
Die Welt der Künstlichen Intelligenz bewegt sich längst nicht mehr in Schritten, sondern in exponentiellen Sprüngen. Die vergangenen Tage haben die Branche mit einer beispiellosen Flut an Durchbrüchen erschüttert: Von völlig autonomen Software-Agenten über Modelle, die den Kern der Biowissenschaften revolutionieren, bis hin zu ultrakompakten Sprachmodellen, die auf einem Smartphone mit der Leistung von Rechenzentren konkurrieren. Wir stehen an der Schwelle zu einer Ära, in der KI nicht mehr nur assistiert, sondern eigenständig forscht, programmiert und durch physische sowie virtuelle Welten navigiert. Dieser umfassende Deep Dive analysiert die wegweisendsten technologischen Entwicklungen und ordnet ihre strategische Bedeutung für Entwickler, Forscher und IT-Entscheidungsträger ein.
Foundation Models: Die Evolution der Autonomie und Schlussfolgerung
Der Wettlauf um das fähigste Basismodell hat eine neue Dimension erreicht. Es geht nicht mehr primär um die Anzahl der Parameter, sondern um "Agentic Capabilities" – die Fähigkeit eines Modells, komplexe, mehrstufige Aufgaben über lange Zeiträume hinweg ohne menschliches Eingreifen zu bewältigen.
Claude Opus 4.7: Der neue Maßstab für autonome Workflows
Anthropic hat mit Claude Opus 4.7 ein Modell auf den Markt gebracht, das die Paradigmen der Softwareentwicklung und Systemadministration verschiebt. Während frühere Modelle starkes Mikromanagement und präzise, sequenzielle Prompts erforderten, zeichnet sich Opus 4.7 durch eine bemerkenswerte Unabhängigkeit aus. Entwickler können dem Modell ein hochrangiges Ziel übergeben (z. B. "Analysiere diese Codebasis, finde den Memory Leak, schreibe einen Fix und erstelle die passenden Unit-Tests"), und Opus 4.7 plant und exekutiert den gesamten Workflow autonom.
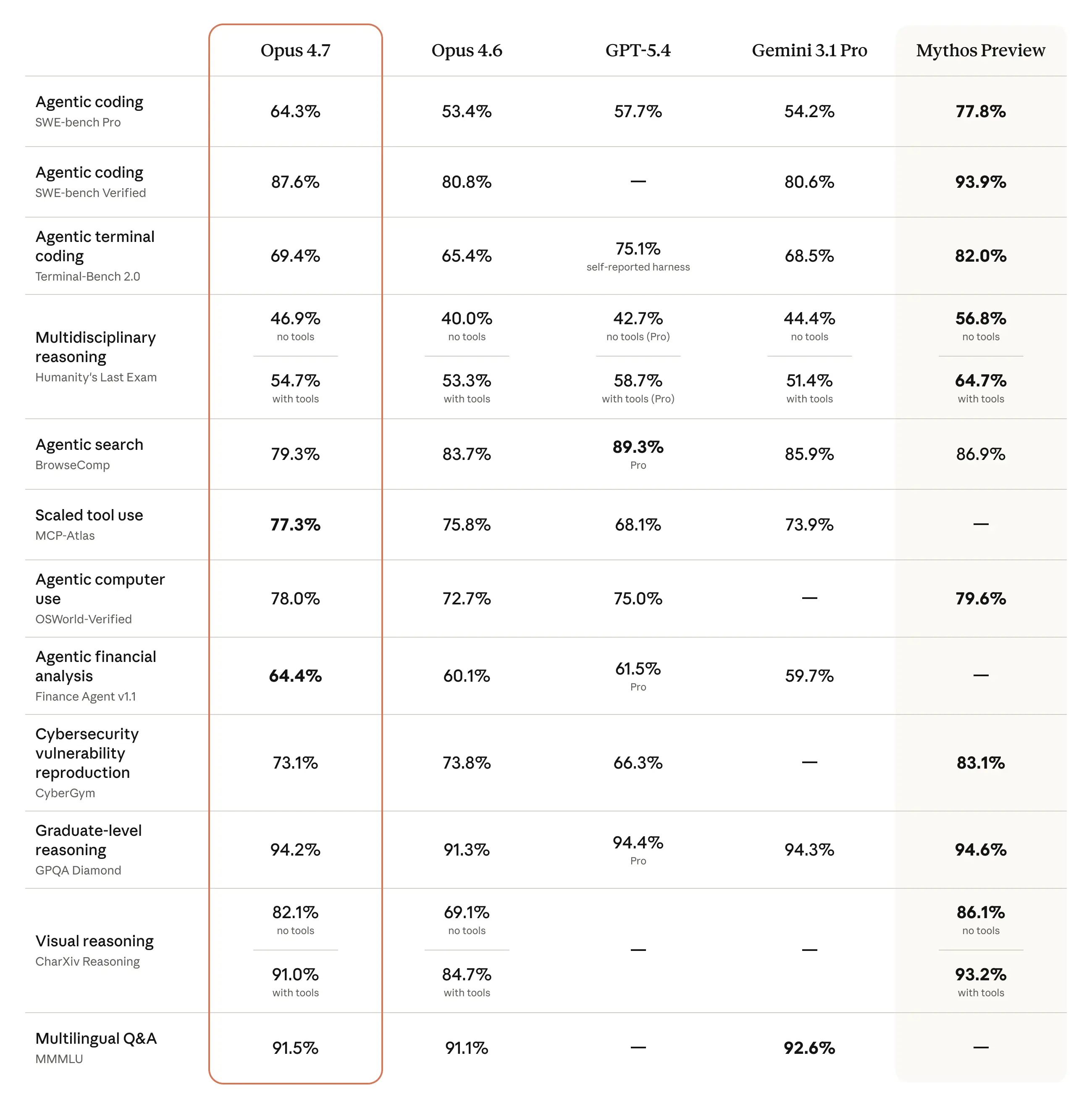
