
Die Welt der Künstlichen Intelligenz schläft nie, und die Entwicklungen, die wir in dieser Woche beobachten durften, sprengen buchstäblich die Grenzen dessen, was Industrie und Forschung noch vor wenigen Monaten für realisierbar hielten. Wir stehen an der Schwelle zu einer Ära, in der Sprachmodelle nicht mehr nur als abstrakter Code auf universellen Grafikkarten laufen, sondern direkt in Silizium gegossen werden. Gleichzeitig durchbrechen humanoide Roboter in Schwärmen die Gesetze der klassischen Robotik-Physik, und erste Foundation-Modelle für unsere Gehirnströme öffnen die Büchse der Pandora des "Gedankenlesens". Dieser umfassende Bericht beleuchtet die bahnbrechendsten KI-Innovationen dieser Woche, analysiert tiefgreifend die zugrundeliegenden Architekturen und zeigt, wie diese Durchbrüche unsere Technologielandschaft transformieren werden.
Alibaba Qwen 3.5: Der Open-Source-Gigant mit 1-Million-Token-Kontext
Die Open-Source-Community hat einen neuen König, und er kommt aus dem Hause Alibaba. Mit der Veröffentlichung von Qwen 3.5 wurde ein multimodales Modell präsentiert, das mit sagenhaften 397 Milliarden Parametern aufwartet. Doch die schiere Größe ist nur die halbe Wahrheit. Das Modell nutzt eine hocheffiziente Mixture-of-Experts (MoE) Architektur, bei der während einer Inferenz-Anfrage lediglich 17 Milliarden Parameter aktiv geschaltet werden. Dies sorgt für eine beispiellose Balance aus intellektueller Tiefe und rechnerischer Effizienz.

Das absolute Killer-Feature dieses Modells ist jedoch das gigantische Kontextfenster von 1 Million Token. Um das in Relation zu setzen: Sie können über 700.000 Wörter, ein komplettes mittelständisches Software-Repository oder ein über einstündiges Video auf einen Schlag in den Prompt laden. Die Zeiten, in denen man komplexe RAG-Pipelines (Retrieval-Augmented Generation) bauen musste, nur um einem Modell den Kontext eines Handbuchs beizubringen, nähern sich rapider Obsoleszenz.

Obwohl die vollen Gewichte des Modells (87 GB) eigene Server-Infrastrukturen voraussetzen, beweist Alibaba durch die Bereitstellung auf der Qwen-Chat-Plattform, dass modernste KI-Technologie nicht hinter proprietären Paywalls verschlossen bleiben muss. Qwen 3.5 ist ein Meilenstein für die Demokratisierung der Künstlichen Intelligenz.
Taalas HC1: Der Paradigmenwechsel – Wenn KI zur Hardware wird
Seit Jahrzehnten leidet die Informatik unter dem sogenannten Von-Neumann-Flaschenhals. In der modernen KI bedeutet dies: Milliarden von Modell-Parametern (Gewichten) müssen ständig zwischen dem extrem schnellen Prozessor und dem Speicher (HBM oder VRAM) hin- und hergeschoben werden. Dieser Datentransfer kostet massiv Zeit und unfassbare Mengen an Energie. Das Start-up Taalas hat dieses Problem nun nicht durch bessere Software, sondern durch radikale Hardware-Architektur gelöst.

Der neue Taalas HC1-Chip ist kein universeller Prozessor, der jeden Code ausführen kann. Er wurde exklusiv und unveränderlich für Meta's Llama 3.1 Architektur gebaut. Das neuronale Netz lebt nicht mehr als PyTorch-Code im Software-Speicher, sondern als physische Leiterbahnen und SRAM-Zellen direkt auf dem Silizium. Speicher und Berechnung verschmelzen an ein und demselben Ort (Compute-in-Memory).
