusionsmodell rendert die Welt interaktiv basierend auf Ihren physischen Bewegungen und Prompts.
Parallel dazu entwickelt sich die parasoziale Interaktion. Das Modell SARA präsentiert hochgradig realistische "Virtual Waifus" oder virtuelle Partner in VR. Anstelle starrer 3D-Avatare nutzt SARA Echtzeit-Modelle, um flüssige, körpersprachlich extrem nuancierte Antworten zu generieren. Die Entität reagiert nicht nur verbal in Echtzeit, sondern hält natürlichen Blickkontakt, gestikuliert dynamisch und dreht ihren Kopf zu Ihnen im virtuellen Raum. Die Kombination aus extrem geringer Latenz und natürlicher Kinematik verwischt die Grenzen zwischen Mensch-Maschine-Schnittstelle und zwischenmenschlicher Interaktion auf eine faszinierende, wenn auch teilweise irritierende Weise.
Fazit: Die Architektur von morgen wird heute gebaut
Die Fülle an Innovationen – sei es das logische Denken in Videos durch VBVR, die Revolution der Edge-LLMs durch Qwen 3.5, das radikal neue Speicher-Paradigma von Sakana AI oder die unglaubliche physische Präzision von Robotern wie dem Agibot G2 – verdeutlicht einen zentralen Aspekt: KI ist längst nicht mehr nur ein Chatbot im Browserfenster. Sie wird räumlich, sie wird physisch greifbar, und sie durchdringt die physischen Gesetze unserer Welt. Entwickler und Unternehmen, die diese neuen Paradigmen adaptieren – insbesondere durch Nutzung der vielen Open-Source-Veröffentlichungen –, werden die digitale und physische Zukunft der kommenden Dekade maßgeblich gestalten.
Die Informationen und gezeigten Entwicklungen in diesem Artikel basieren auf den umfangreichen Recherchen und Vorstellungen des Tech-Channels "AI Search", veröffentlicht am 1. März 2026. Eine vollständige Zusammenfassung der Demos finden Sie im Originalvideo.
AI Search (YouTube): Realtime AI waifus, Qwen 3.5, persistent memory, multiplayer gameplay, new image models: AI NEWS