Die Benchmarks sprechen eine deutliche Sprache: In Evaluierungen wie SWE-bench Verified und Terminal-Bench 2.0 zeigt Opus 4.7 erhebliche Leistungssteigerungen gegenüber dem direkten Vorgänger Opus 4.6. Besonders hervorzuheben ist die verbesserte multimodale Verarbeitung. Das Modell kann nun Bilder mit bis zu 2500 Pixeln Kantenlänge verarbeiten – mehr als das Dreifache der vorherigen Generation. Dies ist von entscheidender Bedeutung für Agenten, die Computer-Oberflächen (GUIs) bedienen müssen, da sie Bildschirminhalte präziser analysieren und klickbare Elemente fehlerfrei identifizieren können.
Qwen 3.6 (35B A3B): Mixture of Experts in Perfektion
Parallel zu Anthropic hat Alibaba sein Open-Source-Ökosystem mit Qwen 3.6 35B A3B erweitert. Hinter diesem kryptischen Namen verbirgt sich ein 35-Milliarden-Parameter-Modell, das auf einer Mixture of Experts (MoE) Architektur basiert. Der Clou: Von den 35 Milliarden Parametern sind während der Inferenz nur 3 Milliarden aktiv. Das Modell arbeitet wie ein hochspezialisiertes Expertenteam, bei dem je nach Aufgabenstellung nur die relevanten Sub-Netzwerke konsultiert werden.
In Benchmarks zur automatisierten Code-Generierung und bei mathematischen Argumentationen auf Universitätsniveau schlägt diese kompakte Architektur teils deutlich größere, monolithische Modelle. Die Tatsache, dass Alibaba ein Modell dieser Leistungsklasse vollständig quelloffen auf Hugging Face und ModelScope anbietet, demokratisiert den Zugang zu High-End-Agentensystemen enorm. Entwickler können Qwen 3.6 lokal in Frameworks wie OpenDevin oder Claude Code integrieren und so datenschutzkonforme, autonome Entwicklungsumgebungen aufbauen.
Wissenschaftliche KI: GPT-Rosalind und die Entschlüsselung der Natur
Während allgemeine Chat-Modelle beeindruckend sind, liegt das wahre wirtschaftliche und gesellschaftliche Potenzial der KI in der Beschleunigung wissenschaftlicher Durchbrüche. Die Entwicklung eines neuen Medikaments dauert traditionell 10 bis 15 Jahre und verschlingt Milliarden. OpenAI hat diesen Flaschenhals adressiert und GPT-Rosalind (benannt nach Rosalind Franklin) vorgestellt – ein spezialisiertes Reasoning-Modell für die Life Sciences.