Die Resultate sind atemberaubend:
- Geschwindigkeit: Der Chip erreicht astronomische 17.000 Token pro Sekunde. Die KI antwortet buchstäblich schneller als der menschliche Gedanke.
- Kosten & Energie: Er verbraucht 10-mal weniger Strom und ist in der Herstellung 20-mal günstiger als aktuelle Universallösungen.
- Formfaktor: Es werden keine massiven Wasserkühlungen oder gigantische Server-Racks mehr benötigt.
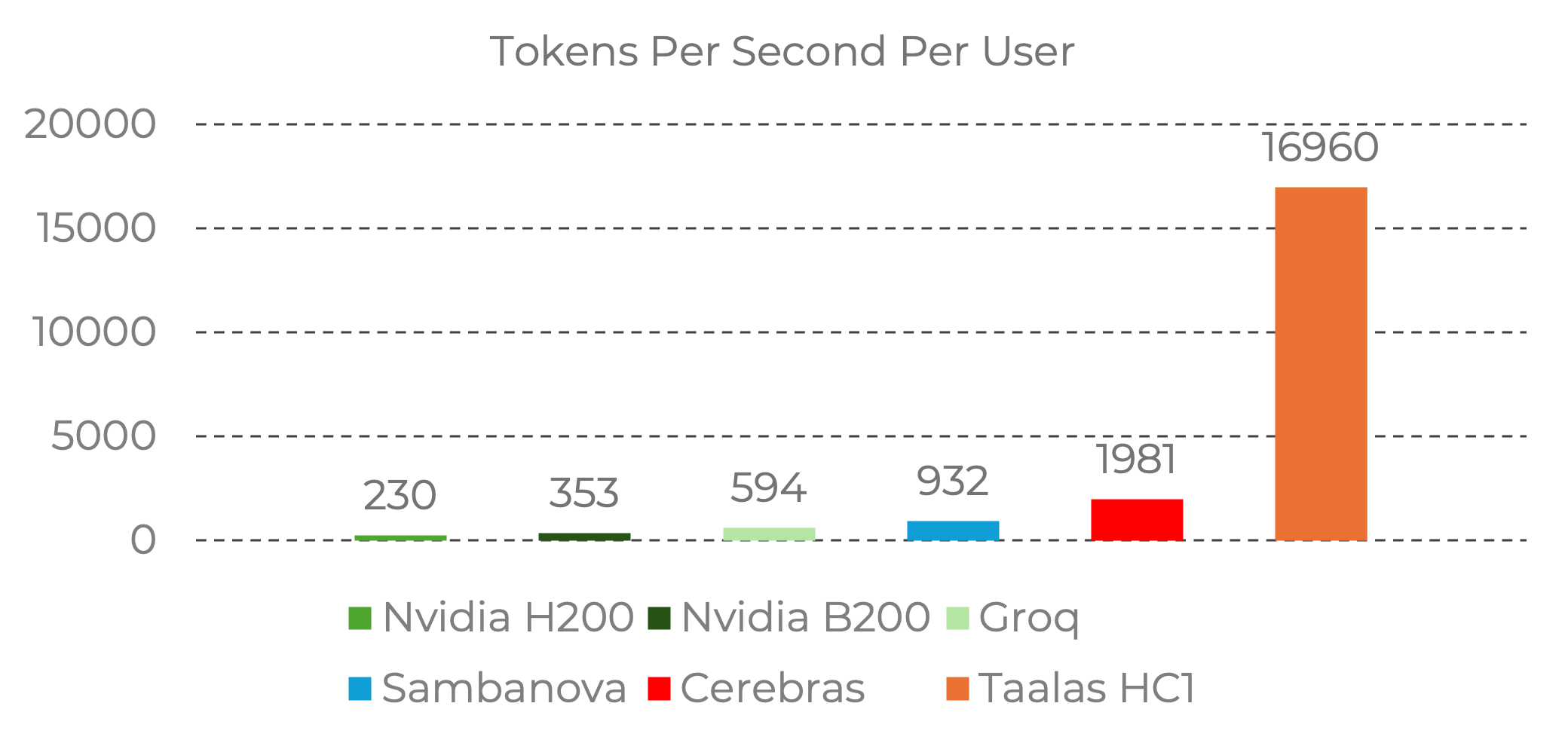
Wir nähern uns einer Zukunft, in der wir keine KI-Modelle mehr herunterladen, sondern KI-Chips kaufen, die auf bestimmte Aufgaben hartcodiert sind – ähnlich wie der Visual Cortex in unserem Gehirn.