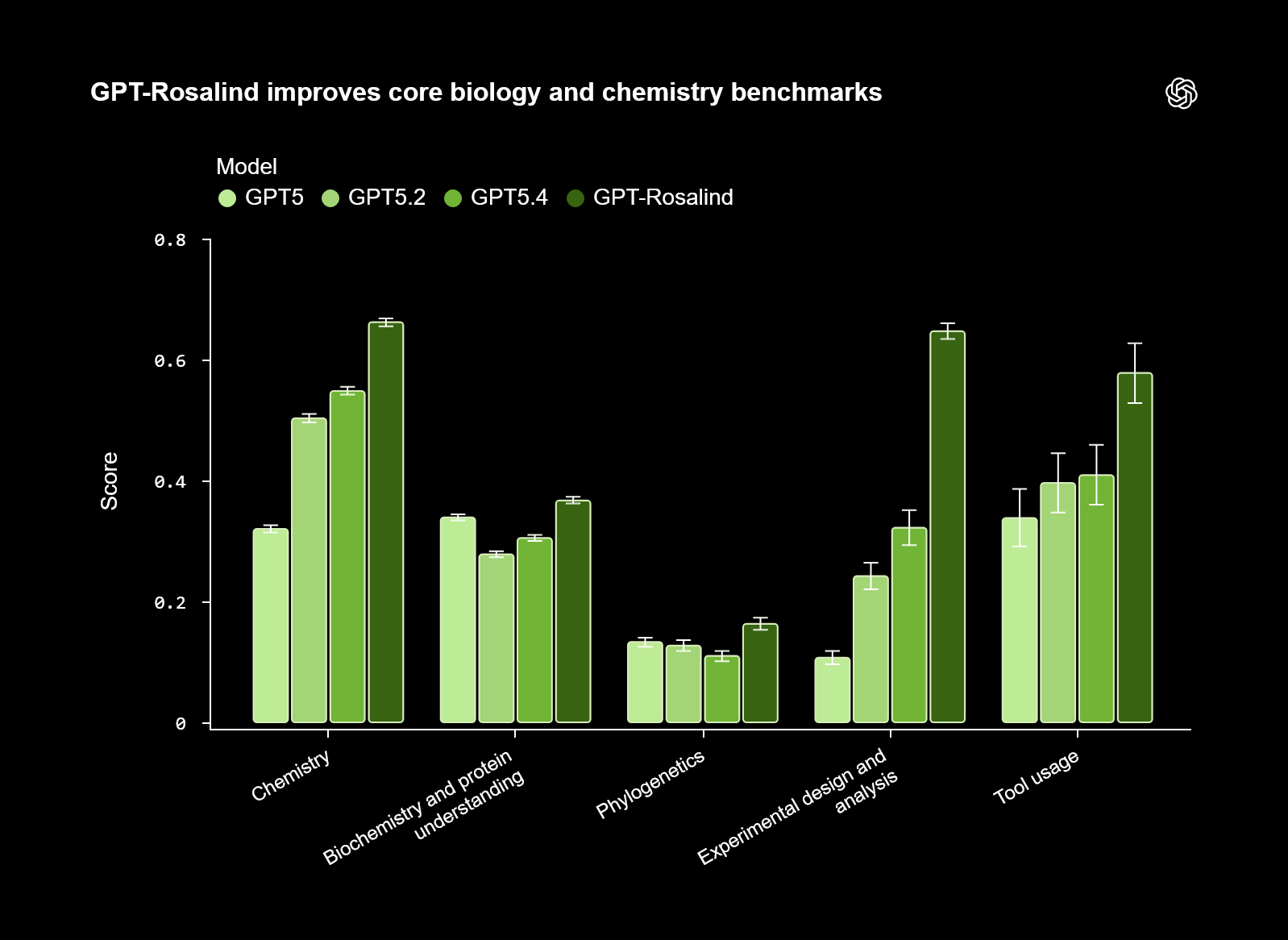
GPT-Rosalind ist kein reiner Textgenerator, sondern eine Forschungs-Engine. Durch ein spezielles Life-Sciences-Plugin für Codex ist das Modell direkt mit über 50 wissenschaftlichen Datenbanken verbunden, darunter Protein-Struktur-Verzeichnisse, Genomsequenz-Datenbanken und globale Literaturverzeichnisse. Wissenschaftler können GPT-Rosalind nutzen, um nahtlos von der reinen Literaturrecherche über das Aufstellen von Hypothesen bis hin zur Planung konkreter experimenteller Setups zu iterieren.
Wie die Evaluierungen zeigen, erzielt Rosalind bei Aufgaben zum experimentellen Design und zur Datenanalyse Scores, die bisher unerreichbar schienen. Die KI liest nicht nur Paper, sie extrahiert Methodiken, vergleicht sie mit Rohdaten und schlägt optimierte Versuchsaufbauten vor. Dies signalisiert einen fundamentalen Wandel: KI wird vom passiven Assistenten zum aktiven Mitforscher im wissenschaftlichen Discovery-Prozess.
Die Effizienz-Revolution: Ternary Bonsai und das Ende der Memory-Wall
Eine der massivsten Herausforderungen der modernen KI ist der gigantische Speicher- und Rechenbedarf. Große Sprachmodelle (LLMs) sind durch die Speicherbandbreite (Memory Wall) limitiert. Ein traditionelles Modell speichert jeden Parameter als 16-Bit-Gleitkommazahl. Hier setzt eine völlig neue Modellfamilie an, die den Markt aktuell aufmischt: Ternary Bonsai.
Diese Modelle nutzen eine extreme Form der Quantisierung, die sogenannte 1,58-Bit-Architektur. Dabei wird jeder Parameter (das "Gewicht" der neuronalen Verbindungen) auf exakt drei mögliche Werte reduziert: -1, 0 oder 1. Diese triviale Repräsentation wird durch einen globalen Skalierungsfaktor angepasst. Das Ergebnis ist schier unglaublich: Matrixmultiplikationen, die rechenintensivsten Operationen in neuronalen Netzen, werden zu simplen Additions- und Subtraktionsaufgaben degradiert.
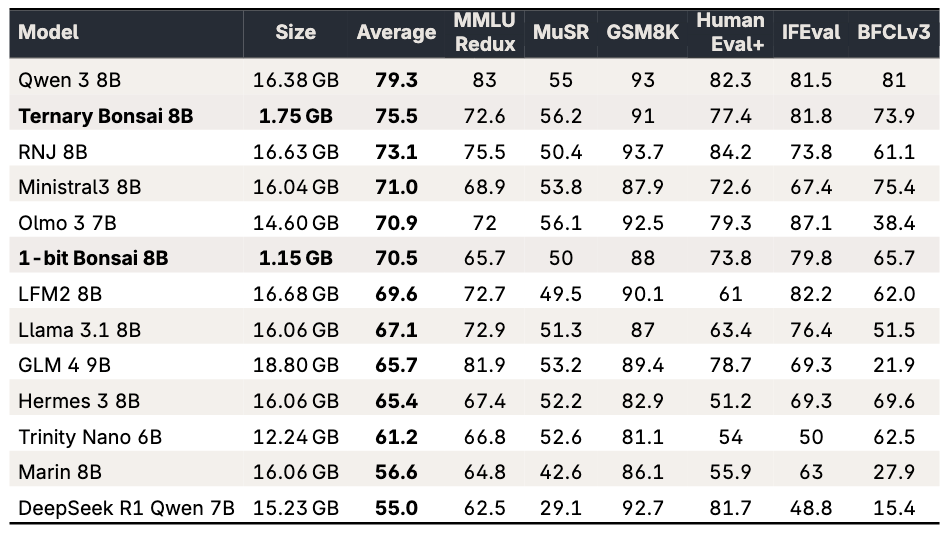
Maximale Leistung bei minimalem Footprint
Die 8-Milliarden-Parameter-Variante (8B) der Ternary Bonsai Familie ist lediglich 1,75 Gigabyte groß. Das ist fast zehnmal kleiner als vergleichbare 16-Bit-Modelle wie Llama 3.1 8B oder Qwen 3 8B. Doch der wahre Triumph zeigt sich im Performance-Vergleich: Trotz der drastischen Kompression übertrifft das Bonsai-Modell seine ressourcenhungrigen Konkurrenten in vielen Standard-Benchmarks für logisches Denken und Programmieren.
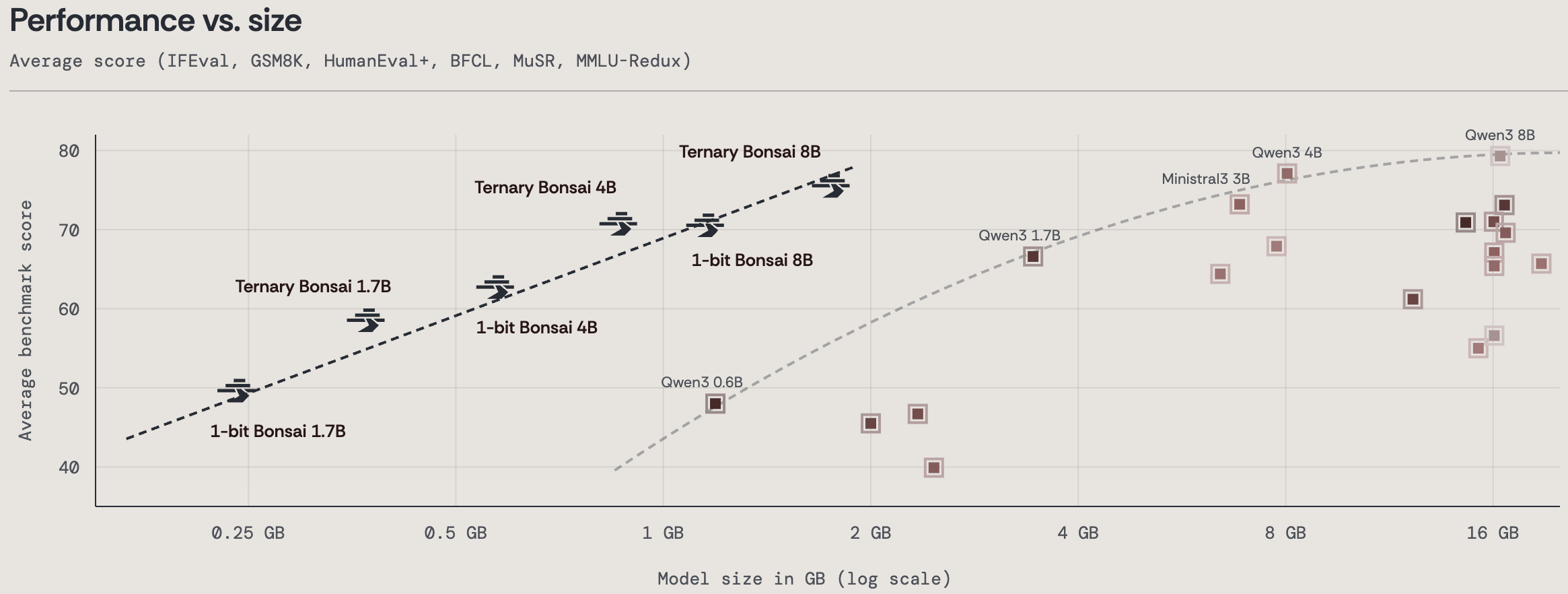
Die Auswirkungen auf das Hardware-Ökosystem sind gewaltig. Anstatt teure Nvidia H100 Cluster für die Inferenz anzumieten, können diese hochintelligenten Modelle lokal ausgeführt werden – und zwar mit rasender Geschwindigkeit.