Architektur-Philosophie der Hardwired AI
Natürlich gibt es einen Haken: Wenn morgen ein deutlich besseres Modell wie Llama 4 erscheint, kann man den Chip nicht einfach updaten. Die Hardware ist obsolet. Dennoch ist der Taalas HC1 der endgültige Beweis, dass Application Specific Integrated Circuits (ASICs) für LLMs die nächste Billionen-Dollar-Industrie sein werden.
Unitree G1: Akrobatik und Schwarmintelligenz auf einem neuen Level
Hardware-Innovationen beschränken sich nicht nur auf Chips. Im Bereich der Embodied AI (Verkörperlichte KI) hat das chinesische Unternehmen Unitree beim diesjährigen Spring Festival Gala 2026 eine Demonstration geliefert, die an Science-Fiction grenzt. Der Unitree G1 Roboter hat die Gesetze der klassischen Robotik neu geschrieben.

Wir sprechen hier nicht von Robotern, die staksig über eine ebene Fläche laufen. Die G1-Einheiten demonstrierten Sprünge von zwei bis drei Metern Höhe, gefolgt von perfekten, sequentiellen Rückwärtssaltos und Wandläufen. Solche Manöver erfordern ein explosives Actuator Torque (Drehmoment der Gelenke), das die Hardware an ihre absoluten physikalischen Grenzen bringt.
Noch beeindruckender als die individuelle Athletik war jedoch die Schwarmintelligenz. Dutzende dieser Roboter agierten in völliger Synchronität, ohne miteinander zu kollidieren. Eine zentrale Netzwerk-Intelligenz mit Near-Zero-Latency koordinierte die Masse, was den Weg für großflächige industrielle oder logistische Einsätze autonomer Flotten ebnet. Sogar das Balancieren von Nunchakus wurde demonstriert – eine Aufgabe, die den Schwerpunkt des Roboters bei jedem Schwung drastisch verändert und konstante mikrosekündliche Rekalibrierungen erfordert.
ZUNA Thought-to-Text: Der erste Schritt zum Gedankenlesen
Während Roboter physische Hürden überwinden, bricht das ZUNA-Projekt (Zero-shot Unsupervised Neural Architecture für EEG) in die tiefsten Sphären der menschlichen Kognition ein. Wir stehen am Beginn der Thought-to-Text Ära. ZUNA ist ein 380-Millionen-Parameter schweres BCI (Brain-Computer Interface) Foundation Model, das exklusiv für elektroenzephalographische (EEG) Daten entwickelt wurde.
Wer jemals mit EEG-Daten gearbeitet hat, weiß: Gehirnströme sind ein absolutes Albtraum-Szenario für die Datenanalyse. Die Signale sind schwach (im Mikrovolt-Bereich), extrem verrauscht durch Muskelartefakte oder Augenzwinkern und zudem abhängig von der exakten Platzierung der Elektroden. Genau hier setzt ZUNA an.
Anstatt naiv zu versuchen, Rohtext aus chaotischen Kurven zu generieren, nutzt ZUNA eine revolutionäre Autoencoder-Diffusion. Ähnlich wie Midjourney oder DALL-E Rauschen in klare Bilder verwandeln, lernt ZUNAs Diffusionsmodell, das "Rauschen" in unseren Gehirnströmen zu verstehen und ein kristallklares, rekonstruiertes Signal der tatsächlichen neuronalen Aktivität zu generieren.