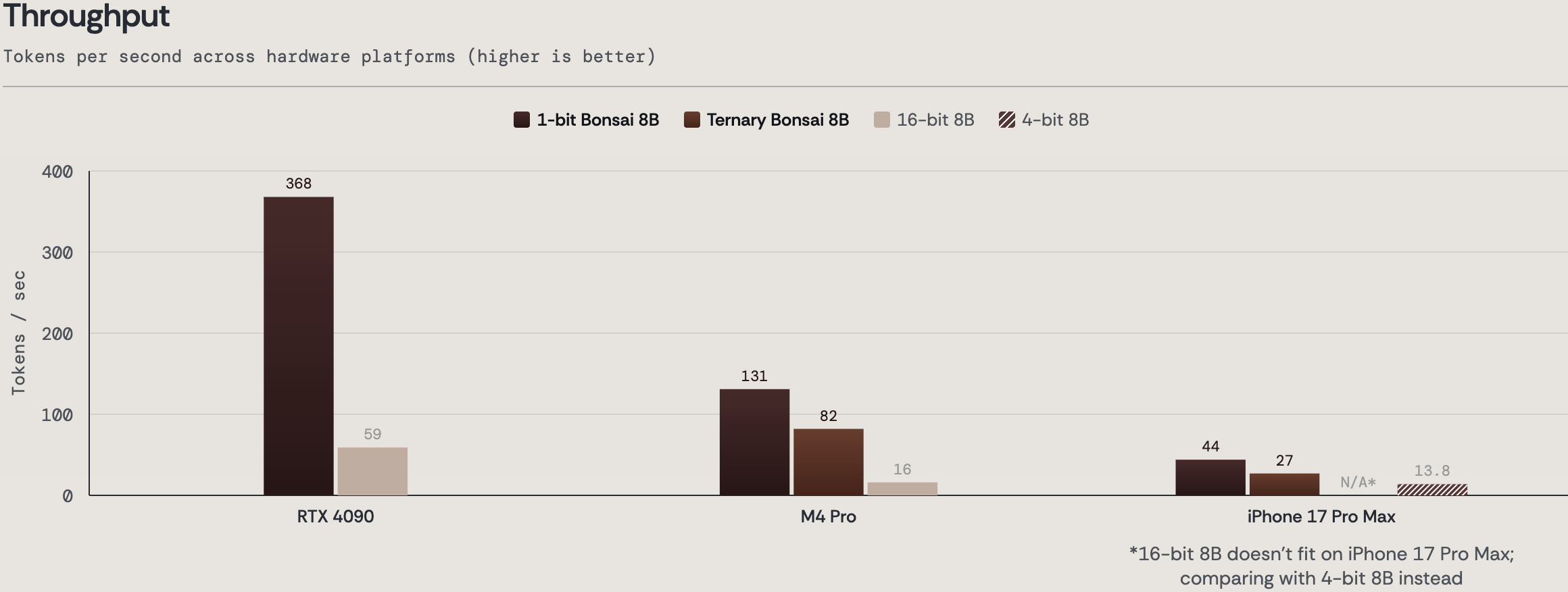
Auf einer handelsüblichen RTX 4090 erreicht das Modell fast 370 Token pro Sekunde. Selbst auf mobilen Endgeräten wie einem Apple M4 Pro (131 Token/s) oder einem iPhone 17 Pro Max (44 Token/s) läuft es nativ, lokal und völlig ohne Cloud-Latenz. Dies öffnet Tür und Tor für Edge-AI-Anwendungen, bei denen Datenschutz, Offline-Verfügbarkeit und Batterielaufzeit kritisch sind.
Synthetische Medien & Content-Generierung der nächsten Generation
Während sich die Text-KI in Richtung Autonomie entwickelt, erleben wir im visuellen Bereich eine Explosion an Steuerbarkeit und Konsistenz. Die Ära der unkontrollierbaren generativen Videos ist vorbei. Moderne Modelle bieten präzise, frame-genaue Kontrolle über Identitäten, Produkte und Bewegungen.
OmniShow: Die Fabrik für digitale Influencer
ByteDance hat mit OmniShow ein Werkzeug vorgestellt, das die Marketing- und E-Commerce-Welt auf den Kopf stellen wird. OmniShow ist darauf trainiert, nutzergenerierte Inhalte (UGC) und Produktpräsentationen vollständig synthetisch, aber hyperrealistisch zu erzeugen.

Der Workflow ist revolutionär einfach: Man speist ein Referenzbild eines realen Influencers (oder eines KI-generierten Models) und ein hochauflösendes Bild eines Produkts (z. B. einer Parfümflasche oder eines Nahrungsergänzungsmittels) in das System ein. Im Gegensatz zu älteren Modellen, bei denen Produkte im Video morphen oder Gesichter sich verzerren, hält OmniShow die Details von Produkt und Gesicht absolut konsistent.

Darüber hinaus akzeptiert OmniShow Pose Skeletons – detaillierte 3D-Kabelgerüste, die exakt vorschreiben, wie die Person ihre Hände bewegen oder den Kopf neigen soll. Kombiniert man dies mit geklontem Audio, kann ein Content Creator theoretisch hunderte von personalisierten Werbevideos für verschiedene Produkte generieren, ohne jemals eine Kamera aufzustellen.
Effizienz in der Video-Generierung: Motif Video 2B & Prompt Relay
Neben ByteDance treiben auch andere Akteure die visuelle KI voran. Motif Video 2B ist ein beeindruckendes Beispiel dafür, dass man keine massiven Rechenzentren braucht, um High-End-Videos zu generieren. Als 2-Milliarden-Parameter Diffusion-Transformer wurde es mit weniger als 10 Millionen Videos und unter 100.000 GPU-Stunden trainiert. Trotz dieses geringen Ressourcenaufwands erreicht es eine visuelle Qualität, die mit Modellen konkurriert, die das Siebenfache an Größe und das Zehnfache an Trainingsdaten erforderten.
Gleichzeitig löst die neue Technik Prompt Relay (ein Plug-and-Play Add-on für Alibaba's Wan-Architektur) eines der größten Probleme in der KI-Regie: Sanfte, nahtlose Szenenübergänge. Anstatt dass eine Szene abrupt in eine andere überschneidet oder Bildelemente unnatürlich verschmelzen ("Bleeding"), steuert Prompt Relay die Cross-Attention-Layer des Modells so, dass Prompts an exakten Zeitstempeln weich ineinandergreifen – wie die Übergabe des Staffelstabs bei einem Staffellauf. Ein Adlerflug am Himmel kann so fließend und ohne Artefakte in eine Kamerafahrt durch eine Cyberpunk-Stadt übergehen.
Interaktive 3D-Welten und Gaming-Benchmarks
Das nächste große Paradigma nach Bild- und Video-Generierung ist die Generierung von interaktiven Welten. Wir bewegen uns von konsumierbaren Medien (Videos) hin zu navigierbaren Simulationen (Spiele, Metaverse-Umgebungen, Robotik-Trainingsgelände).
Happy Oyster & HY World 2.0: Generative Universen
Alibabas ATH Lab hat mit Happy Oyster einen direkten Konkurrenten zu Googles Genie 3 vorgestellt. Das System generiert aus Textprompts offene, interaktive 3D-Welten in Echtzeit. Anstatt Level per Hand in einer Game-Engine zu bauen, wird die Physik und die visuelle Umgebung on-the-fly von einem neuronalen Netz inferiert. Nutzer können Charaktere steuern, auf Pferden reiten oder durch offene Landschaften gleiten – alles generiert im Moment der Eingabe.
Tencent geht mit HY World 2.0 noch einen Schritt weiter. Dieses multimodale Welt-Modell nimmt nicht nur Text, sondern auch Einzelbilder oder Videos als Input und rekonstruiert daraus eine vollständige, interaktive 3D-Umgebung. Der immense Vorteil: HY World 2.0 gibt industriestandardisierte Formate aus (Meshes, 3D Gaussian Splats, Punktwolken). Diese Pipelines sind bereit für den Export in Unity oder Unreal Engine, was den Workflow für Game-Designer und VFX-Künstler drastisch verkürzt.