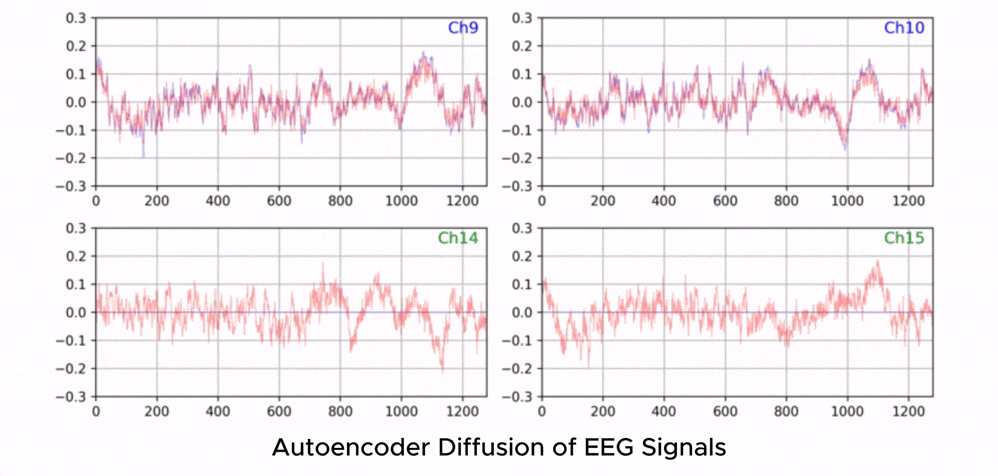
ZUNA kann beschädigte Signale reparieren und sogar die Daten von fehlerhaften Elektroden vorhersagen. Es fungiert als Übersetzer zwischen chaotischer Biologie und strukturierter Mathematik.
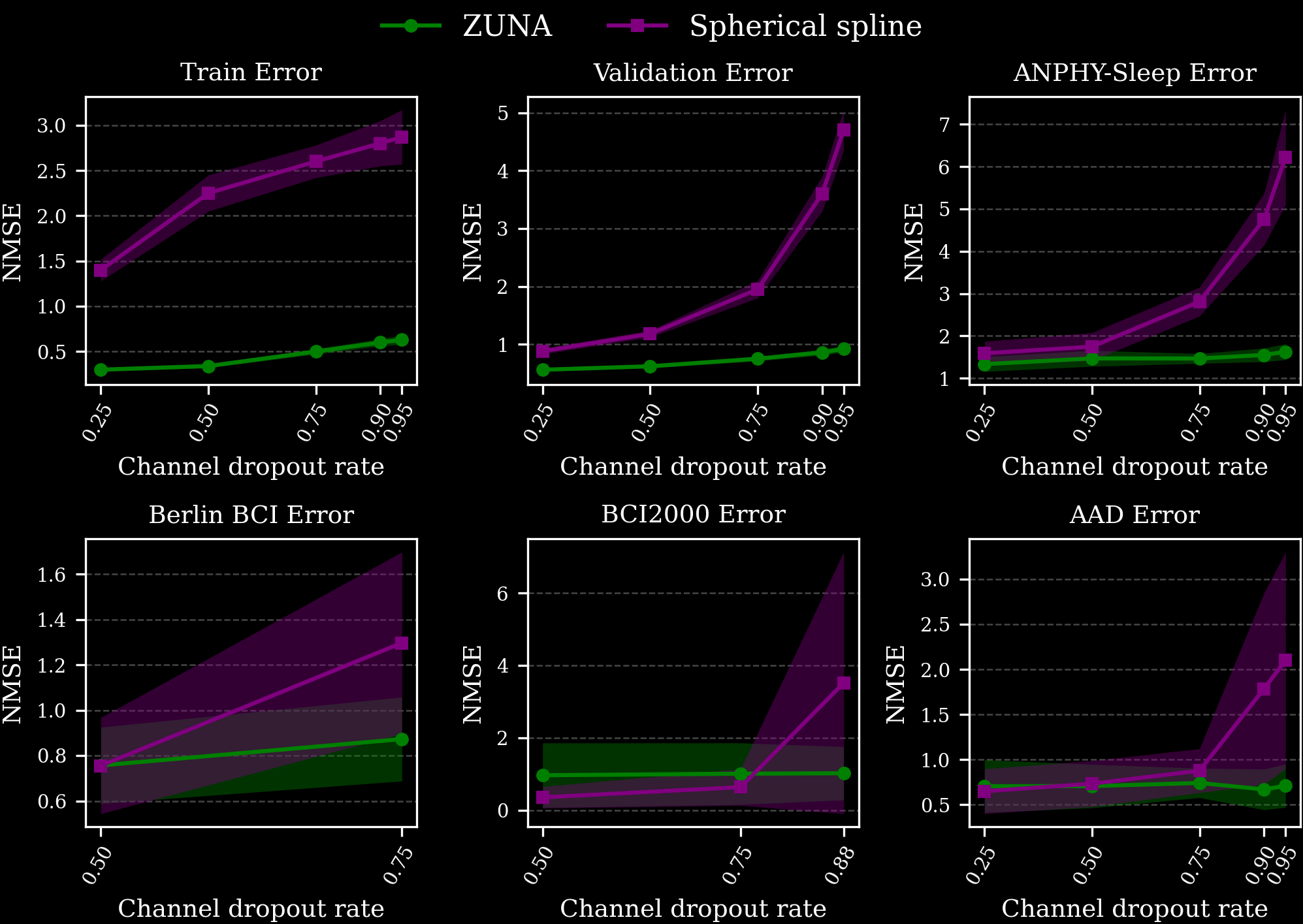
Obwohl das Modell heute noch nicht direkt Ihren inneren Monolog in ein Word-Dokument tippt, legt es das fundamentale Fundament. Indem ZUNA die Datenqualität standardisiert und entrauscht, liefert es künftigen LLMs exakt den sauberen Input, den diese benötigen, um bald semantische Muster (Worte, Intentionen) aus Gedanken zu extrahieren. Das Modell ist erfreulicherweise Open-Source und mit unter 2 GB VRAM lokal auf Konsumenten-Hardware lauffähig.
Gemini 3.1 Pro Preview: Google zementiert seine Spitzenposition
Im ewigen Schlagabtausch der KI-Giganten hat Google in dieser Woche ebenfalls ein massives Update ausgerollt: Gemini 3.1 Pro Preview. Obwohl es sich "nur" um ein Punkt-Release handelt, hat das Modell die unabhängigen Leaderboards im Sturm erobert.
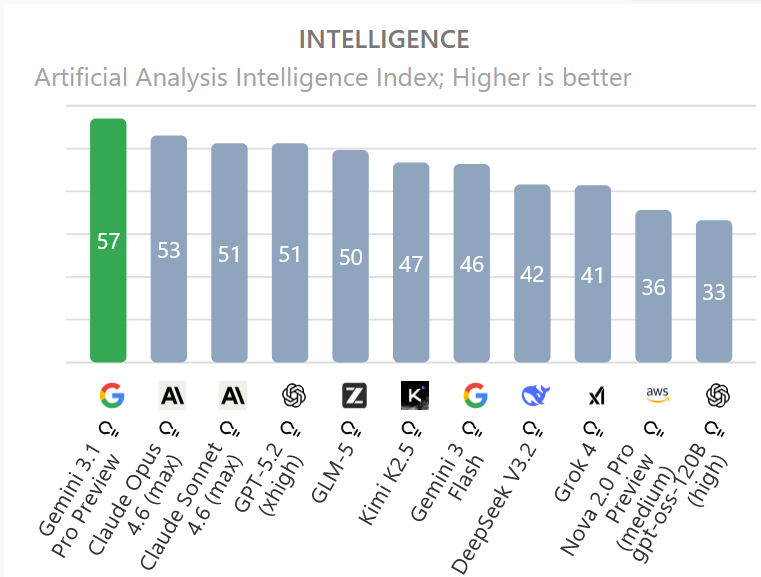
Googles Architektur-Vorteil bleibt die native Multimodalität. Gemini wurde nicht als Textmodell trainiert, dem später Bild- oder Audio-Adapter "aufgeklebt" wurden. Es begreift Pixel, Audio-Waveforms und Text-Tokens im selben latenten Raum. Diese tiefe Verknüpfung zeigt sich auch in Googles neuestem Geschenk an die Community: Lyria 3.