GameWorld Benchmark: Der Härtetest für visuelle Agenten
Während KI-Modelle in akademischen Tests glänzen, scheitern sie oft in der physischen oder simulierten Echtzeit-Realität. Hier setzt der GameWorld Benchmark an.
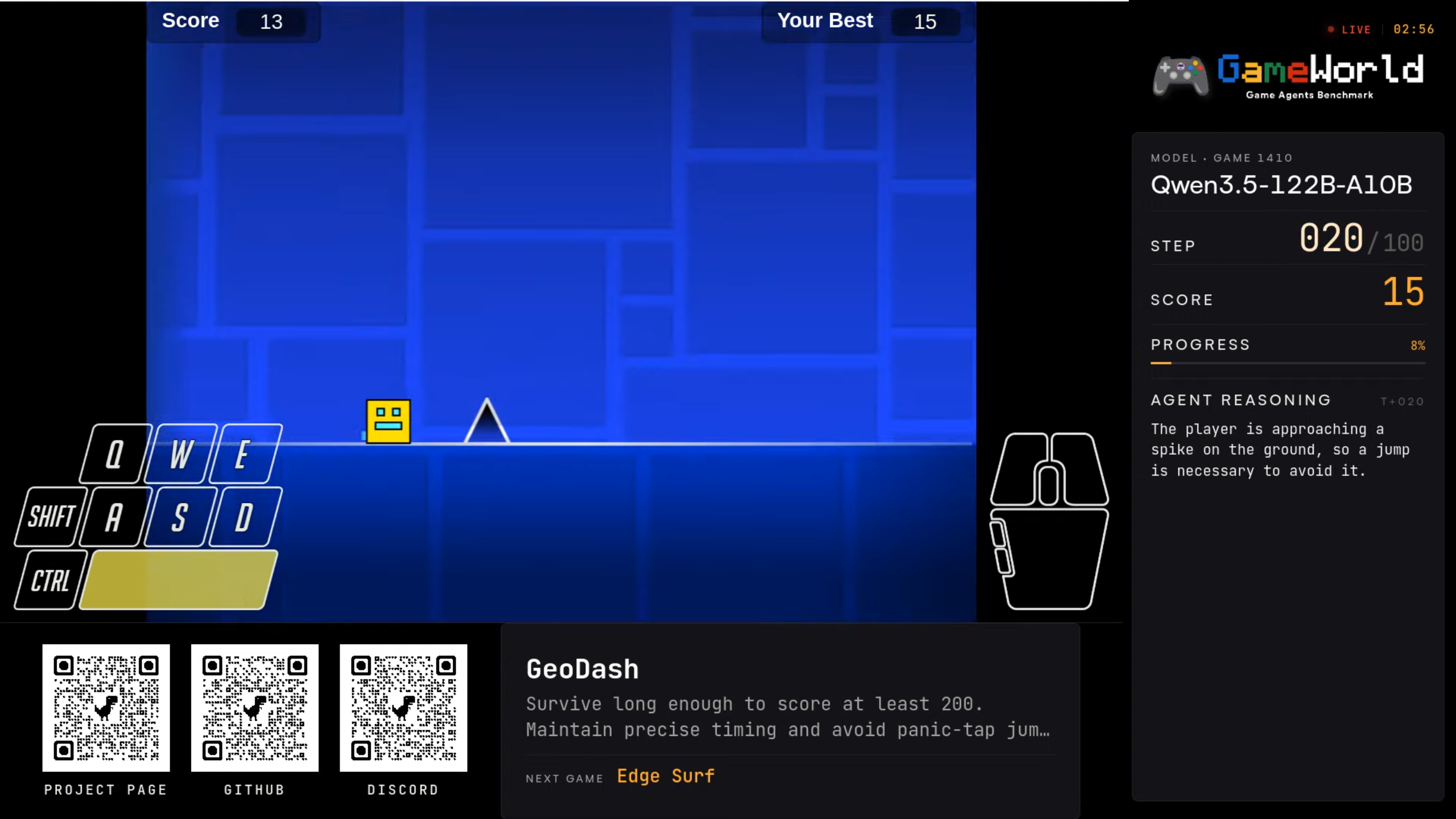
GameWorld evaluiert autonome Agenten anhand ihrer Fähigkeit, browserbasierte Spiele aus Genres wie Jump-'n'-Run, Puzzle oder Simulation zu spielen. Modelle müssen Bildschirme analysieren, räumliche Zusammenhänge verstehen, das richtige Timing finden und Keyboard-/Maus-Inputs generieren. Aktuell führen Modelle wie Claude 3.5 Sonnet und Gemini in der Agentic-Computer-Use-Kategorie das Feld an. Dennoch liegen selbst diese Spitzenreiter mit Erfolgsraten von knapp über 30 % noch deutlich unter der menschlichen "Novice-Baseline" von 64 %. Spiele stellen für KI eine der härtesten Herausforderungen dar, weil Fehler sofort bestraft werden und ein langfristiges Planungsvermögen zwingend erforderlich ist.
Physische KI: Die Robotik-Invasion beginnt
Die Software verlässt zunehmend den Bildschirm und betritt die physische Welt. Die Entwicklungen in der humanoiden Robotik verlaufen parallel zu den Durchbrüchen bei den KI-Foundation-Modellen, da diese Modelle nun als das "Gehirn" der Hardware dienen können.
Der Sprint in eine neue Ära
Unitree hat mit seinem Flaggschiff, dem H1 Humanoid Robot, einen neuen Weltrekord aufgestellt. Der Roboter sprintet mit unglaublichen 10 Metern pro Sekunde (36 km/h). Diese hochfrequente Stabilität und fließende Ganzkörperkontrolle bei einem 62 Kilogramm schweren Metallchassis zeigen, wie weit die fortgeschrittene Bewegungssteuerung (Dynamic Motion Control) fortgeschritten ist.
Ein weiteres Indiz für die Reife der Branche war der zweite Roboter-Marathon in Peking. Während im Vorjahr noch viele tollpatschige, taumelnde Prototypen das Feld prägten, traten in diesem Jahr über 70 Teams an. Das Beeindruckendste: Rund 40 % der Roboter absolvierten den Lauf vollständig autonom – ohne Fernsteuerung, gestützt rein auf ihre internen Kamerasensoren und lokalen neuronalen Netze zur Navigation.
Massenproduktion: Der iPhone-Moment der Robotik?
Die vielleicht wirtschaftlich relevanteste Nachricht der Woche stammt von Leju Robotics. Das Unternehmen hat in Foshan, Provinz Guangdong, die weltweit erste vollautomatisierte Produktionslinie für humanoide Roboter in Betrieb genommen.