Die Explosion der generativen Medien: LUVE, Monarch RT und Audio X
Die Art und Weise, wie wir Medien konsumieren und produzieren, steht vor dem finalen Umbruch. Mehrere Open-Source-Veröffentlichungen diese Woche definieren die Parameter der Videogenerierung völlig neu.
LUVE: Der 4K-Meilenstein für KI-Video
Das Generieren von Videos war bisher stark limitiert durch VRAM-Grenzen – meist war bei 720p oder matschigen 1080p Schluss. Das LUVE-Framework löst dieses Problem durch eine brillante Neugestaltung der Upsampling-Architektur.
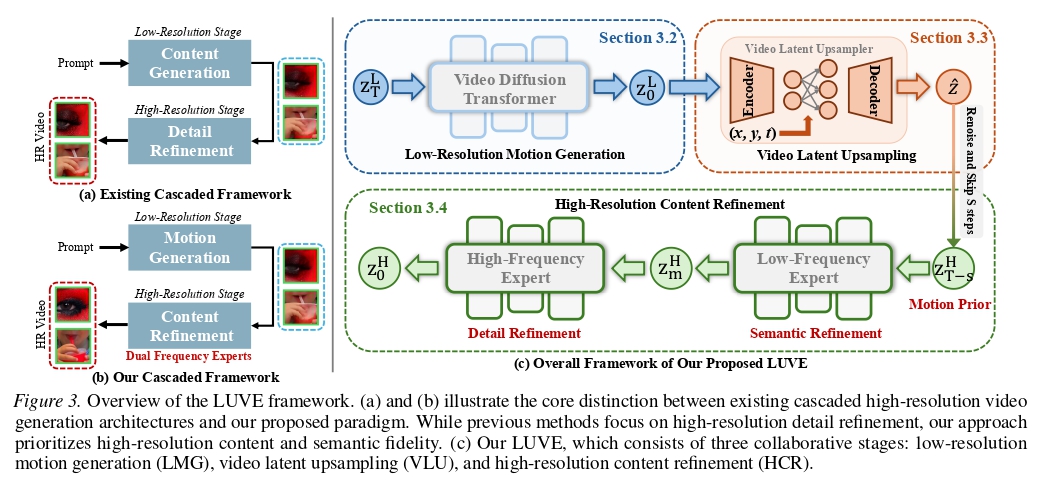
LUVE generiert Videos, bei denen jedes Härchen einer Biene auf einer Blüte oder die mikroskopischen Wasserwellen an einem Korallenriff in kristallklarem 4K gerendert werden. Im Gegensatz zu traditionellen Upscalern, die oft flackernde Artefakte erzeugen, bewahrt LUVE durch tiefe latente Netzwerke die räumlich-zeitliche (spatiotemporal) Kohärenz über dutzende von Frames hinweg.
Monarch RT: Echtzeit-Video auf dem heimischen Rechner
Während LUVE sich auf Qualität fokussiert, löst Monarch RT das Problem der Geschwindigkeit. Die Software ermöglicht echte Echtzeit-Videogenerierung mit 16 Bildern pro Sekunde auf einer Consumer-GPU (z. B. der RTX 5090). Durch den Austausch der rechenintensiven Dense Attention-Mechanismen gegen hocheffiziente Berechnungen erzielt Monarch RT eine viermal höhere Leistung als modernste Flash-Attention-Methoden, bei nahezu 95 % Beibehaltung der visuellen Qualität.
Audio X: Das Schweizer Taschenmesser für Sound
Um die visuelle Revolution akustisch zu untermalen, wurde das Audio X Modell vorgestellt. Es ist ein hochgradig vereinheitlichtes Modell für alles, was hörbar ist. Mit nur knapp 6 Gigabyte Größe kann dieses Modell lokal ausgeführt werden und bietet unfassbare Funktionen:
- Text/Video-to-Audio: Es erkennt harte Schnitte in hochgeladenen Videos und generiert bildgenau synchronisierte Soundeffekte.
- Audio-Inpainting: Es kann Störgeräusche in Audio-Spuren nahtlos herausrechnen oder fehlende Audio-Sektionen logisch und stimmlich konsistent auffüllen.
- Audio-Continuation: Es verlängert bestehende Musikstücke in einem gewünschten Genre ohne hörbare Brüche.
Weitere Highlights im Schnelldurchlauf
Die Flut an Innovationen reißt nicht ab. Hier sind drei weitere essenzielle Updates, die Sie kennen müssen:
- ByteDance Seed 2.0: Nach dem legendären Video-Generator Seed Dance 2.0 hat ByteDance ein neues Sprachmodell veröffentlicht. In visuellen Reasoning-Benchmarks übertrifft Seed 2.0 selbst die Platzhirsche von OpenAI und Google teilweise. Es ist fähig, autonom über hunderte Schritte hinweg professionelle 3D-CAD-Software zu bedienen – ein massiver Sprung für Agenten-Systeme in der Konstruktion.
- Cohere Tiny AA: Ein Open-Weights-Modell mit nur 3,35 Milliarden Parametern, das speziell für globale Mehrsprachigkeit trainiert wurde. Es unterstützt über 67 Sprachen fehlerfrei und läuft blitzschnell auf handelsüblichen Smartphones.
- Kitten TTS: Ein absurd kleines Text-to-Speech Modell. Das kleinste Derivat hat lediglich 14 Millionen Parameter und wiegt nicht einmal 25 Megabyte. Dennoch liefert es expressive und flüssige Sprachausgabe in Echtzeit, rein auf der CPU berechnet.
- Anchorwave: Eine Open-Source Interactive World Generation KI. Aus einem simplen Startbild generiert das Modell eine begehbare 3D-Welt, durch die man sich per Tastatur wie in einem Videospiel bewegen kann. Durch "Local Geometric Memories" bleibt die Umgebung konsistent, auch wenn man den virtuellen Kopf wegdreht und später zurückschaut.
Fazit: Die exponentielle Kurve der Disruption
Wenn wir die Ereignisse dieser Woche reflektieren, wird eines klar: Die Grenzen zwischen Software, Hardware, physischer Robotik und menschlicher Kognition verschwimmen in atemberaubendem Tempo. Von der Festverdrahtung von Sprachmodellen in Silizium durch den Taalas HC1 über die brillanten multimodalen Fähigkeiten eines Qwen 3.5 und Gemini 3.1 Pro bis hin zu den ersten Gehversuchen im Entschlüsseln unserer Gehirnströme durch ZUNA – wir sind längst über den Punkt der reinen Automatisierung hinaus.
Die Werkzeuge, die heute als Open-Source veröffentlicht werden – sei es für 4K-Videos, Echtzeit-Audio oder Agenten-Steuerung – geben Individuen die kreative Zerstörungskraft ganzer Studios in die Hand. Es war nie eine aufregendere, aber auch anspruchsvollere Zeit, im Technologie-Sektor tätig zu sein.