In dieser Anlage greifen Industrieroboterarme und fahrerlose Transportsysteme nahtlos ineinander, um Torso, Gliedmaßen und Köpfe der humanoiden Roboter zu montieren. Mit 24 digitalen Montagestationen und 77 automatisierten Qualitätsprüfungen ist der Prozess zu 92 % automatisiert. Der Ausstoß: Ein fertiger humanoider Roboter alle 30 Minuten. Das entspricht einer Kapazität von über 10.000 Einheiten pro Jahr. Wenn humanoide Roboter nicht mehr in Manufakturen zusammengeschraubt, sondern am Fließband massenproduziert werden, fallen die Stückkosten ins Bodenlose. Dies könnte der Katalysator sein, der menschenähnliche Roboter in Fabriken, Lagerhallen und bald auch in unsere Haushalte bringt.
Werkzeuge für Kreative: Von Stimme bis Licht
Abschließend werfen wir einen Blick auf Tools, die den Alltag von Kreativschaffenden und Designern verändern werden.
Google Gemini 3.1 Flash Text-to-Speech (TTS)
Googles neuester Wurf im Bereich Audio-Generierung bringt eine beispiellose Expressivität in die Sprachsynthese. Entwickler und Creator können den Text-Input nun mit Meta-Tags versehen, die Emotionen auf mikroskopischer Ebene steuern. Tags wie [whispers], [panicked], [laughs] oder [sighs] verändern nicht nur die Tonhöhe, sondern die gesamte Kadenz, das Atmen und die Resonanz der KI-Stimme. Eine Zeile aus Shakespeare kann von einer neutralen akademischen Vorlesung fließend in die panische, zittrige Stimme eines Geächteten verwandelt werden. Mit Unterstützung für über 70 Sprachen und präziser Kontrolle über Pausen (Pacing) übertrifft dieses System derzeit sogar spezialisierte Konkurrenten wie ElevenLabs.
Adobe Token Relight
Fotografen und 3D-Künstler kennen den Schmerz: Ein perfektes Foto, aber das Licht stimmt nicht. Adobes neue KI Token Relight löst dieses Problem durch ein tiefes, inhärentes Verständnis von 3D-Geometrie auf Basis von 2D-Bildern. Das Tool erlaubt es, in einem flachen Foto nachträglich dreidimensionale Lichtquellen zu platzieren. Man kann Lichtintensität, Farbe, Umgebungslicht (Ambient) und die Härte der Schatten (Diffuse) stufenlos über Slider steuern.
Das Transformer-Modell berechnet in Echtzeit, wie Licht mit Hauttexturen, Kleidung und Objektverdeckungen (Occlusion) interagiert, und wirft physikalisch korrekte Schatten, selbst für komplexe Szenen. Eine Meisterleistung der Generativen KI, die traditionelle Maskierungs- und Retusche-Techniken obsolet machen könnte.
Fazit: Die Konvergenz der Disziplinen
Wenn wir die Entwicklungen betrachten, wird ein übergeordnetes Muster erkennbar: Die Konvergenz. Sprachmodelle (wie Opus 4.7 oder Qwen 3.6) stellen die kognitive Architektur. Effizienz-Algorithmen (wie Ternary Bonsai) machen diese Architektur dezentral und lokal verfügbar. Synthetische Daten-Engines (Happy Oyster, OmniShow) erschaffen endlose, sichere Trainingswelten für diese Modelle. Und schließlich verleiht die Robotik (Unitree, Leju) diesen KI-Gehirnen einen physischen Körper, um in unserer Welt zu handeln.
Für Unternehmen, Entwickler und Forscher bedeutet dies: Das Abwarten auf "reife" Versionen ist riskant. Die Werkzeuge, um autonome Agenten zu bauen, Edge-AI-Lösungen zu skalieren oder in der Biotech-Forschung Quantensprünge zu erzielen, liegen heute als Open Source auf Plattformen wie GitHub und Hugging Face bereit. Wer die zugrundeliegende Mechanik – von der 1,58-Bit-Quantisierung bis hin zu Agentic Reasoning Workflows – heute versteht und adaptiert, wird die Standards von morgen definieren.
Die technologische Singularität ist vielleicht noch nicht erreicht, aber die Geschwindigkeit, mit der autonome KI in alle Facetten der Forschung, Entwicklung und physischen Produktion vordringt, beweist: Wir befinden uns mitten in der steilsten technologischen Skalierungsphase der menschlichen Geschichte.
Basierend auf den Analysen branchenweiter Entwicklungen (Referenz)
 ZS Studio - Ihr Partner für erstklassige Webentwicklung
ZS Studio - Ihr Partner für erstklassige WebentwicklungIn einer digitalen Welt, die sich ständig weiterentwickelt, ist eine leistungsstarke und skalierbare Website das Fundament Ihres Unternehmenserfolgs. Wir unterstützen Unternehmen dabei, technologische Hürden zu überwinden und digitale Erlebnisse zu schaffen, die sowohl technisch als auch strategisch überzeugen.
Suchen Sie nach einem erfahrenen Partner für Ihr nächstes Web-Projekt? Erfahren Sie mehr über unsere Leistungen auf unserer Unternehmenswebsite oder vereinbaren Sie direkt ein unverbindliches Erstgespräch für eine kostenlose Website-Analyse über unser Kontaktformular.
Lassen Sie uns gemeinsam Ihre digitale Präsenz auf das nächste Level heben.